Introduction
あなたは熱心なゴルファーであり、新しいショットを学びたいと思っています。 どのように進めますか? あなたが誰かを観察する公正なチャンスがあります(ライブ、ビデオ、Youtubeなど)。)誰がこのショットを実行する方法を知っている、とあなたは何をすべきか、それを行う方法を理解しようとします。 研究は、観察が多種多様な運動能力の学習を促進することが示されているため、この学習戦略が成功していることを明確に示している(McCullagh et al. ら、1 9 8 9;Hodges e t a l. ら、2 0 0 7;VogtおよびThomaschke、2 0 0 7;Ste−Marieら、2 0 0 7;Stre−Marieら、2 0 0 8)。 ら、2 0 1 2;Lago−Rodríguez et al.,2014,観察学習に関するレビューのために). これは、観察は運動能力学習の最初の決定要因である物理的練習と多くの共通性を持っているためです。 具体的には、練習量などの変数が実証されている(Carroll and Bandura、1990; Blandin、1994)、結果の知識の頻度(、Badets and Blandin、2004、2005;Badets et al。 2006年)、および練習スケジュール(Blandin et al. ら、1 9 9 4;Wright e t a l.,1997),同様の方法で観察練習と物理的な練習を介して学習に影響を与えます. これらのデータは、観察と物理的練習が非常に類似したプロセスを使用するという命題につながった。 この提案は、神経構造の集団(運動前皮質、下頭頂小葉、上側頭溝、補助運動領域、帯状回、および小脳を含む)が、”行動観察ネットワーク”(Aon)とも呼ばれることを示した神経イメージング研究の結果によって支持されている(Kilner et al. ら,2 0 0 9;Oosterhofら,2 0 0 9;Oosterhofら, ら、2010)は、個人が与えられた運動タスクを実行するときと、同じ運動タスクを実行する他の人を観察するときの両方で活性化される(Grafton et al. ら、1 9 9 7;Buccino e t a l. ら,2 0 0 1;Gallese e t a l.,2002;CisekとKalaska,2004; Frey and Gerry,2 0 0 6;Cross e t a l. ら、2 0 0 9;DushanovaおよびDonoghue、2 0 1 0;RizzolattiおよびFogassi、2 0 1 4;Rizzolattiら、2 0 0 9;DushanovaおよびDonoghue、, 2014).
観察は運動能力の学習を支持しますが、その新しいゴルフショットを学ぶために誰を観察すべきですか? ショットをマスターする専門家は、おそらくあなたが何をすべきか、どのようにそれを行うための参照を開発するのに役立ちますが、あなたはそのショットを学んでいるあなたのような誰かを観察し、誰がおそらくあなたにエラーや戦略の変化から検出し、学習のより良いチャンスを与える必要がありますか? 研究は、熟練したモデルの両方を観察することを示している(Martens et al., 1976; McCullagh et al. ら、1 9 8 9;Leeら、1 9 8 9;Mol. ら、1 9 9 4;A L−Abood e t a l. ら、2 0 0 1;Heyes and Foster、2 0 0 2;Hodges e t a l. Bord and H Yes,2 0 0 5)および初心者モデルは有意な学習を導く(Lee and White,1 9 9 0;Mccullagh and Caird,1 9 9 0;Pollock and Lee,1 9 9 2;Mccullagh and Meyer,1 9 9 7;Black and Wright,2 0 0 0;Buchanan e t a l. ら、2 0 0 8;Buchanan and Dean,2 0 1 0;Hayes e t a l., 2010). しかし、私たちの研究室の最近の結果は、初心者や専門家のモデルだけではなく、初心者と専門家の両方のモデルを観察した後、新しい運動技能の観察学習が改善されることを示した(Rohbanfard and Proteau、2011;Andrieux and Proteau、2013、2014)。 この”可変”観測形式は、良好な動き表現(専門家の観察)の開発だけでなく、誤り検出と訂正のための効率的なプロセス(初心者の観察)の開発にもつながると
本研究では、関心のある問題は単純だが重要な問題である。 可変観測スケジュールを使用する場合、オブザーバーが見ようとしているパフォーマンスの”質”を事前に知らされているときに学習が良くなるか、フィードバックを受ける前にオブザーバーがパフォーマンスを評価するために残されているときに学習が良くなるでしょう。 観察者に何を見ようとしているかを知らせることで、観察を模倣するか、むしろ観察してエラーを検出するか、モデルの性能の弱点を検出するかを選択することができ、これらのプロセスの開発を容易にする可能性がある。 あるいは、参加者が観察したパフォーマンスの質を評価することは、この情報が前方に供給されるときよりも精巧な認知プロセスを活性化させる(例:エラー検出と認識、または代替戦略の評価)ことができ、その結果、タスクのより良い学習が得られる。
私たちが選んだタスクは、参加者にタスクの制約から自然に現れた相対的なタイミングパターンを変更する必要がありました(Collier and Wright,1995;Blandin et al.,1999)相対的なタイミングの新しい、課されたパターンに. これは、テニスでサーブを実行するときやゴルフでドライブするときのテンポを変えることに似ています(Rohbanfard and Proteau、2011)。 参加者は、様々なパフォーマンスを示す二つのモデルを観察しました。 一つのグループでは、オブザーバーは、彼らが見ようとしていたものの品質レベル(専門家、上級、中級、初心者、または初心者のパフォーマンス)の各試験の前に知
実験1
メソッド
参加者
