Un data warehouse è un sistema elettronico che raccoglie dati da una vasta gamma di fonti all’interno di un’azienda e utilizza i dati per supportare il processo decisionale della gestione.
Le aziende si stanno sempre più orientando verso data warehouse basati su cloud invece dei tradizionali sistemi on-premise. I data warehouse basati su cloud differiscono dai magazzini tradizionali nei seguenti modi:
- Non è necessario acquistare hardware fisico.
- È più veloce ed economico configurare e scalare i data warehouse cloud.
- Le architetture di data warehouse basate su cloud possono in genere eseguire query analitiche complesse molto più velocemente perché utilizzano MPP (Massively Parallel Processing).
Il resto di questo articolo copre l’architettura tradizionale del data warehouse e introduce alcune idee e concetti architettonici utilizzati dai più popolari servizi di data warehouse basati su cloud.
Per maggiori dettagli, vedere la nostra pagina sui concetti di data warehouse in questa guida.
- Architettura di Data Warehouse tradizionale
- Architettura a tre livelli
- Kimball vs. Inmon
- Modelli di data Warehouse
- Schema stella vs Schema Fiocco di neve
- ETL vs. ELT
- Maturità organizzativa
- Nuove architetture di Data Warehouse
- Amazon Redshift
- Google BigQuery
- Panoply
- Oltre i data Warehouse cloud
- Ulteriori informazioni sui data Warehouse
Architettura di Data Warehouse tradizionale
I seguenti concetti evidenziano alcune delle idee consolidate e dei principi di progettazione utilizzati per la costruzione di data warehouse tradizionali.
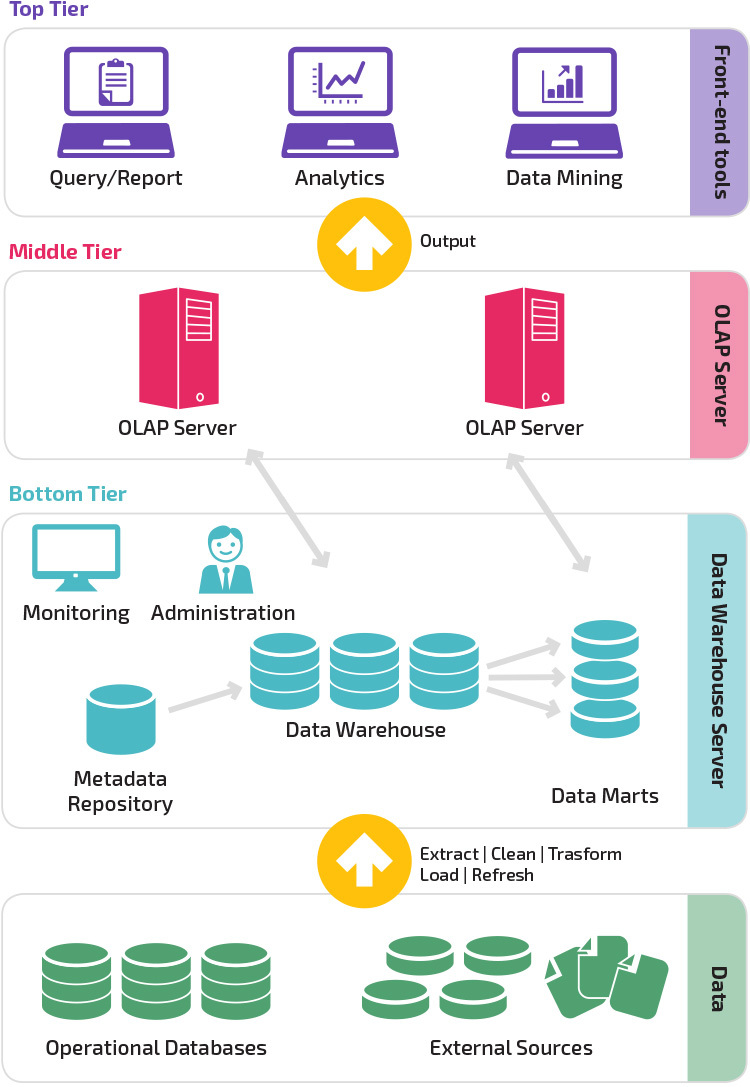
Architettura a tre livelli
L’architettura tradizionale del data warehouse impiega una struttura a tre livelli composta dai seguenti livelli.
- Livello inferiore: questo livello contiene il server di database utilizzato per estrarre dati da molte origini diverse, ad esempio da database transazionali utilizzati per applicazioni front-end.
