Ein Data Warehouse ist ein elektronisches System, das Daten aus einer Vielzahl von Quellen innerhalb eines Unternehmens sammelt und die Daten zur Unterstützung der Entscheidungsfindung des Managements verwendet.
Unternehmen setzen zunehmend auf Cloud-basierte Data Warehouses anstelle von traditionellen On-Premise-Systemen. Cloud-basierte Data Warehouses unterscheiden sich von herkömmlichen Warehouses auf folgende Weise:
- Es besteht keine Notwendigkeit, physische Hardware zu kaufen.
- Die Einrichtung und Skalierung von Cloud Data Warehouses ist schneller und kostengünstiger.
- Cloud-basierte Data-Warehouse-Architekturen können komplexe analytische Abfragen in der Regel viel schneller durchführen, da sie Massively Parallel Processing (MPP) verwenden.
Der Rest dieses Artikels behandelt die traditionelle Data Warehouse-Architektur und stellt einige architektonische Ideen und Konzepte vor, die von den beliebtesten Cloud-basierten Data Warehouse-Diensten verwendet werden.
Weitere Informationen finden Sie auf unserer Seite zu Data Warehouse-Konzepten in diesem Handbuch.
- Traditionelle Data Warehouse-Architektur
- Dreistufige Architektur
- Kimball vs. Inmon
- Data Warehouse-Modelle
- Star Schema vs. Snowflake Schema
- ETL vs. ELT
- Organisatorische Reife
- Neue Data Warehouse-Architekturen
- Amazon Redshift
- Google BigQuery
- Panoply
- Jenseits von Cloud Data Warehouses
- Erfahren Sie mehr über Data Warehouses
Traditionelle Data Warehouse-Architektur
Die folgenden Konzepte beleuchten einige der etablierten Ideen und Designprinzipien, die für den Aufbau traditioneller Data Warehouses verwendet werden.
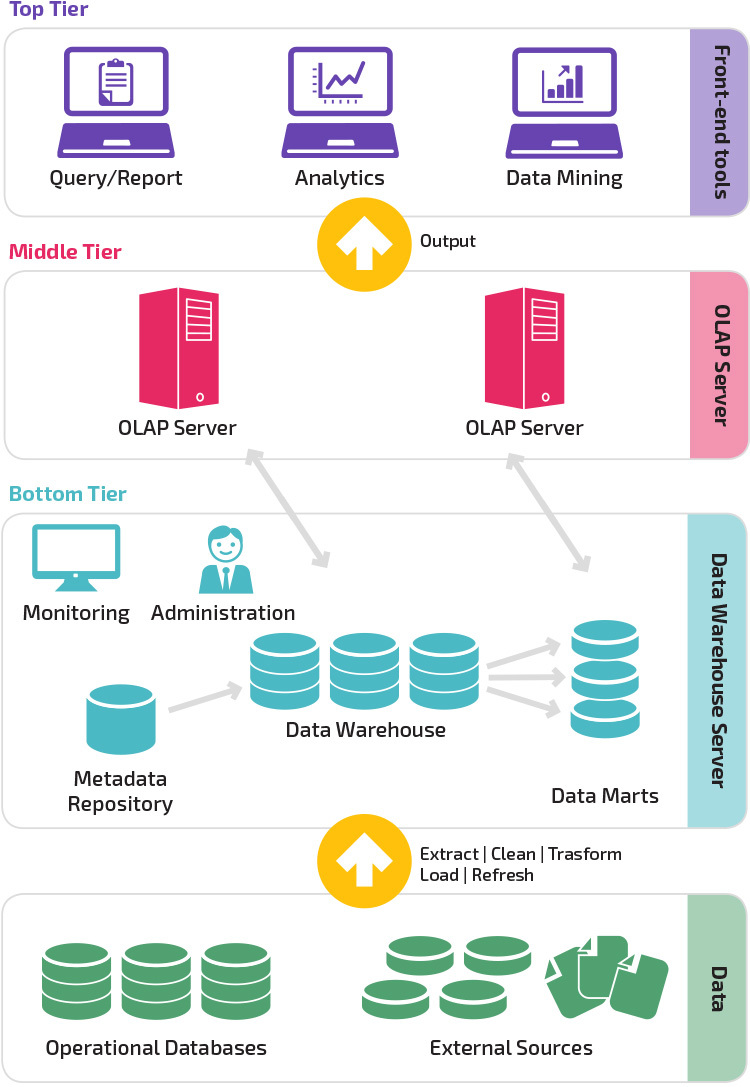
Dreistufige Architektur
Die traditionelle Data Warehouse-Architektur verwendet eine dreistufige Struktur, die sich aus den folgenden Ebenen zusammensetzt.