モントリオール大学のdépartement de kinésiologieの90人の右利きの学生(男性45人、女性45人、平均年齢=20.5歳、SD=0.9歳)がこの実験に参加しました。 参加者は研究の目的に素朴であり、タスクの経験はなく、すべての参加者は右利きであると自己宣言されました。 参加者のいずれも神経学的障害を報告せず、すべてが正常または正常に矯正された視力を有していた。 参加者は、参加前に個々の同意書に記入し、署名しました。 モントリオール大学の健康科学研究倫理委員会は、この実験を承認しました。
装置とタスク
装置は、RohbanfardとProteau(2011)によって使用されたものと同様でした。 図1に示すように、それは木製のベース(45×54cm)、三つの木製の障壁(11×8cm)、およびターゲット(11×8cm)に埋め込まれた開始ボタンで構成されていました。 開始ボタンと最初の障壁との間の距離は15cmであった。 タスクの残りの三つのセグメントの距離は、それぞれ32、18、および29cmでした。 障壁は、各試行の開始時に木製のベースに垂直に配置され、閉鎖されたマイクロスイッチ回路が得られた。 すべてのマイクロスイッチは、A–Dコンバータ(National Instruments、Austin、Texas、USA)のI/Oポートを介してコンピュータに接続され、ミリ秒タイマーを使用して、合計移動時間(TMT)とタス
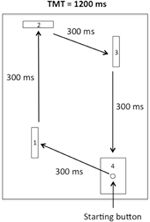
図1. 装置のスケッチ。 参加者は、開始ボタンを残して、最終的に目標に到達する前に時計回りの動きで第一、第二、第三の障壁をヒットしなければならなかった。
物理的な練習の試験(下記参照)のために、参加者は装置の前の開始位置の近くに座っていました。 次に、スタートボタンから、参加者は、第一、第二、および第三の障壁を連続的にノックダウンし(したがって、マイクロスイッチを解放する)、図1に示すように、最終的に時計回りの動きで目標を打つように求められた。 タスクの各セグメントは、300msのITで完了し、TMTは1200msで完了する必要がありました。 運動パターン,ItsおよびTMTは,すべての実験段階の間に装置の正面に位置するポスターに示された。
実験段階と手順
参加者は、コントロール(C)、フィードフォワードKRと観察(FW)、および観察とフィードバックKR(FB)の30人の参加者(グループあたり15人の女性)で構成される3つのグループのいずれかに無作為に割り当てられた。 すべてのグループは、2日間連続して広がった四つの実験段階を行った。
すべての参加者は、最初の実験段階の前にTMTとITsに関する口頭での指示を受けました。 最初の実験段階は、すべての参加者がTMTとITsの結果(KR)の知識なしに20の物理的な練習試験を行ったプレテストでした。
第二段階は獲得段階であり、二つの観察グループ(FWとFB)の参加者のための60の観察試験で構成されていました。 これらの参加者は、実験作業を物理的に実行する二つのモデルのビデオプレゼンテーションを個別に見ました。 各観測試験について、FWグループのデモンストレーション前またはFBグループのデモンストレーション後に、モデルの性能に関するKR(TMTとITsの両方)をmsで提示した(図1参照)。 モデルは、5回の試行ごとに変更され(すなわち、モデル1:試行1〜5およびモデル2:試行6〜10など)、1つのモデルで実行された合計30回の試行と、他のモデ FWグループとFBグループの両方で、私たちの研究室から以前の作品に参加した二つのモデルが選ばれました。 したがって、FWおよびFBグループの参加者は、特定のモデルをより良いパフォーマンスまたはより悪いパフォーマンスのいずれかに関連付けることがで エキスパートのパフォーマンスは、0~15msの範囲の二乗平均平方根誤差(RMSE;計算の詳細についてはデータ解析のセクションを参照)に対応していました; 上級、中級、初心者、および初心者のパフォーマンスは、それぞれ30-45ミリ秒、60-75ミリ秒、90-105ミリ秒および120+ミリ秒のRmseに対応していました。 FWグループとFBグループの参加者には、msでのモデルのパフォーマンスが知らされ、それが言及したパフォーマンスのレベルも知らされました。 得られた各モデルの30回の試行(5つのレベルの性能×6回の繰り返し)を無作為化し、5つのレベルの性能を5つの試行の各セットに1回提示した。 観測過程を妨げる可能性のあるシーケンスの物理的な模倣を避けるために、FWグループとFBグループの参加者に、獲得フェーズ中に太ももに手をつけ、モデルを見ている間に動きを再現しないように依頼しました。 参加者がこれらの指示に従っていることを確認することは、実験者の主な仕事でした。 参加者のあからさまな行動は、彼らがしたことを示唆しています。 最後に、対照群の参加者は、この段階で何かを物理的に練習したり観察したりしませんでした。 代わりに、彼らは他のグループの観察と同じ期間(約10分)に提供された新聞や雑誌を読んだ。
第三および第四の実験相は、10分および24時間の保持相であった。 各フェーズでは、すべての参加者がKRなしで20回の試験を物理的に実施しました。
データ分析
試験前および2つの保持フェーズのデータを5つの試験のブロックに再編成しました。
データ分析
データ分析
データ分析
データ分析
データ分析
データ分析
データ分析 5回の試行の連続するブロックごとに(すなわち、.、試験1-5、6-10、等。各参加者の定数誤差の絶対値(/CE/,定数誤差は参加者が総移動時間をアンダーショットまたはオーバーショットするかどうかを示す)と総移動時間の可変誤差(V Eまたは参加者内変動性)を計算して,それぞれTMTの精度と一貫性を決定した。 中間時間については、各参加者が単一のスコアで規定された相対的なタイミングパターンからどれだけ逸脱したかを示すRMSEを計算しました。 各試行について、
ここで、ITiはセグメント”i”の中間時間を表し、targetはタスクの各セグメントの目標移動時間(すなわち、300ms)を表す。
データが正規分布していなかったため(RMSEと時間データは正の歪曲されている)、各従属変数は対数変換(ln)を受けました。 各従属変数の変換されたデータは、独立して、3つの群(C、FW、およびFB)×3つの相(試験前、1 0分保持、2 4時間保持)×4つの試験ブロック(1〜5、6〜1 0、1 1〜1 5、および1 6〜2 0) 重要な主効果と二つ以上の手段を含む単純な主効果のすべては、Bonferroniの調整を使用して分解されました。 すべての比較について、p<0.05の場合、効果は有意であるとみなされた。 部分η二乗(np2)は、すべての有意な効果について報告された効果サイズである(Cohen、1988)。
