un depozit de date este un sistem electronic care colectează date dintr-o gamă largă de surse din cadrul unei companii și utilizează datele pentru a sprijini luarea deciziilor de management.
companiile se îndreaptă din ce în ce mai mult către depozite de date bazate pe cloud în loc de sisteme tradiționale la fața locului. Depozitele de date bazate pe Cloud diferă de depozitele tradiționale în următoarele moduri:
- nu este nevoie să achiziționați hardware fizic.
- este mai rapid și mai ieftin să configurați și să scalați depozitele de date cloud.
- arhitecturile de depozit de date bazate pe Cloud pot efectua de obicei interogări analitice complexe mult mai rapid, deoarece utilizează procesarea masivă paralelă (MPP).
restul acestui articol acoperă arhitectura tradițională a depozitului de date și introduce câteva idei și concepte arhitecturale utilizate de cele mai populare servicii de depozit de date bazate pe cloud.
pentru mai multe detalii, consultați pagina noastră despre conceptele depozitului de date din acest ghid.
- arhitectura tradițională a depozitului de date
- arhitectura pe trei niveluri
- Kimball vs. Inmon
- Data Warehouse Models
- schema stelară vs.schema Fulg De Zăpadă
- ETL vs. ELT
- maturitate organizațională
- noi arhitecturi de depozite de date
- Amazon Redshift
- Google BigQuery
- panoplia
- dincolo de depozitele de date Cloud
- Aflați mai multe despre depozitele de date
arhitectura tradițională a depozitului de date
următoarele concepte evidențiază unele dintre ideile stabilite și principiile de proiectare utilizate pentru construirea depozitelor de date tradiționale.
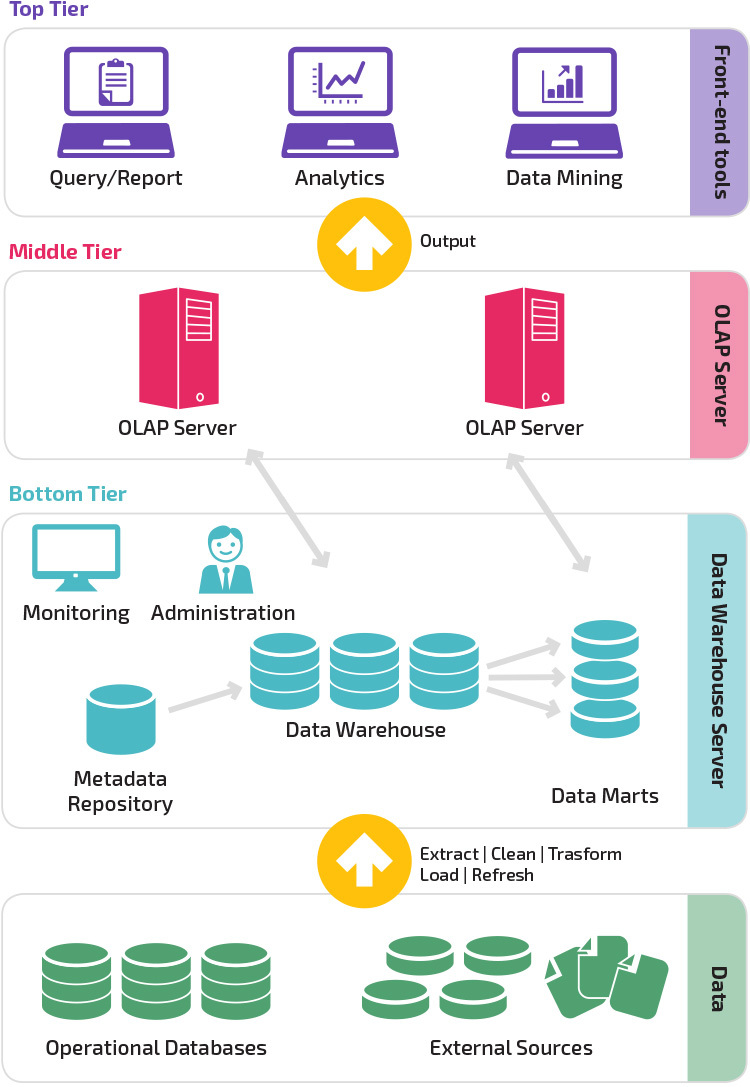
arhitectura pe trei niveluri
arhitectura tradițională a depozitului de date utilizează o structură pe trei niveluri compusă din următoarele niveluri.