- Unterste Ebene: Diese Ebene enthält den Datenbankserver, der zum Extrahieren von Daten aus vielen verschiedenen Quellen verwendet wird, z. B. aus Transaktionsdatenbanken, die für Front-End-Anwendungen verwendet werden.
- Mittlere Stufe: Die mittlere Ebene beherbergt einen OLAP-Server, der die Daten in eine Struktur umwandelt, die besser für Analysen und komplexe Abfragen geeignet ist. Der OLAP-Server kann auf zwei Arten arbeiten: entweder als erweitertes relationales Datenbankverwaltungssystem, das die Vorgänge für mehrdimensionale Daten relationalen Standardvorgängen zuordnet (relationales OLAP), oder mit einem mehrdimensionalen OLAP-Modell, das die mehrdimensionalen Daten und Vorgänge direkt implementiert.
- Oberste Ebene: Die oberste Ebene ist die Client-Ebene. Diese Ebene enthält die Tools, die für die Datenanalyse auf hoher Ebene, das Abfragen von Berichten und das Data Mining verwendet werden.
Kimball vs. Inmon
Zwei Pioniere des Data Warehousing namens Bill Inmon und Ralph Kimball hatten unterschiedliche Ansätze für das Data Warehouse-Design.
Ralph Kimballs Ansatz betonte die Bedeutung von Data Marts, die Repositories von Daten sind, die zu bestimmten Geschäftsbereichen gehören. Das Data Warehouse ist einfach eine Kombination verschiedener Data Marts, die das Reporting und die Analyse erleichtert. Das Kimball Data Warehouse-Design verwendet einen „Bottom-up“ -Ansatz.
Bill Inmon betrachtete das Data Warehouse als zentrales Repository für alle Unternehmensdaten. Bei diesem Ansatz erstellt eine Organisation zunächst ein normalisiertes Data Warehouse-Modell. Basierend auf dem Lagermodell werden dann dimensionale Data Marts erstellt. Dies wird als Top-Down-Ansatz für Data Warehousing bezeichnet.
Data Warehouse-Modelle
In einer traditionellen Architektur gibt es drei gängige Data Warehouse-Modelle: Virtual Warehouse, Data Mart und Enterprise Data Warehouse:
- Ein virtuelles Data Warehouse ist ein Satz separater Datenbanken, die zusammen abgefragt werden können, sodass ein Benutzer effektiv auf alle Daten zugreifen kann, als wären sie in einem Data Warehouse gespeichert.
- Ein Data-Mart-Modell wird für geschäftsbereichsspezifische Berichte und Analysen verwendet. In diesem Data-Warehouse-Modell werden Daten aus einer Reihe von Quellsystemen aggregiert, die für einen bestimmten Geschäftsbereich relevant sind, z. B. Vertrieb oder Finanzen.
- Ein Enterprise Data Warehouse-Modell schreibt vor, dass das Data Warehouse aggregierte Daten enthält, die sich über die gesamte Organisation erstrecken. Dieses Modell sieht das Data Warehouse als Herzstück des Informationssystems des Unternehmens mit integrierten Daten aus allen Geschäftsbereichen.