結果
総移動時間
|CE|で計算されたANOVA(図2、上のパネル)は、変数グループF(2,87)=5.04、p=0.08、np2=0.10、および位相f(2,174)=5.16、p=0.007、np2=0.06について有意な主効果を明らかにした。有意な相×群相互作用として、f(4,174)=4.93、P=0.001、Np2=0.10。 この相互作用の内訳は、事前試験における有意な群の違いを明らかにしなかった(F<1)。 10分保持試験では、F(2,87)=10.12,p<0.001,np2=0.19,事後比較は、対照群がFWとFB群の両方よりも有意に大きい|CE|を持っていたことを明らかにした(p<0.05両方の場合),これは互いに有意に異ならなかった(p=0.19). 24時間保持試験では、F(2,87)=4.34、p=0.016、np2=0.09、FW群は対照群よりも有意に小さい|CE|を有していた(p=0.012)1。
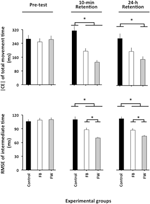
図2. 実験段階と実験グループの関数としてのTMTの絶対定数誤差と相対タイミングの二乗平均平方根誤差(実験1)。 *p<0.05。 誤差バーは、平均の標準誤差を示します。VE(図示せず)で計算されたANOVAは、可変位相、F(2,174)=13.12、p<0.001、np2=0.13、およびブロック、f(3,261)=48.79、p<0.001、np2=0.36について有意な主効果を明らかにした。 相効果の事後比較は、10分および24時間保持試験の両方よりも前試験における総時間の大きなVEを明らかにした(p<0。両方の場合において002)、これは互いに有意に異ならなかった(p=0.68)。 ブロックの主効果は、残りの三つの試験ブロック(すべてのケースでp<0.001)よりも最初の合計時間のVEが有意に大きくなり、互いに有意に異ならなかった(すべてのケースでp>0.05)。
相対タイミング
相対タイミングのRMSEで計算されたANOVAは、変数グループ、F(2,87)=21.49、p<0.001、np2=0.33、phase、F(2,174)=39.98、p<0.001、np2=0について有意な主効果を明らかにした。図31およびブロック、F(3,261)=14.77、p<0.001、np2=0.14、ならびに有意な相×群相互作用、F(4,174)=12.81、p<0.001、np2=0.23。 ブロックの主効果は、残りの三つの試験ブロック(すべてのケースでp<0.001)よりも最初の相対タイミングのRMSEが有意に大きくなり、互いに有意に異ならなかった(すべてのケースでp>0.3)。 さらに興味深いことに、相×群相互作用の内訳(図2、下のパネル)は、前試験における有意な群の違いを明らかにしなかった(F<1)。 10分では、F(2、87)=14.85、p<0.001、np2=0.34、および24時間保持テスト、F(2、87)=23.23、p<0.001、np2=0.35、FB群は対照群を有意に上回ったが(p=0.001両方の場合)、FB群は、順番に、FWグループ(それぞれp=0.001およびp=0.02)2。
ディスカッション
本実験は、新しい相対的なタイミングパターンの学習を最適化する観測条件の知識を拡張するために設計されました。 この学習状況では,様々なデモンストレーションを観察した二つの観察グループが,獲得フェーズ中に各試行の前または後にKRを提供した。 具体的には、学習者がデモを観察する前にデモの”質”や特性を知っているときに学習が強化されるかどうかを評価したかったのです。 結果は簡単です。
まず、図2に示すように、FW群とFB群の両方が保持試験で対照群よりも優れていました。 これは、TMTと相対タイミングの両方の学習に当てはまりました。 この予想される結果は、観察が新しい運動技能を学ぶことを可能にすることを示した以前の知見を確認する(McCullagh et al. ら、1 9 8 9;Hodges e t a l. ら、2 0 0 7;VogtおよびThomaschke、2 0 0 7;Ste−Marieら、2 0 0 7;Stre−Marieら、2 0 0 8)。 ら、2 0 1 2;Lago−Rodríguez et al. 特に、新しい相対的なタイミングパターン(Rohbanfard and Proteau、2011;Andrieux and Proteau、2013、2014)。
本研究の最も重要な知見は、FB群が保持試験においてFW群より優れていたことである。 二つのグループは同じデモンストレーションを観察したが,その結果,目撃されたデモンストレーションの品質や特性について事前に知識を与えられたときに学習が最適化されることが明らかになった。 この発見は、私たちの研究室からの以前の報告(Rohbanfard and Proteau、2011;Andrieux and Proteau、2013)によく適合し、観察者が誰が専門家モデルであり、誰が初心者モデルであるかを知っている混合観察レジメンは、専門家や初心者の観察だけよりも新しい相対的なタイミングパターンの学習を好むことを示している。
本研究のような初心者参加者がデモの質を評価するのが得意ではないことが報告されていることを考慮すると、完全ではないデモが示される 例えば、Aglioti e t a l. (2008年)は、初心者や専門家のバスケットボール選手にフリースローのショットを示すビデオクリップを観察させ、ビデオクリップはボールリリースの前または直後に異なる時間に停止させた。 専門家のバスケットボール選手やコーチ/専門のジャーナリストは、初心者よりもショットの運命を予測するのがより速く、より速く(成功したかどうか)であった(同様の結果については、Wrightらも参照してください。 ら、2 0 1 0;Abreu e t a l. ら、2 0 1 2;Tomeo e t a l. ら、2 0 1 3;Balser e t a l. ら、2 0 1 4;Candidi e t a l. ら、2 0 1 4;Renden e t a l., 2014).