- nivel inferior: acest nivel conține serverul bazei de date utilizat pentru a extrage date din mai multe surse diferite, cum ar fi din bazele de date tranzacționale utilizate pentru aplicațiile front-end.
- nivel mediu: Nivelul de mijloc găzduiește un server OLAP, care transformă datele într-o structură mai potrivită pentru analiză și interogări complexe. Serverul OLAP poate funcționa în două moduri: fie ca un sistem extins de gestionare a bazelor de date relaționale care mapează operațiile pe date multidimensionale la operații relaționale standard (OLAP relațional), fie folosind un model OLAP multidimensional care implementează direct datele și operațiile multidimensionale.
- Top tier: nivelul superior este stratul client. Acest nivel deține instrumentele utilizate pentru analiza datelor la nivel înalt, interogarea raportării și extragerea datelor.
Kimball vs. Inmon
doi pionieri ai depozitării datelor numiți Bill Inmon și Ralph Kimball au avut abordări diferite în ceea ce privește proiectarea depozitului de date.
abordarea lui Ralph Kimball a subliniat importanța data marts, care sunt depozite de date aparținând anumitor linii de afaceri. Depozitul de date este pur și simplu o combinație de diferite marts de date care facilitează raportarea și analiza. Designul depozitului de date Kimball folosește o abordare” de jos în sus”.
Bill Inmon a considerat depozitul de date ca fiind depozitul centralizat pentru toate datele întreprinderii. În această abordare, o organizație creează mai întâi un model de depozit de date normalizat. Marturile de date dimensionale sunt apoi create pe baza modelului depozitului. Aceasta este cunoscută ca o abordare de sus în jos a depozitării datelor.
Data Warehouse Models
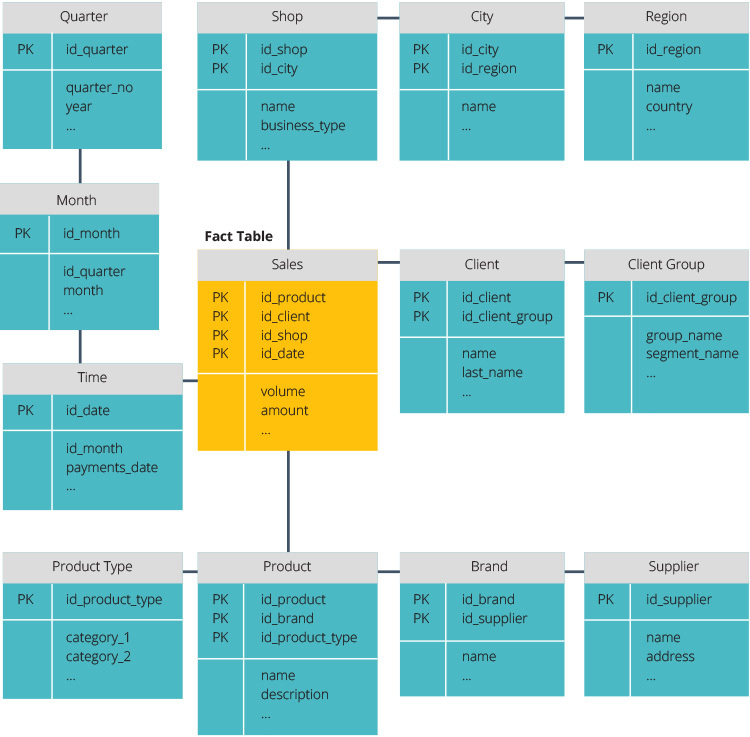
într-o arhitectură tradițională există trei modele comune de data warehouse: virtual warehouse, data mart și enterprise data warehouse:
- un depozit virtual de date este un set de baze de date separate, care pot fi interogate împreună, astfel încât un utilizator poate accesa eficient toate datele ca și cum ar fi fost stocate într-un singur depozit de date.