Star Schema vs. Snowflake Schema
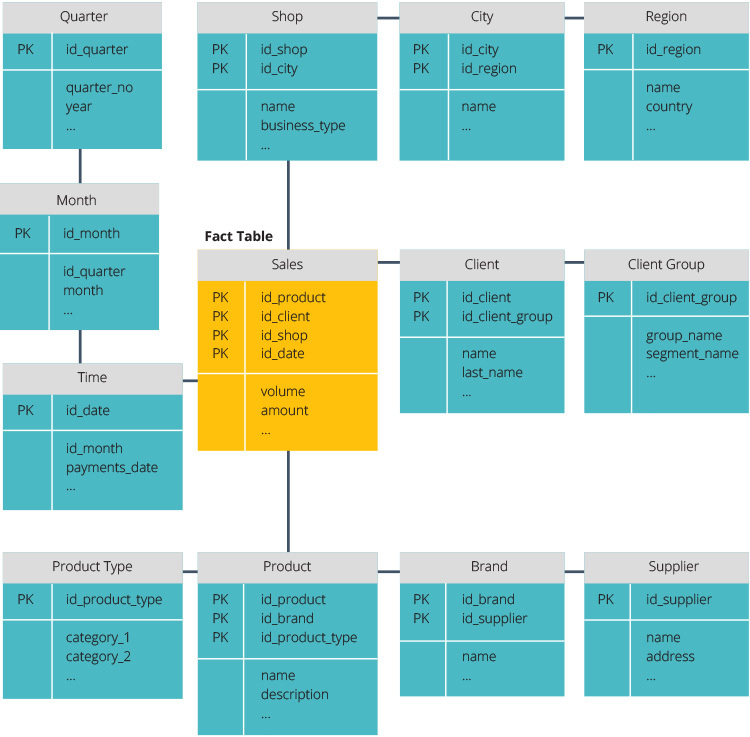
Das Star Schema und das Snowflake Schema sind zwei Möglichkeiten, ein Data Warehouse zu strukturieren.
Das Sternschema verfügt über ein zentrales Datenrepository, das in einer Faktentabelle gespeichert ist. Das Schema teilt die Faktentabelle in eine Reihe von denormalisierten Dimensionstabellen auf. Die Faktentabelle enthält aggregierte Daten, die für Berichtszwecke verwendet werden sollen, während die Dimensionstabelle die gespeicherten Daten beschreibt.
Denormalisierte Designs sind weniger komplex, da die Daten gruppiert sind. Die Faktentabelle verwendet nur einen Link, um jeder Dimensionstabelle beizutreten. Das einfachere Design des Sternschemas erleichtert das Schreiben komplexer Abfragen erheblich.
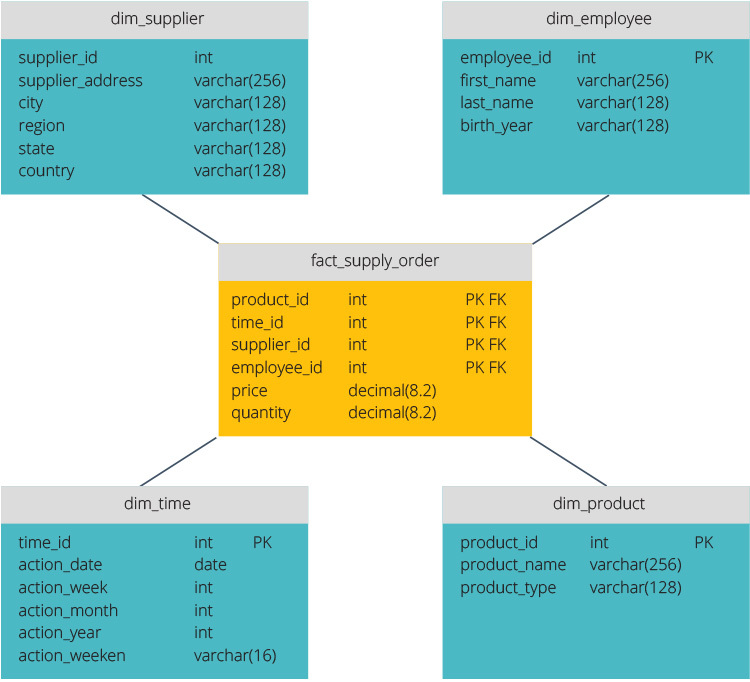
Das Snowflake-Schema unterscheidet sich, da es die Daten normalisiert. Normalisierung bedeutet, die Daten effizient zu organisieren, so dass alle Datenabhängigkeiten definiert sind und jede Tabelle minimale Redundanzen enthält. Einzelne Dimensionstabellen verzweigen sich somit in separate Dimensionstabellen.