FBプロトコルに対するFWの利点は重要であり、我々が知る限り、同様の発見はこれまでに報告されていない。 したがって、この発見の複製が重要であると思われた。 さらに、FWプロトコルの利点は、限られた量の観察の後にのみ発生するかどうか疑問に思いました。 最後に、FWとFBプロトコルを交互にすることで加法的な効果が生じるかどうかを知りたいと思いました。 これらの質問に対処するために実験2を実施しました。
実験2
方法
参加者
この実験に志願した60人の参加者は、実験1と同じ人口(男性36人、女性24人、平均年齢=22.7歳、SD=4.9歳)から引き出された。 参加者は、この研究の目的に関して素朴であり、その作業に関する事前の経験はなかった。 彼らは参加する前に個々の同意書に記入し、署名しました。 モントリオール大学の健康科学研究倫理委員会は、この実験を承認しました。
装置、タスク、実験フェーズ、手順、データ解析
実験1と同じタスク、装置、手順を使用しました。 今回の実験と実験1の主な違いは、参加者が2つの獲得セッションを行い、合計5つの実験フェーズにつながったことです:事前テスト、獲得1、即時保持テス
参加者は、それぞれ20人の参加者(グループあたり8人の女性)からなる三つのグループのいずれかにランダムに割り当てられました:取得1と2の両方の間のフィードフォワードkrと観測(FW1-2);取得1の間のフィードフォワード観測とKRが、取得2の間の観測とフィードバックKR(FW/FB); そして獲得1および2(FB1-2)両方の間の観察およびKRのフィードバック。 実験1と同じビデオとモデルを使用しましたが、アクイジション2ではビデオ提示の順序がアクイジション1では異なりました。 すべての参加者はまた、各取得段階の後に同じタスクを実行することを知らされましたが、自分のパフォーマンスに関するKRはありませんでした。
実験1と同じ従属変数とデータ変換を使用しました。 各従属変数について、本発明者らは、3つのグループ(FW1−2、FW/FBおよびFB1−2)×3つの実験段階(試験前、即時保持、および2 4時間保持)を対比する2元A NOVAを行 重要な主効果と二つ以上の手段を含む単純な主効果のすべては、Bonferroniの調整を使用して分解されました。 すべての比較について、p<0.05の場合、効果は有意であるとみなされた。 部分η二乗(np2)は、すべての有意な効果について報告された効果サイズである(Cohen、1988)。
結果
総移動時間
移動時間の|CE|に対して計算されたANOVA(図3)は、変数グループF(2,57)=8.13、p=0.001、np2=0.22、および位相f(2,114)=21.13、p<0.001、p<0.001、p<0.001、p<0.001、p<0.001、p<0.001、p<0.001、p<0.001、p<0.001、p<0.001、p<0.001、NP2=0.27、および有意な群×相相互作用、F(4、114)=2.57、P=0.042、Np2=0.08。 この相互作用の内訳は、事前試験における有意な群の違いを明らかにしなかった(F<1)。 即時保持テストでは、F(2,57)=10.27、p<0.002、np2=0です。図27に示すように、FB1-2群は、FW1-2群およびFW|FB群の両方よりも有意に大きい|CE|を有し(両方の場合においてp<0.001)、互いに有意に異ならなかった(p>0.20)。 24時間保持試験では、F(2,57)=3.19、p=0.049、np2=0.10、FW1-2群はFB1-2群(p=0.079)3よりもわずかに小さい|CE|を有していた。
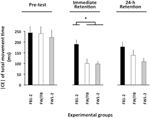
図3. 実験相および実験群の関数としてのTMTの絶対定数誤差(実験2)。 *p<0.05。 誤差バーは、平均の標準誤差を示します。VE(図示せず)で計算されたANOVAは、変数グループ、F(2,57)=7.82、p=0.001、np2=0.21、および位相、F(2,114)=21.10、p<0.001、np2=0.27、および有意なグループ×位相相互作用、F(4,114)=21.10、p<0.001、np2=0.27で有意な主効果を明らかにした。4.38、p=0.002、np2=0.13。 この相互作用の内訳は、試験前(F<1)および24時間保持試験では、F(2、57)=1.26、p>0.20の有意なグループの違いを明らかにしなかった。 即時保持テストでは、F(2,57)=10.26,p<0.002,np2=0.27,FB1-2グループ(62.7ms)FW1-2(51.1ms)とFW/FB(53.4ms)グループ(両方のケースでp<0.001)よりも有意に大きいVEを持っていたが、互いに有意に異ならなかった(p>0.20)4。
相対タイミング
相対タイミングのRMSEに対して計算されたANOVAは、変数グループF(2,57)=4.86、p=0.01、np2=0.15、および位相F(2,114)=78.21、p<0.001、np2=0.58に有意な主効果を明らかにした。 即時保持試験および24時間保持試験の両方よりも、試験前の相対タイミングの有意に大きなRMSEがあった(p<0。両方の場合において001;図4、右パネルを参照)、これは互いに有意に異ならなかった(p>0.20)。 最後に、FW1-2群とFW/FB群はFB1-2群よりも優れていました(p=0.01およびp=0.07;図4、左パネル参照)が、互いに有意差はありませんでした(p>0.20)。
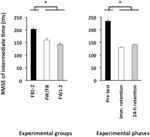
図4. 実験グループ(左パネル)と実験フェーズ(右パネル)の関数としての相対タイミング(実験2)の二乗平均平方根誤差。 *p<0.05。 誤差バーは、平均の標準誤差を示します。
ディスカッション