- un model data mart este utilizat pentru raportarea și analiza specifică liniei de afaceri. În acest model de depozit de date, datele sunt agregate dintr-o serie de sisteme sursă relevante pentru o anumită zonă de afaceri, cum ar fi vânzările sau finanțele.
- un model enterprise data warehouse prevede că depozitul de date conține date agregate care acoperă întreaga organizație. Acest model vede depozitul de date ca inima sistemului informatic al întreprinderii, cu date integrate de la toate unitățile de afaceri.
schema stelară vs.schema Fulg De Zăpadă
schema stelară și schema fulg de zăpadă sunt două moduri de a structura un depozit de date.
schema stea are un depozit de date centralizat, stocat într-un tabel de fapt. Schema împarte tabelul fact într-o serie de tabele de dimensiuni denormalizate. Tabelul de date conține date agregate pentru a fi utilizate în scopuri de raportare, în timp ce tabelul de parametri descrie datele stocate.
desenele Denormalizate sunt mai puțin complexe, deoarece datele sunt grupate. Tabelul fact folosește un singur link pentru a se alătura fiecărui tabel de dimensiuni. Designul mai simplu al schemei stelare face mult mai ușor să scrieți interogări complexe.
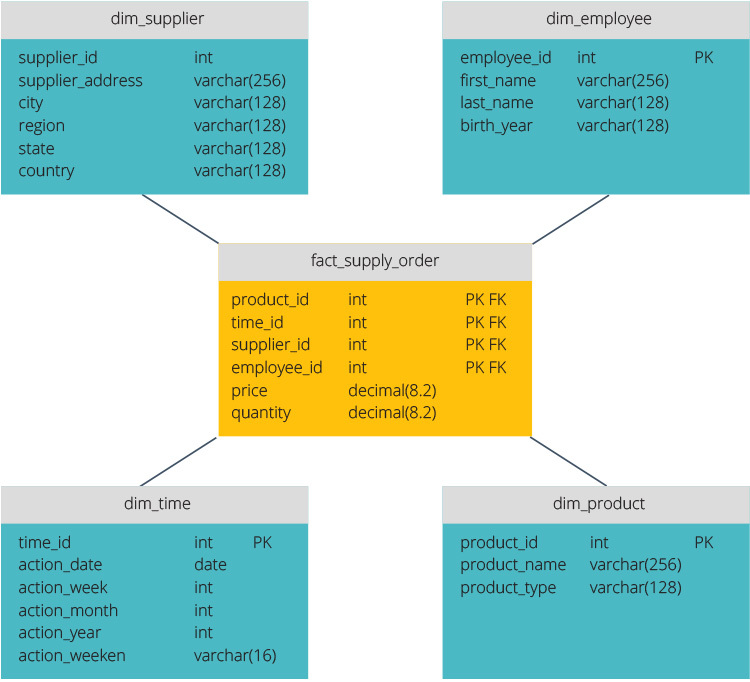
schema fulgului de zăpadă este diferită, deoarece normalizează datele. Normalizarea înseamnă organizarea eficientă a datelor astfel încât toate dependențele de date să fie definite și fiecare tabel conține redundanțe minime. Tabelele cu o singură dimensiune se ramifică astfel în tabele de dimensiuni separate.
schema fulg de nea utilizează mai puțin spațiu pe disc și păstrează mai bine integritatea datelor. Principalul dezavantaj este complexitatea interogărilor necesare pentru a accesa datele—fiecare interogare trebuie să sape adânc pentru a ajunge la datele relevante, deoarece există mai multe se alătură.