Das Snowflake-Schema benötigt weniger Speicherplatz und bewahrt die Datenintegrität besser. Der Hauptnachteil ist die Komplexität der Abfragen, die für den Zugriff auf Daten erforderlich sind – jede Abfrage muss tief graben, um zu den relevanten Daten zu gelangen, da mehrere Verknüpfungen vorhanden sind.
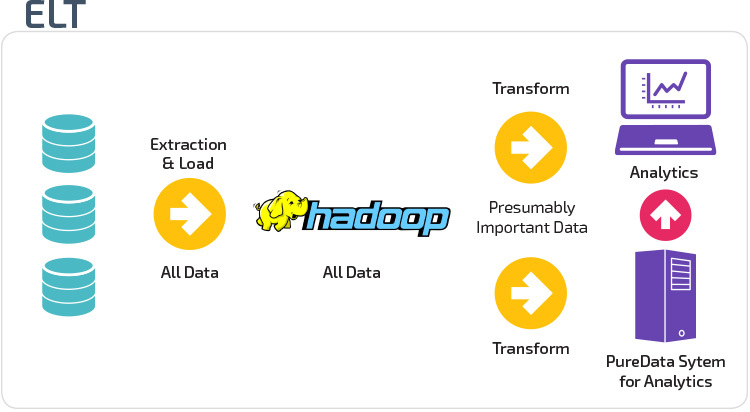
ETL vs. ELT
ETL und ELT sind zwei verschiedene Methoden zum Laden von Daten in ein Warehouse.
Extract, Transform, Load (ETL) extrahiert zunächst die Daten aus einem Pool von Datenquellen, bei denen es sich in der Regel um Transaktionsdatenbanken handelt. Die Daten werden in einer temporären Staging-Datenbank gespeichert. Anschließend werden Transformationsvorgänge durchgeführt, um die Daten zu strukturieren und in eine geeignete Form für das Ziel-Data-Warehouse-System zu konvertieren. Die strukturierten Daten werden dann in das Lager geladen, bereit für die Analyse.
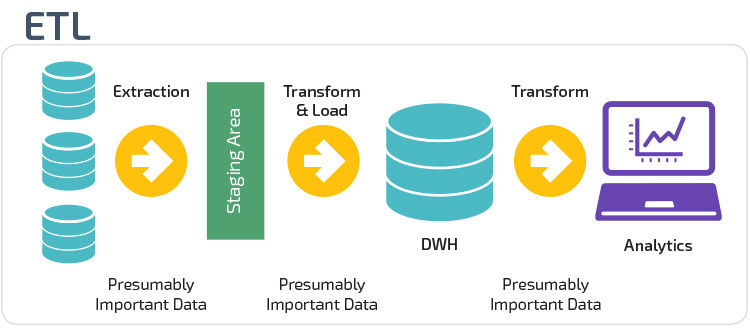
Mit Extract Load Transform (ELT) werden Daten sofort nach dem Extrahieren aus den Quelldatenpools geladen. Es gibt keine Staging-Datenbank, was bedeutet, dass die Daten sofort in das einzige, zentrale Repository geladen werden. Die Daten werden innerhalb des Data Warehouse-Systems für die Verwendung mit Business Intelligence-Tools und Analysen transformiert.
