zanim dowiesz się, jak działa H. O. g, daj nam znać, jakie są gradienty w tym kontekście. Weźmy na przykład następujący obraz:
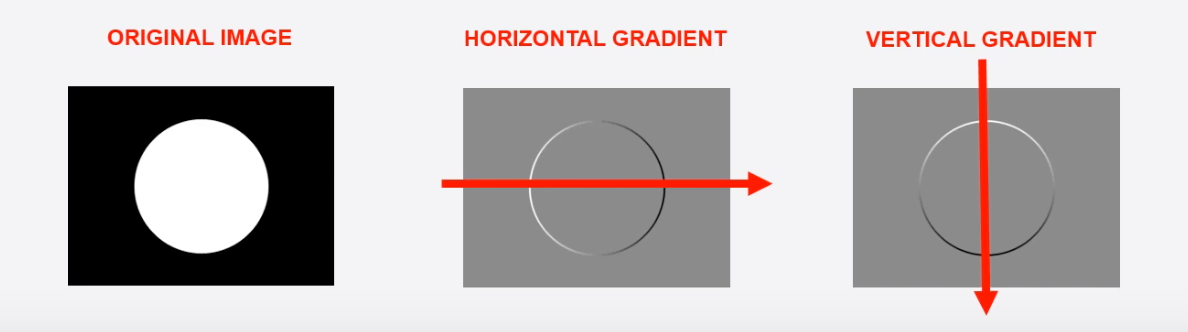
przechodząc od lewej do prawej piksel po pikselu, zauważysz, że po kilku krokach następuje nagła zmiana wartości piksela, tj. z czarnej niższej liczby pikseli na białą wyższą liczbę pikseli. Ta nagła zmiana koloru nazywana jest gradientem, a przejście od ciemniejszego do jaśniejszego tonu nazywa się gradientem dodatnim i odwrotnie. Przejście od lewej do prawej daje gradient poziomy i zgodnie z oczekiwaniami przejście od góry do dołu daje gradient pionowy.
jak działa H. O. G
wieprz działa z czymś, co nazywa się blokiem, który jest podobny do przesuwanego okna. Blok jest uważany za siatkę pikseli, w której gradienty są tworzone od wielkości i kierunku zmiany intensywności piksela w bloku.

rzeczy do zapamiętania: HOG działa na obrazach w skali szarości.
1 — Pierwszym krokiem byłoby przekonwertowanie obrazu RGB na skalę szarości.



2 — aby przyjrzeć się bliżej, skupmy się na jednej takiej siatce o rozmiarze 8*8. Spójrz na poniższy obrazek.

w bloku 64 pikseli dla każdego piksela obliczane są gradienty poziome i pionowe. Podobnie jak na powyższym rysunku, gradienty poziome i pionowe są obliczane jako:
Gradient poziomy: 120 -70 = 50
Gradient pionowy : 100 -50 = 50
3 — gdy uzyskamy gradienty, próbujemy obliczyć coś, co nazywa się wielkością gradientu i kątem gradientu dla każdego z 64 pikseli.

teraz z tymi 64 gradientowymi wektorami, próbujemy skompresować je do 9 wektorów, starając się zachować maksymalną strukturę. Aby to zrobić, staramy się narysować histogram wielkości i kątów. Tutaj oś x to kąty i są one umieszczone w 9 pojemnikach o wielkości 20 stopni.
Uwaga: o utworzeniu 9 pojemników decydują autorzy artykułu. Więc jest praktycznie wszędzie.

powyższe wyniki są dla jednej siatki 8*8 i skompresowaliśmy reprezentację do 9 wektorów.
4 – gdy przesuniemy tę siatkę 8*8 wzdłuż całego obrazu i spróbujemy zinterpretować wyniki histogramu, otrzymamy coś takiego jak poniżej.

5 — i wykreślając cechy Wieprza, przekonamy się, że struktura obiektu lub twarzy jest dobrze utrzymana, tracąc wszystkie nieistotne cechy.

i takie dane wejściowe mogą być wykorzystane przez dowolny algorytm uczenia maszynowego do klasyfikacji lub regresji.
jest to bardzo potężna technika stosowana do dziś i wykrywanie obiektów można osiągnąć bez użycia ciężkich architektur z DL.
najlepszym miejscem do uzyskania funkcji wykrywania Wieprza jest biblioteka Dlib.
teraz, gdy znasz stare, poręczne narzędzie do reprezentowania obrazu w skompresowanym formacie i nadal zachowuje jego strukturę, możesz włączyć to w wielu przypadkach widzenia komputerowego.