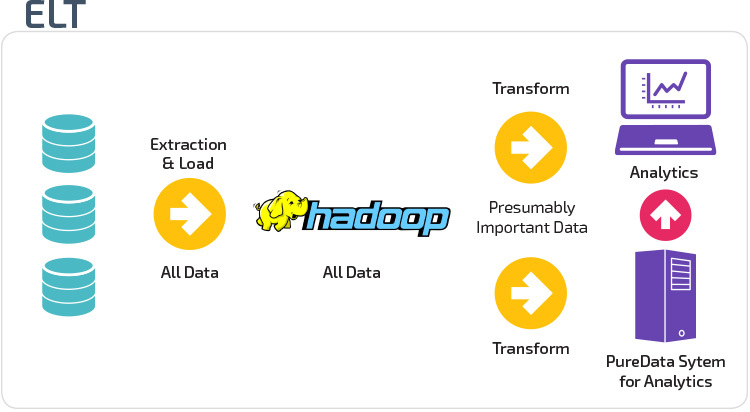
ETL vs. ELT
ETL și ELT sunt două metode diferite de încărcare a datelor într-un depozit.
Extract, Transform, Load (ETL) extrage mai întâi datele dintr-un grup de surse de date, care sunt de obicei baze de date tranzacționale. Datele sunt păstrate într-o bază de date de așteptare temporară. Operațiunile de transformare sunt apoi efectuate, pentru a structura și converti datele într-o formă adecvată pentru sistemul de depozit de date țintă. Datele structurate sunt apoi încărcate în depozit, gata de analiză.
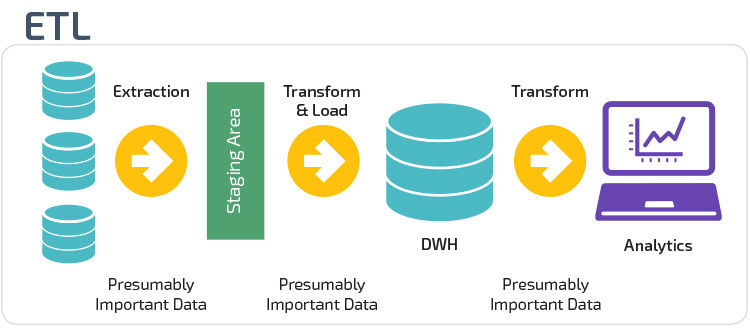
cu Extract Load Transform (ELT), datele sunt încărcate imediat după ce au fost extrase din bazinele de date sursă. Nu există o bază de date de așteptare, ceea ce înseamnă că datele sunt încărcate imediat în depozitul unic, centralizat. Datele sunt transformate în interiorul sistemului data warehouse pentru a fi utilizate cu instrumente și analize de business intelligence.
maturitate organizațională
structura depozitului de date al unei organizații depinde, de asemenea, de situația și nevoile sale actuale.
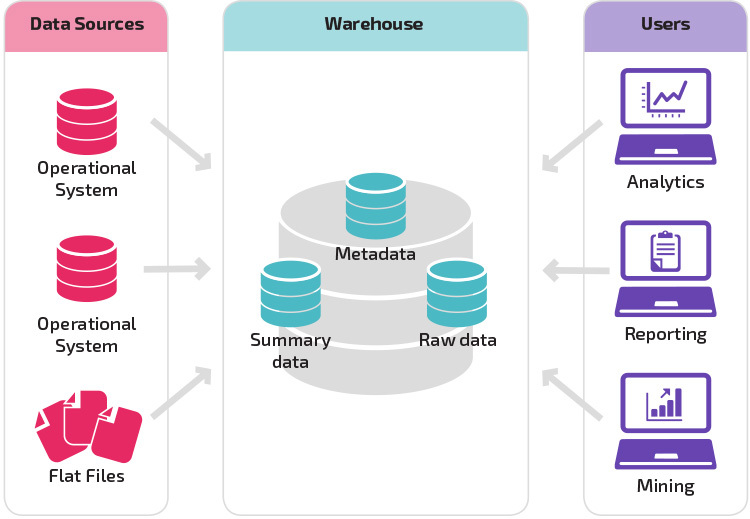
structura de bază permite utilizatorilor finali ai depozitului să acceseze direct datele sumare derivate din sistemele sursă și să efectueze analize, rapoarte și minerit pe aceste date. Această structură este utilă atunci când sursele de date provin din aceleași tipuri de sisteme de baze de date.