Organisatorische Reife
Die Struktur des Data Warehouse einer Organisation hängt auch von ihrer aktuellen Situation und ihren Bedürfnissen ab.
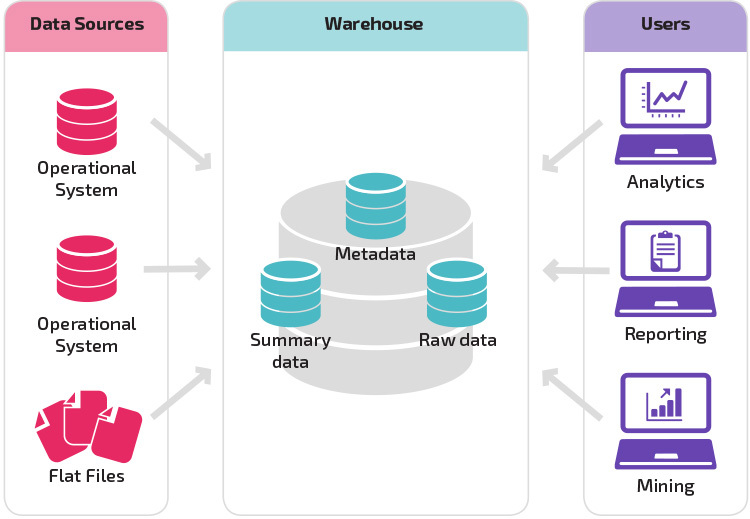
Mit der Grundstruktur können Endbenutzer des Lagers direkt auf zusammenfassende Daten zugreifen, die von Quellsystemen abgeleitet wurden, und Analysen, Berichte und Mining dieser Daten durchführen. Diese Struktur ist nützlich, wenn Datenquellen von denselben Arten von Datenbanksystemen stammen.
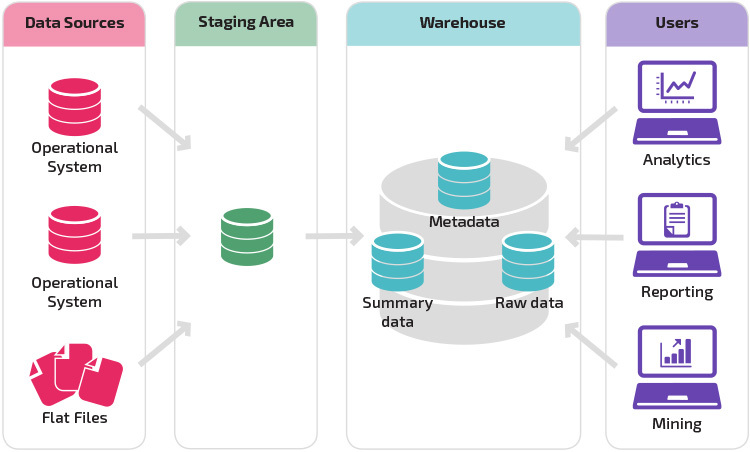
Ein Warehouse mit einem Staging-Bereich ist der nächste logische Schritt in einer Organisation mit unterschiedlichen Datenquellen mit vielen verschiedenen Datentypen und -formaten. Der Staging-Bereich konvertiert die Daten in ein zusammengefasstes strukturiertes Format, das mit Analyse- und Berichterstellungstools einfacher abgefragt werden kann.