予想通り、テスト前から保持テストに行くときに指摘されたエラーの減少は、観察が新しい相対的なタイミングパターンの学習を助 ることができると考えられている。 さらに重要なことに、実験2の結果は、FW1-2グループがFB1-2グループよりも優れているという点で、実験1の結果を複製しました。 したがって,タスクの制約から自然に現れる相対的なタイミングパターンを,観察を通じて新しい課された相対的なタイミングに変更することを学ぶことは,観察の後ではなく前のモデルの性能を知らされるときに好まれると結論できる。 最後に、結果はまた、FBプロトコルで学習されたものは、FWプロトコルで学習できるものに加算されないことを示しました。
一般的な議論
本研究の主な目的は、観測プロトコルにおいて、モデル性能に関するKRをいつ提供すべきか、すなわち各実証の前または後に決定す 本研究の二つの実験の結果は,各デモンストレーションの前にモデルの性能を知らされることは,観察者が各デモンストレーションの後にモデルの性能を知らされたときよりも新しい相対タイミングパターンの学習を好むことを明確に示した。 さらに、実験2の結果は、観察試験の数が倍増した場合でも、FBプロトコルに対するFWの利点が重要であることを示唆している。 この最後の点について、我々は、FWプロトコルがすべてのケースで、オブザーバーのすべてのレベルの専門知識で支持されるべきであると主張していない。 むしろ、初心者のオブザーバーが考慮されたときに効果が信頼できることを強調しています。
我々の結果は、フィードフォワード観測プロトコルが、専門家または高度な性能が示されているときに模倣プロセスに、または初心者または初心者の性能が示されているときにエラー検出プロセスのいずれかに特異的に従事するように観察者を準備することを示している可能性がある。 このアイデアは、Decetyらの以前の仕事によく合います。 (1997)は、行動観察中の脳活性化のパターンは、必要な実行処理の性質と提示された行動の外因性特性の両方に依存すると述べた。 具体的には、これらの著者らは、初心者モデルや悪いまたは中間のパフォーマンスを観察する場合には、認識することを観察すると、脳のさまざまな領域がより活発になることを実証しました。
我々の調査結果の別の説明は、参加者が貧弱なデモが続くことを明示的に知らされたときに、FWプロトコルがAONの”無効化”をもたらす可能性があります。 例えば、物体持ち上げ作業では、持ち上げ作用の観察中の経頭蓋磁気刺激(TMS)によるモーター誘発電位(MEP)の変調は、把持および持ち上げ作用を実行するために必,2010a). また、視覚的な手がかりが物体が実際よりも重いことを示唆したとき、MEP変調は、物体の見かけの重量ではなく、観察された運動学的プロファイルに主に依存することが示された(Alaerts et al. ら、2 0 1 0b;Senot e t a l., 2011). しかし、Senot et al. (2011)では、物体の重量に関する誤った明示的な情報が一つの実験条件で提供された。 これは、発表された重量を与えられた予想される運動学的プロファイルと、把持および持ち上げ作用の実際の運動学的プロファイルとの間に矛盾を生じ、”皮質脊髄系の一般的な阻害”につながる。”別の言い方をすれば、AONの少なくとも一部がオフになっていました。 したがって、我々の研究の参加者は、モデルのパフォーマンスの低下が予想されたときにAONをオフにし、良好な試験のためにのみAONをアクティブにしたと
この命題は、しかし、専門家と初心者モデルの両方を観察することは、初心者モデルまたは専門家モデルだけを観察するよりも、新しい相対的なタイ 悪いデモンストレーションが表示されることを知らされたときにAONをオフにすることができれば(すなわち、初心者モデル)、混合観察グループの学習は、専門家の観察グループの学習と一致し、それを上回ることはなかったであろう。 むしろ、私たちの最初の命題に戻って、我々はFWプロトコルは、初心者のパフォーマーがモデルのパフォーマンスのエラーを検出し、定量化するのに役立つことを示唆しています(Aglioti et al. ら、2 0 0 8;Wright e t a l. ら、2 0 1 0;Abreu e t a l. ら、2 0 1 2;Tomeo e t a l. ら、2 0 1 3;Balser e t a l. ら、2 0 1 4;Candidi e t a l. ら、2 0 1 4;Renden e t a l., 2014). 次に、モデルの性能のより良い検出および定量化は、運動制御の逆モデル(Jordan、1996)および前方モデル(Wolpert And Miall、1996)の開発を有利にする可能性がある。
結論として、観察は誰でも利用できる強力な学習ツールであり、最小限の機器のみを使用する必要があります。 運動技能の相対的なタイミング(すなわちテンポ)を変更するための観察の利点は、初心者から専門家まで、可変または混合観察スケジュールを介して様々な 本研究の結果は,観察者が最初の観察セッション中に観察しようとしている性能の質を事前に知っていれば,これらの利点が最適化されることを示唆している。 これは、教師/トレーナーがビデオ観察プロトコルを使用する教室の文脈で非常に重要である可能性があります。 例えば、観察者の意図がゴルフスイングの特定の側面を学ぶことである場合、スイングの結果(すなわち、ボールの飛行)はビデオに表示されない可能性が したがって、観察者はスイングの結果からモデルの専門知識を”推測”することができず、本研究で示したように、観察しようとしているものの質を事前に知らされていれば、よりよく学ぶことができる。
著者の貢献
リストされているすべての著者は、作品に実質的、直接的、知的な貢献をし、出版を承認しました。
資金調達
この研究は、カナダ自然科学工学研究評議会が提供するディスカバリー助成金(LP)によって支援されました(助成金番号。 111280-2013).