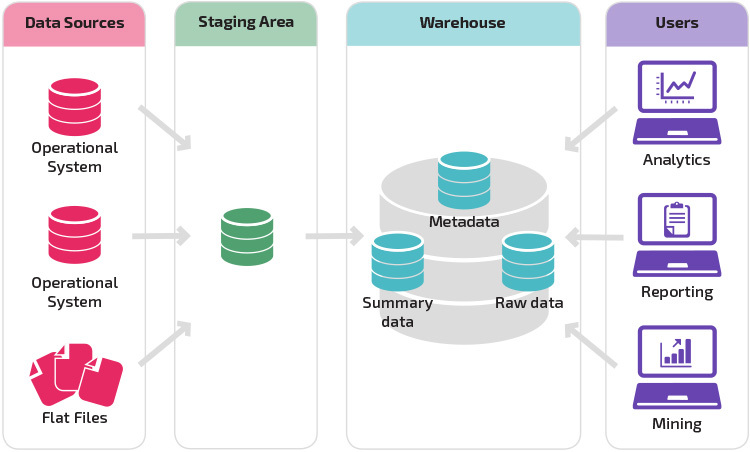
un depozit cu o zonă de așteptare este următorul pas logic într-o organizație cu surse de date disparate cu multe tipuri și formate diferite de date. Zona de stadializare convertește datele într-un format structurat rezumat, care este mai ușor de interogat cu instrumente de analiză și raportare.
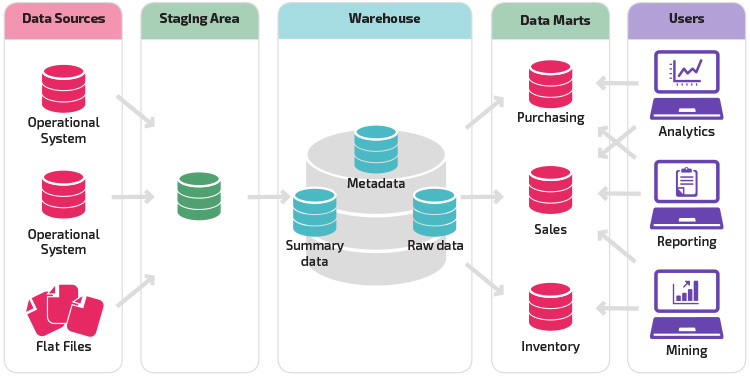
o variație pe structura de așteptare este adăugarea de marts de date la depozitul de date. Data marts stochează date rezumate pentru o anumită linie de afaceri, făcând aceste date ușor accesibile pentru forme specifice de analiză. De exemplu, adăugarea de date marts poate permite unui analist financiar să efectueze mai ușor interogări detaliate cu privire la datele de vânzări, pentru a face predicții despre comportamentul clienților. Data marts facilitează analiza prin adaptarea datelor în mod special pentru a satisface nevoile utilizatorului final.
noi arhitecturi de depozite de date
în ultimii ani, depozitele de date se mută în cloud. Noile depozite de date bazate pe cloud nu aderă la arhitectura tradițională; fiecare ofertă de depozit de date are o arhitectură unică.
această secțiune rezumă arhitecturile utilizate de două dintre cele mai populare depozite bazate pe cloud: Amazon Redshift și Google BigQuery.
Amazon Redshift
Amazon Redshift este o reprezentare bazată pe cloud a unui depozit de date tradițional.
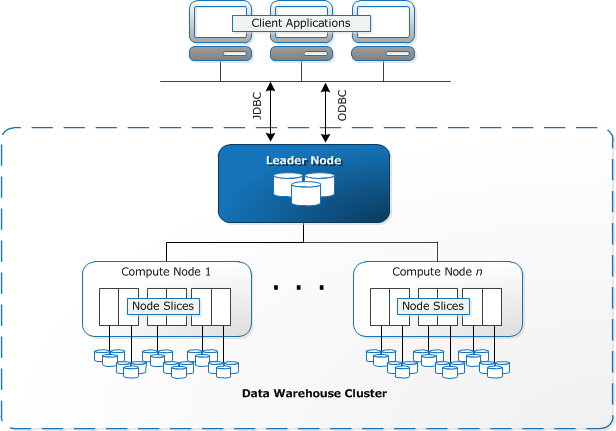
Redshift necesită resurse de calcul care trebuie furnizate și configurate sub formă de clustere, care conțin o colecție de unul sau mai multe noduri. Fiecare nod are propriul procesor, stocare și memorie RAM. Un nod lider compilează interogări și le transferă pentru a calcula noduri, care execută interogările.
pe fiecare nod, datele sunt stocate în bucăți, numite felii. Redshift utilizează o stocare coloană, ceea ce înseamnă că fiecare bloc de date conține valori dintr-o singură coloană pe un număr de rânduri, în loc de un singur rând cu valori din mai multe coloane.