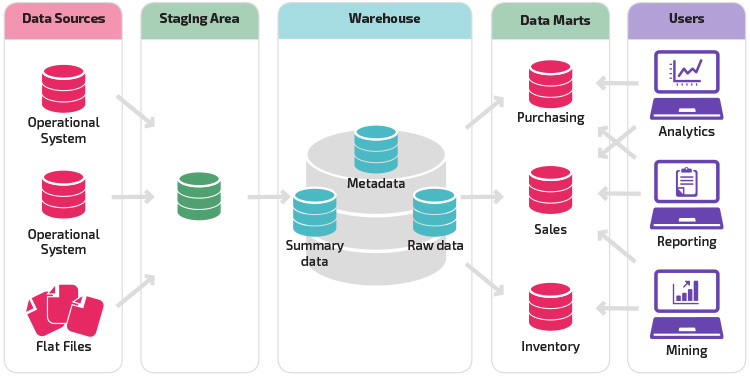
Eine Variation der Staging-Struktur ist das Hinzufügen von Data Marts zum Data Warehouse. Die Data Marts speichern zusammengefasste Daten für einen bestimmten Geschäftsbereich und machen diese Daten für bestimmte Analyseformen leicht zugänglich. Beispielsweise kann das Hinzufügen von Data Marts es einem Finanzanalysten ermöglichen, detaillierte Abfragen zu Verkaufsdaten einfacher durchzuführen, um Vorhersagen über das Kundenverhalten zu treffen. Data Marts erleichtern die Analyse, indem sie Daten speziell an die Bedürfnisse des Endbenutzers anpassen.
Neue Data Warehouse-Architekturen
In den letzten Jahren sind Data Warehouses in die Cloud umgezogen. Die neuen Cloud-basierten Data Warehouses halten sich nicht an die traditionelle Architektur; Jedes Data Warehouse-Angebot hat eine einzigartige Architektur.
Dieser Abschnitt fasst die Architekturen zusammen, die von zwei der beliebtesten Cloud-basierten Warehouses verwendet werden: Amazon Redshift und Google BigQuery.
Amazon Redshift
Amazon Redshift ist eine cloudbasierte Darstellung eines traditionellen Data Warehouses.
Redshift erfordert die Bereitstellung und Einrichtung von Rechenressourcen in Form von Clustern, die eine Sammlung von einem oder mehreren Knoten enthalten. Jeder Knoten verfügt über eine eigene CPU, Speicher und RAM. Ein Leader-Knoten kompiliert Abfragen und überträgt sie an Compute-Knoten, die die Abfragen ausführen.
Auf jedem Knoten werden Daten in Blöcken gespeichert, die als Slices bezeichnet werden. Redshift verwendet einen spaltenartigen Speicher, d. h. jeder Datenblock enthält Werte aus einer einzelnen Spalte in einer Reihe von Zeilen anstelle einer einzelnen Zeile mit Werten aus mehreren Spalten.
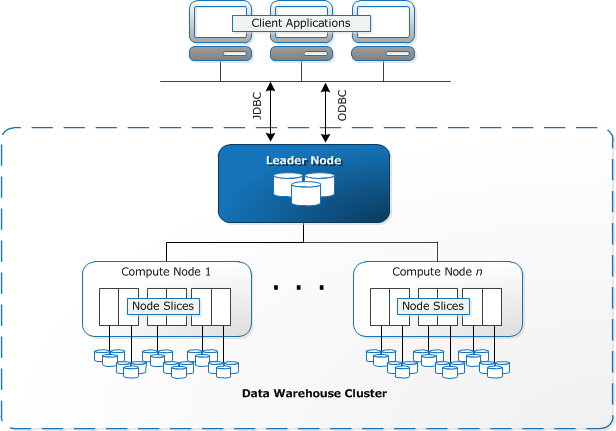
Quelle: AWS-Dokumentation
Redshift verwendet eine MPP-Architektur, die große Datensätze in Blöcke aufteilt, die Slices innerhalb jedes Knotens zugewiesen werden. Abfragen werden schneller ausgeführt, da die Rechenknoten Abfragen in jedem Slice gleichzeitig verarbeiten. Der Leader-Knoten aggregiert die Ergebnisse und gibt sie an die Clientanwendung zurück.
Clientanwendungen wie BI- und Analysetools können mithilfe von Open-Source-PostgreSQL-JDBC- und ODBC-Treibern direkt eine Verbindung zu Redshift herstellen. Analysten können so ihre Aufgaben direkt an den Redshift-Daten ausführen.