利益相反に関する声明
著者らは、本研究は、利益相反の可能性があると解釈される可能性のある商業的または財務的関係がない場合に行われた
脚注
1. ^対照群とFW群およびFB群との間の二つの保持試験で指摘された違いが、総移動時間の|CE|の有意な減少に起因することを確認するために、補足分析では、 その結果,対照群とF b群では,総移動時間の/CE/はそれぞれ相間で有意に異ならないことが明らかになった。 逆に、FWグループのために、相、F(2、86)=11の有意な主な効果があった。図60に示すように、p<0.01、np2=0.1であり、試験前から二つの保持試験までの総移動時間の|CE|の有意な減少を明らかにした(p<0.01)が、互いに有意に異ならなかった(p>0.10)。
2. ^総移動時間の/CE/について行ったように、補足分析では、各グループについて別々のANOVAを計算することによって、相対タイミングのRMSEについて本文で報告され 結果は、対照群のために、相対タイミングのRMSEは、位相、F(2、86)=0.32、p=0.72、np2=0.01にわたって有意に異ならなかったことを明らかにした。 逆に、FB群とFW群の両方について、試験前から二つの保持試験(p<0.01)に行く相対的なタイミングのRMSEの有意な減少を明らかにした相の有意な主な効果があった(p>0.10)。
3. ^実験1で行ったように、補足分析では、各グループについて別々のANOVAを計算することによって、本文で報告されたグループ×位相相互作用を分解しました。 結果は、FB1-2グループのために、総移動時間の|CE|が大幅に相間で異ならなかったことを明らかにした、F(2, 56) < 1, p=0.45、np2=0.03。 逆に、FW1-2およびFW-FBグループの両方について、相の有意な主な効果があり、両方のグループについて、試験前から二つの保持試験に行く総移動時間の|CE|の有意な減少を明らかにした(p<0。ら有意差はなかった(p<2 6 1 5>0.
4. ^総移動時間のVEについては、グループ×位相相互作用の内訳は、すべての三つのグループの位相の有意な主効果を明らかにした。 FW1−2群およびFB1−2群について、pos−hoc比較は、両保持試験よりも前試験において有意に大きいVEを明らかにした(p<2 7 1 8>0. FW-FB群では、総移動時間のVEは、24時間保持試験よりも前試験で有意に大きかった(p<0.01)。
とができるようになることを期待しています。 行動観測ネットワークを超えた行動予測:専門家のバスケットボール選手における機能的磁気共鳴イメージング研究。 ユーロ J.Neurosci. 35, 1646–1654. ドイ:10.1111/j.1460-9568.2012.08104.x
PubMed要約/CrossRef全文|Google Scholar
アリオティ,S.M.,Cesari,P.,Romani,M.,And Urgesi,C.(2008). エリートバスケットボール選手のアクション期待とモーター共鳴。 ナット ニューロシ… 11, 1109–1116. ドイ:10.1038/nn.2182
PubMed要約/CrossRef全文/Google Scholar
とができるようになることを期待しています。 タスクの制約の特異性と、スキル習得中の学習者の検索を指示する際の視覚的なデモンストレーションと口頭の指示の効果。 J.Mot. 行動する。 33, 295–305. 土井: 10.1080/00222890109601915
PubMed Abstract|CrossRef全文|Google Scholar
とができるようにすることを目的としています。 観測された物体の持ち上げの力要件は、観測者のモータシステムによってコード化されています:TMS研究。 ユーロ J.Neurosci. 31, 1144–1153. ドイ:10.1111/j.1460-9568.2010.07124.x
PubMed要約/CrossRef全文|Google Scholar
とができることを示唆している。 他の人がどのように軽い物体や重い物体を持ち上げるかを観察する:どの視覚的手がかりが一次運動野における筋肉力のコード化を仲介するか? 神経心理学48、2082-2090。 土井:10.1016/j.神経心理学.2010.03.029
PubMed要約/CrossRef全文/Google Scholar
とができるようになりました。 運動タスクの観察学習:誰といつ? 経験値 脳Res.229,125-137. ドイ:10.1007/s00221-013-3598-x
PubMed要約/CrossRef全文|Google Scholar
とができるようになりました。 混合観察は、モデルの性能をより良く推定することによって、運動学習を支持する。 経験値 脳Res.232,3121-3132. 土井:10.1007/00221-014-4000-3
PubMed Abstract|CrossRef全文|Google Scholar
Badets,A.,And Blandin,Y.(2004). 観察を通じて学習における結果頻度の知識の役割。 J.Mot. 行動する。 36, 62–70. ドイ:10.3200/JMBR.36.1.62-70
Pubmed要約/CrossRef全文/Google Scholar
Badets,A.,And Blandin,Y.(2005). 観察学習:結果の帯域幅知識の効果。 J.Mot. 行動する。 37, 211–216. ドイ:10.3200/JMBR.37.3.211-216
PubMed Abstract | CrossRef Full Text | Google Scholar
Badets, A., Blandin, Y., Wright, D. L., and Shea, C. H. (2006). Error detection processes during observational learning. Res. Q. Exerc. Sport 77, 177–184. doi: 10.1080/02701367.2006.10599352
PubMed Abstract | CrossRef Full Text | Google Scholar
Balser, N., Lorey, B., Pilgramm, S., Naumann, T., Kindermann, S., Stark, R., et al. (2014). テニスやバレーボールを見越しての行動観察ネットワークの脳活性化に及ぼす専門知識の影響が役立つ。 フロント ハム ニューロシ… 8:568. ドイ:10.3389/fnhum.2014.00568
PubMed要約/CrossRef全文/Google Scholar
Bird,G.,And Heyes,C.(2005). 指の動きシーケンスの観察によるエフェクタ依存学習。 J.Exp. サイコル ハム パーセプト 実行します。 31, 262–275. 土井: 10.1037/0096-1523.31.2.262
PubMed Abstract|CrossRef全文|Google Scholar
ブラック、C.B. およびWright,D. 観察練習は誤りの認識と動きの生産を容易にすることができますか? 再… Q.運動。 71件中331-339件を表示しています。 土井: 10.1080/02701367.2000.10608916
PubMed Abstract|CrossRef全文|Google Scholar