Sursa: AWS Documentation
Redshift folosește o arhitectură MPP, împărțind seturi mari de date în bucăți care sunt atribuite feliilor din fiecare nod. Interogările funcționează mai repede, deoarece nodurile de calcul procesează interogările în fiecare felie simultan. Nodul Leader agregă rezultatele și le returnează aplicației client.
aplicațiile Client, cum ar fi instrumentele BI și analytics, se pot conecta direct la Redshift folosind drivere open source PostgreSQL JDBC și ODBC. Analiștii își pot îndeplini astfel sarcinile direct pe datele Redshift.
Redshift poate încărca numai date structurate. Este posibil să încărcați date în Redshift folosind sisteme pre-integrate, inclusiv Amazon S3 și DynamoDB, prin împingerea datelor de la orice gazdă premisă cu conectivitate SSH sau prin integrarea altor surse de date utilizând API-ul Redshift.
Google BigQuery
arhitectura BigQuery este fără server, ceea ce înseamnă că Google gestionează dinamic alocarea resurselor mașinii. Prin urmare, toate deciziile de gestionare a resurselor sunt ascunse utilizatorului.
BigQuery permite clienților să încarce date din stocarea în Cloud Google și din alte surse de date lizibile. Opțiunea alternativă este de a transmite date, ceea ce permite dezvoltatorilor să adauge date în depozitul de date în timp real, rând cu rând, pe măsură ce devin disponibile.
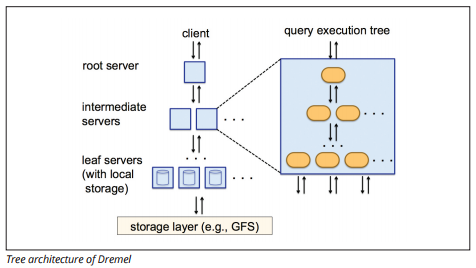
BigQuery folosește un motor de execuție a interogărilor numit Dremel, care poate scana miliarde de rânduri de date în doar câteva secunde. Dremel utilizează interogări masive paralele pentru a scana datele din sistemul de gestionare a fișierelor Colossus. Colossus distribuie fișiere în bucăți de 64 megaocteți printre multe resurse de calcul numite noduri, care sunt grupate în clustere.
Dremel folosește o structură de date coloană, similară cu Redshift. O arhitectură copac expediază interogări printre mii de mașini în câteva secunde.
sursa imaginii
comenzile SQL simple sunt utilizate pentru a efectua interogări asupra datelor.
panoplia
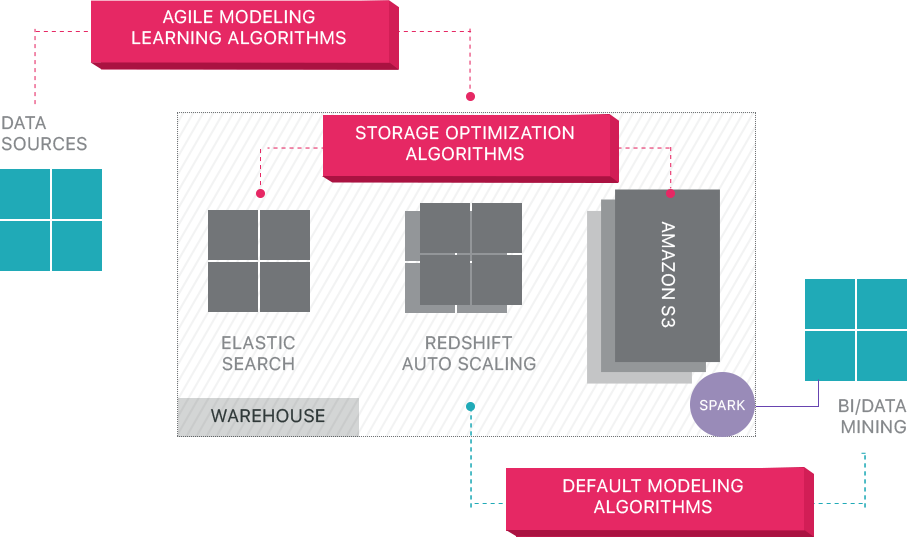
panoplia oferă gestionarea datelor end-to-end ca serviciu. Arhitectura sa unică de auto-optimizare utilizează învățarea automată și procesarea limbajului natural (NLP) pentru a modela și eficientiza călătoria datelor de la sursă la analiză, reducând timpul de la date la valoare cât mai aproape de nici unul.