Redshift kann nur strukturierte Daten laden. Es ist möglich, Daten mit vorintegrierten Systemen wie Amazon S3 und DynamoDB auf Redshift zu laden, indem Daten von einem beliebigen lokalen Host mit SSH-Konnektivität übertragen oder andere Datenquellen mithilfe der Redshift-API integriert werden.
Google BigQuery
Die Architektur von BigQuery ist serverlos, was bedeutet, dass Google die Zuweisung von Maschinenressourcen dynamisch verwaltet. Alle Entscheidungen des Ressourcenmanagements sind daher für den Benutzer verborgen.
Mit BigQuery können Clients Daten aus Google Cloud Storage und anderen lesbaren Datenquellen laden. Die Alternative besteht darin, Daten zu streamen, sodass Entwickler Daten in Echtzeit Zeile für Zeile zum Data Warehouse hinzufügen können, sobald sie verfügbar sind.
BigQuery verwendet eine Abfrageausführungs-Engine namens Dremel, die Milliarden von Datenzeilen in nur wenigen Sekunden scannen kann. Dremel verwendet massiv parallele Abfragen, um Daten im zugrunde liegenden Colossus-Dateiverwaltungssystem zu scannen. Colossus verteilt Dateien in Blöcken von 64 Megabyte auf viele Computerressourcen namens Knoten, die in Clustern gruppiert sind.
Dremel verwendet eine spaltenförmige Datenstruktur, ähnlich der Rotverschiebung. Eine Baumarchitektur sendet Abfragen unter Tausenden von Maschinen in Sekunden.
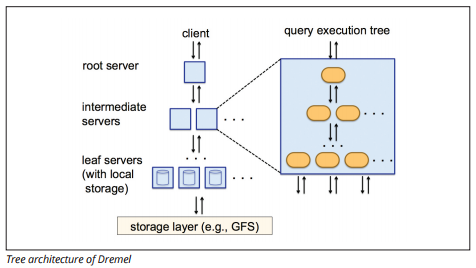
Bildquelle
Einfache SQL-Befehle werden verwendet, um Abfragen auf Daten durchzuführen.
Panoply
Panoply bietet End-to-End-Datenmanagement als Service. Seine einzigartige selbstoptimierende Architektur nutzt maschinelles Lernen und Natural Language Processing (NLP), um die Datenreise von der Quelle bis zur Analyse zu modellieren und zu rationalisieren und die Zeit von den Daten bis zum Wert so nah wie möglich zu verkürzen.
Die Smart Data Infrastructure von Panoply umfasst die folgenden Funktionen:
- Analysieren von Abfragen und Daten – Ermitteln der besten Konfiguration für jeden Anwendungsfall, Anpassen im Laufe der Zeit und Erstellen von Indizes, Sortierschlüsseln, Disketten, Datentypen, Staubsaugen und Partitionieren.
- Identifizieren von Abfragen, die nicht den Best Practices folgen– z. B. solche, die verschachtelte Schleifen oder implizites Casting enthalten, und schreiben sie in eine äquivalente Abfrage um, die einen Bruchteil der Laufzeit oder der Ressourcen erfordert.
- Optimieren von Serverkonfigurationen im Laufe der Zeit basierend auf Abfragemustern und indem Sie lernen, welches Server-Setup am besten funktioniert. Die Plattform wechselt nahtlos zwischen den Servertypen und misst die resultierende Leistung.