(1994年)。 モデル主題、未発表の博士論文の練習と観察の異なる条件の下で時空間同期タスクの学習中に関与する認知プロセス。 モントリオール大学出身。
ることができます。 (1999). 運動能力の観察学習の基礎となる認知プロセス。 Q.J.Exp. サイコル 52, 957–979. 土井: 10.1080/713755856
CrossRef全文|Google Scholar
ることを明らかにした。 文脈上の干渉と観察学習の基礎となる認知プロセスについて。 J.Mot. 行動する。 26, 18–26. 土井: 10.1080/00222895.1994.9941657
PubMed Abstract|CrossRef全文|Google Scholar
Buccino,G.,Binkofski,F.,Fink,G.R.,Fadiga,L.,Fogassi,L.,Gallese,V.,et al. (2001). 行為の観察はsomatotopic方法のpremotorおよび頭頂の区域を活動化させます:fMRIの調査。 ユーロ J.Neurosci. 13, 400–404. ドイ:10.1046/j.1460-9568.2001.01385.x
PubMed要約/CrossRef全文|Google Scholar
Buchanan,J.J.,And Dean,N.J.(2010). 実践における特異性は、初心者モデルにおける学習に利益をもたらし、実証における変動性は観察的実践に利益をもたらす。 サイコル 74,313-326 ドイ:10.1007/s00426-009-0254-y
PubMed要約/CrossRef全文|Google Scholar
ブキャナン,J.J. ることを明らかにしています。 単一肢の複数の接合箇所の調整の仕事の相対的なしかし絶対動きの特徴の観察練習。 経験値 脳Res.191,157-169. ドイ:10.1007/s00221-008-1512-8
PubMed Abstract|CrossRef全文|Google Scholar
Candidi,M.,Sacheli,L.M.,Mega,I.,And Aglioti,S.M.(2014). 感覚運動の専門家におけるピアノ運指エラーのSomatotopicマッピング:ピアニストと視覚的に訓練された音楽naivesにおけるTMS研究。 セレブ 24,435-443 土井:10.1093/cercor/bhs325
PubMed要約/CrossRef全文/Google Scholar
およびBandura,A. 観察学習における行動生産の表現的指導:因果分析。 J.Mot. 行動する。 22, 85–97. 土井: 10.1080/00222895.1990.10735503
PubMed Abstract|CrossRef全文|Google Scholar
ることができる。 背側運動前皮質における精神的リハーサルの神経相関。 自然431、993-996。 土井:10.1038/nature03005
PubMed要約/CrossRef全文/Google Scholar
Cohen,J.(1988). 行動科学のための統計的パワー分析。 ローレンス・エルバウム(Lawrence Erlbaum,NJ)は、アメリカ合衆国ニュージャージー州の都市。
およびWright(1 9 9 5)。 リズミカルなタッピングでのサンプルと複雑な配給の時間的再スケーリング。 J.Exp. サイコル ハム パーセプト 実行します。 21, 602–627. 土井: 10.1037/0096-1523.21.3.602
PubMed Abstract|CrossRef全文|Google Scholar
クロス,E.S.,Kraemer,D.J.M. とができるようになることを期待しています。 行動観察ネットワークの物理的および観察的学習に対する感度。 セレブ 19,315-326 doi:10.1093/cercor/bhn083
PubMed要約/CrossRef全文/Google Scholar
Decety,J.,Grèzes,J.,Costes,N.,Perani,D.,Jeannerod,M.,Procyk,E.,et al. (1997). 行動の観察中の脳活動-行動内容と被験者の戦略の影響。 ブレイン120、1763-1777。 ドイ:10.1093/脳/120.10.1763
PubMed Abstract/CrossRef Full Text|Google Scholar
Dushanova,J.,And Donoghue,J.(2010). 一次運動野のニューロンは、行動観察中に従事した。 ユーロ J.Neurosci. 31, 386–398. ドイ:10.1111/j.1460-9568.2009.07067.x
PubMed要約/CrossRef全文|Google Scholar
とができるようになった。 行動の観察学習中の神経活動の変調とその逐次的な順序。 J.Neurosci. 26, 13194–13201. 土井:10.1523/JNEUROSCI.3914-06.2006
PubMed要約/CrossRef全文/Google Scholar
Gallese V.,Fadiga L.,Fogassi L.,Rizzolatti G.(2002). “行動表現と下頭頂小葉”、”知覚と行動における共通のメカニズム:注意とパフォーマンス、Vol. Hommel(Oxford:Oxford University Press),2 4 7−2 6 6.
ることができると考えられている。 よく知られた用具の観察そして名前を付けることの間のPromotor皮質の活発化。 ニューロイメージ6,231-236. 土井:10.1006/nimg.1997.0293
PubMed抄録/CrossRef全文/Google Scholar
とができるようになりました。 一般的な運動表現は、行動観察中に開発される。 経験値 脳Res.204,199-206. ドイ:10.1007/s00221-010-2303-6
PubMed Abstract|CrossRef全文|Google Scholar
Heyes,C.M.,And Foster,C.L.(2002). 観察による運動学習:連続反応時間タスクからの証拠。 Q.J.Exp. サイコル 55, 593–607. 土井:10.1080/02724980143000389
PubMed要約/CrossRef全文/Google Scholar
Hodges,N.J.,Chua,R.,And Franks,I.M.(2003). 新しい協調運動の知覚と行動を促進する上でのビデオの役割。 J.Mot. 行動する。 35, 247–260. 土井: 10.1080/00222890309602138
PubMed Abstract|CrossRef全文|Google Scholar
Hodges,N.J.,Williams,A.M.,Hayes,S.J.,And Breslin,G.(2007). 観察学習中にモデル化されるものは何ですか? J.Sports Sci. 25, 531–545. 土井:10.1080/02640410600946860
PubMed要約/CrossRef全文/Google Scholar
Jordan,M.I.(1996). “運動制御と運動学習の計算的側面”、”知覚と行動のハンドブック:Vol. 2,Motor Skills,Eds H.Heuer and S.W.Keele(New York,NY:Academic Press),71-120.