infrastructura inteligentă de date Panoply include următoarele caracteristici:
- analiza interogărilor și a datelor – identificarea celei mai bune configurații pentru fiecare caz de utilizare, ajustarea acestuia în timp și construirea indexurilor, sortkeys, diskeys, tipuri de date, aspirare și partiționare.
- identificarea interogărilor care nu respectă cele mai bune practici – cum ar fi cele care includ bucle imbricate sau turnare implicită – și le rescrie la o interogare echivalentă care necesită o fracțiune din runtime sau resurse.
- optimizarea configurațiilor serverului în timp pe baza modelelor de interogare și prin învățarea configurării serverului care funcționează cel mai bine. Platforma comută tipurile de servere fără probleme și măsoară performanța rezultată.
dincolo de depozitele de date Cloud
depozitele de date bazate pe Cloud reprezintă un mare pas înainte față de arhitecturile tradiționale. Cu toate acestea, utilizatorii se confruntă în continuare cu mai multe provocări atunci când le configurează:
- încărcarea datelor în depozitele de date cloud nu este banală, iar pentru conductele de date la scară largă, necesită configurarea, testarea și menținerea unui proces ETL. Această parte a procesului se face de obicei cu instrumente terțe.
- actualizări, upserts, și ștergeri poate fi dificil și trebuie să fie făcut cu atenție pentru a preveni degradarea în performanță interogare.
- datele semi-structurate sunt dificil de tratat – trebuie normalizate într-un format de bază de date relațională, care necesită automatizare pentru fluxuri mari de date.
- structurile imbricate nu sunt de obicei acceptate în depozitele de date cloud. Va trebui să aplatizați tabelele imbricate într-un format pe care depozitul de date îl poate înțelege.
- optimizarea clusterului—există diferite opțiuni pentru configurarea unui cluster Redshift pentru a rula sarcinile de lucru. Diferite sarcini de lucru, seturi de date sau chiar diferite tipuri de interogări pot necesita o configurare diferită. Pentru a rămâne optim, va trebui să revizuiască continuu și tweak configurarea.
- optimizarea interogărilor—este posibil ca interogările utilizatorilor să nu urmeze cele mai bune practici și, prin urmare, va dura mult mai mult pentru a rula. S-ar putea să lucrați cu utilizatori sau aplicații client automate pentru a optimiza interogările, astfel încât depozitul de date să poată funcționa conform așteptărilor.
- Backup și recuperare—în timp ce furnizorii de depozite de date oferă numeroase opțiuni pentru copierea de rezervă a datelor dvs., acestea nu sunt banale de configurat și necesită monitorizare și atenție deosebită.
Panoply este un depozit de date inteligent care adaugă un strat de automatizare care se ocupă de toate sarcinile complexe de mai sus, economisind timp prețios și ajutându-vă să obțineți de la date la informații în câteva minute.
Aflați mai multe despre instrumentele Panoply smart Data warehouse.
Aflați mai multe despre depozitele de date
- conceptele depozitului de date: tradițional vs. Cloud
- baza de Date vs. Data Warehouse
- Data Mart vs. Data Warehouse
- Amazon Redshift Architecture