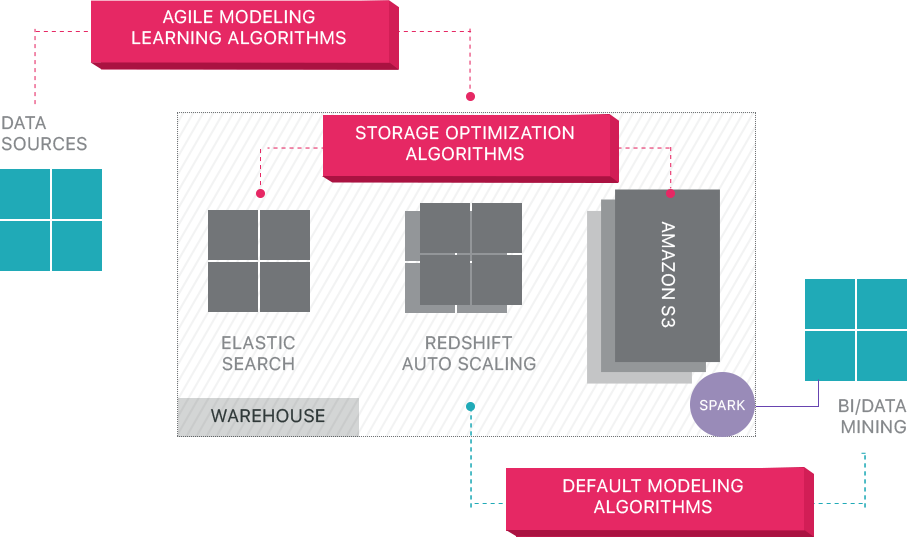
Jenseits von Cloud Data Warehouses
Cloud-basierte Data Warehouses sind ein großer Fortschritt gegenüber herkömmlichen Architekturen. Benutzer stehen jedoch beim Einrichten immer noch vor mehreren Herausforderungen:
- Das Laden von Daten in Cloud Data Warehouses ist nicht trivial und erfordert für große Datenpipelines das Einrichten, Testen und Verwalten eines ETL-Prozesses. Dieser Teil des Prozesses wird normalerweise mit Tools von Drittanbietern durchgeführt.
- Aktualisierungen, Upserts und Löschungen können schwierig sein und müssen sorgfältig durchgeführt werden, um eine Verschlechterung der Abfrageleistung zu verhindern.
- Halbstrukturierte Daten sind schwierig zu verarbeiten – sie müssen in ein relationales Datenbankformat normalisiert werden, was eine Automatisierung für große Datenströme erfordert.
- Verschachtelte Strukturen werden in Cloud Data Warehouses normalerweise nicht unterstützt. Sie müssen verschachtelte Tabellen in ein Format reduzieren, das das Data Warehouse verstehen kann.
- Optimieren Ihres Clusters – Es gibt verschiedene Optionen zum Einrichten eines Redshift-Clusters zum Ausführen Ihrer Workloads. Unterschiedliche Workloads, Datensätze oder sogar verschiedene Arten von Abfragen erfordern möglicherweise ein anderes Setup. Um optimal zu bleiben, müssen Sie Ihr Setup ständig überprüfen und optimieren.
- Abfrageoptimierung – Benutzerabfragen folgen möglicherweise nicht den Best Practices und dauern daher viel länger. Möglicherweise arbeiten Sie mit Benutzern oder automatisierten Clientanwendungen zusammen, um Abfragen so zu optimieren, dass das Data Warehouse wie erwartet ausgeführt werden kann.
- Sicherung und Wiederherstellung — Die Data Warehouse-Anbieter bieten zwar zahlreiche Optionen zum Sichern Ihrer Daten, sind jedoch nicht trivial einzurichten und erfordern Überwachung und genaue Aufmerksamkeit.
Panoply ist ein intelligentes Data Warehouse, das eine Automatisierungsebene hinzufügt, die sich um alle oben genannten komplexen Aufgaben kümmert, wertvolle Zeit spart und Ihnen hilft, in wenigen Minuten von Daten zu Erkenntnissen zu gelangen.
Erfahren Sie mehr über die intelligenten Data Warehouse-Tools von Panoply.
Erfahren Sie mehr über Data Warehouses
- Data Warehouse-Konzepte: Traditionell vs. Cloud
- Datenbank vs. Data Warehouse
- Data Mart vs. Data Warehouse
- Amazon Redshift-Architektur