とができるようになることを期待しています。 ヒト下前頭回におけるミラーニューロンの証拠。 J.Neurosci. 29, 10153–10159. 土井:10.1523/JNEUROSCI.2668-09.2009
PubMed要約/CrossRef全文/Google Scholar
Lago-Rodríguez,A.,Cheeran,B.,And Koch,G.(2014). 観察運動学習におけるミラーニューロンの役割:統合的なレビュー。 ユーロ J.ヒューマン-ムーヴ所属。 32, 82–103.
およびSerrien,Dj(1 9 9 4)を参照されたい。 認知努力と運動学習。 クエスト46、328-344。 土井: 10.1080/00336297.1994.10484130
CrossRef全文|Google Scholar
およびWhite,M.A.(1 9 9 0)。 非熟練モデル練習スケジュールが観察運動学習に及ぼす影響。 ハム Mov。 サイ… 9, 349–367. 土井: 10.1016/0167-9457(90)90008-2
CrossRef全文|Google Scholar
ることができます。 モーター性能への影響をモデル化する。 Res.Q.47,277-291.
およびCaird(1 9 9 0)。 正しいと学習モデルと運動能力の獲得と保持における結果のモデル知識の使用。 J.ヒューマン-ムーヴ所属。 スタッドレスタイヤ 18, 107–116.
ら、Mccullagh,P.,およびMeyer,K. 学習対正しいモデル:自由体重スクワットリフトの学習に対するモデルタイプの影響。 レセQ.エクセルク. スポーツ68、56-61。 土井: 10.1080/02701367.1997.10608866
PubMed Abstract|CrossRef全文|Google Scholar
ることができます。 運動能力の獲得と性能におけるモデリングの考慮事項:統合されたアプローチ。 エクセルク… スポーツサイ… 17,475-513
とができるようにすることを目的としています。 表面ベースの情報マッピングは、人間の頭頂および後頭部側皮質における横断的なビジョンアクション表現を明らかにする。 J.Neurophysiol。 104, 1077–1089. 土井:10.1152/jn.00326.2010
PubMed要約/CrossRef全文/Google Scholar
およびLee,Td(1 9 9 2)。 モデルのスキルレベルが観察運動学習に及ぼす影響。 レセQ.エクセルク. スポーツ63、25-29。 土井:10.1080/02701367.1992.10607553
PubMed Abstract|CrossRef全文|Google Scholar
Renden,P.G.,Kerstens,S.,Oudejans,R.R.D.,およびCañal-Bruland,R.(2014). ファウルかダイブか? サッカーにおける反則行為の判定に貢献した。 ユーロ J.Sport Sci. 14(サップル。 1)、S221-S227。 土井: 10.1080/17461391.2012.683813
PubMed Abstract|CrossRef全文|Google Scholar
ることを可能にすることを目的としています。 目標指向行動の組織化とミラーニューロンベースの行動理解の基礎となる皮質メカニズム。 フィジオール 94,655-706 土井:10.1152/physrev.00009.2013
PubMed要約/CrossRef全文/Google Scholar
ることができます。 ミラーメカニズム:最近の発見と視点。 フィロス トランス R.Soc. ロンド サー Bバイオル サイ… 369:20130420. ドイ:10.1098/rstb。2013.0420
PubMed要約/CrossRef全文/Google Scholar
ることができます。 観察を通して学習:専門家と初心者のモデルの組み合わせは、学習を支持します。 経験値 脳Res.215,183-197. ドイ:10.1007/s00221-011-2882-x
PubMed要約/CrossRef全文|Google Scholar
ることができるようになりました。 把握観察中の皮質脊髄興奮性に対する体重関連ラベルの影響:TMS研究。 経験値 脳Res.211,161-167. 土井:10.1007/00221-011-2635-x
PubMed要約/CrossRef全文|Google Scholar
ることができるようになりました。 運動技能学習とパフォーマンスのための観察介入:観察の使用のための応用モデル。 Int. スポルティング所属。 サイコル 5, 145–176. ドイ:10.1080/1750984X.2012.665076
CrossRef全文|Google Scholar
トメオ,E.,Cesari,P.,Aglioti,S.M.,とUrgesi,C.(2013). キッカーではなく、ゴールキーパーをだます: サッカーにおける偽の行動検出の行動および神経生理学的相関。 セレブ 23,2765-2778 doi:10.1093/cercor/bhs279
PubMed要約/CrossRef全文/Google Scholar
ることができる。 視覚-運動相互作用から模倣学習へ:行動および脳イメージング研究。 J.Sports Sci. 25, 497–517. 土井: 10.1080/02640410600946779
PubMed Abstract|CrossRef全文|Google Scholar
およびMiall,R. 生理学的な運動制御のための前方モデル。 ニューラルネットワーク 9, 1265–1279. ドイ:10.1016/S0893-6080(96)00035-4
PubMed Abstract|CrossRef全文|Google Scholar
およびCoady,W. 文脈干渉と観察学習に関連する認知プロセス:Blandin、ProteauおよびAlainの複製(1994)。 レセQ.エクセルク. スポーツ68,106-109. 土井: 10.1080/02701367.1997.10608872
PubMed Abstract|CrossRef全文|Google Scholar
ライト,M.J.,ビショップ,D.T.,ジャクソン,R.C., and Abernethy, B. (2010). Functional MRI reveals expert-novice differences during sport-related anticipation. Neuroreport 21, 94–98. doi: 10.1097/WNR.0b013e328333dff2
PubMed Abstract | CrossRef Full Text | Google Scholar