- Livello intermedio: Il livello intermedio ospita un server OLAP, che trasforma i dati in una struttura più adatta per l’analisi e query complesse. Il server OLAP può funzionare in due modi: o come un sistema di gestione di database relazionale esteso che mappa le operazioni su dati multidimensionali a operazioni relazionali standard (OLAP relazionale), o utilizzando un modello OLAP multidimensionale che implementa direttamente i dati e le operazioni multidimensionali.
- Livello superiore: il livello superiore è il livello client. Questo livello contiene gli strumenti utilizzati per l’analisi dei dati di alto livello, l’interrogazione dei report e il data mining.
Kimball vs. Inmon
Due pionieri del data warehousing chiamati Bill Inmon e Ralph Kimball avevano approcci diversi alla progettazione del data warehouse.
L’approccio di Ralph Kimball ha sottolineato l’importanza dei data mart, che sono archivi di dati appartenenti a particolari linee di business. Il data warehouse è semplicemente una combinazione di diversi data mart che facilita il reporting e l’analisi. Il design del data warehouse di Kimball utilizza un approccio “bottom-up”.
Bill Inmon considerava il data warehouse come il repository centralizzato per tutti i dati aziendali. In questo approccio, un’organizzazione crea innanzitutto un modello di data warehouse normalizzato. I data mart dimensionali vengono quindi creati in base al modello di magazzino. Questo è noto come un approccio top-down al data warehousing.
Modelli di data Warehouse
In un’architettura tradizionale esistono tre modelli comuni di data warehouse: virtual warehouse, data mart e enterprise data warehouse:
- Un data warehouse virtuale è un insieme di database separati, che possono essere interrogati insieme, in modo che un utente possa accedere efficacemente a tutti i dati come se fossero memorizzati in un data warehouse.
- Un modello di data mart viene utilizzato per la reportistica e l’analisi specifiche della linea di business. In questo modello di data warehouse, i dati vengono aggregati da una serie di sistemi di origine rilevanti per una specifica area di business, ad esempio vendite o finanza.
- Un modello di data warehouse aziendale prescrive che il data warehouse contenga dati aggregati che coprono l’intera organizzazione. Questo modello vede il data warehouse come il cuore del sistema informativo aziendale, con dati integrati da tutte le business unit.
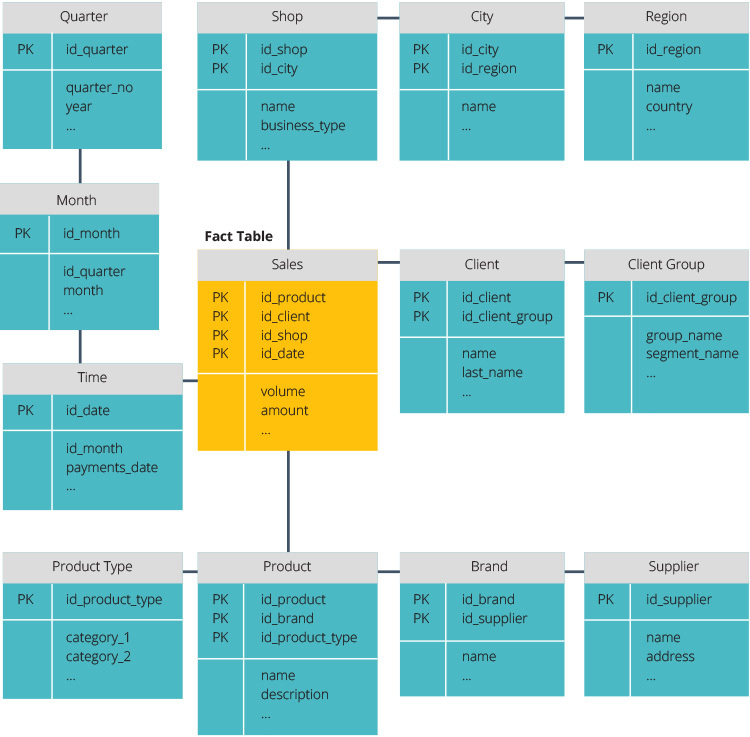
Schema stella vs Schema Fiocco di neve
Lo schema stella e lo schema fiocco di neve sono due modi per strutturare un data warehouse.
Lo schema star ha un repository di dati centralizzato, memorizzato in una tabella dei fatti. Lo schema divide la tabella dei fatti in una serie di tabelle di dimensioni denormalizzate. La tabella dei fatti contiene dati aggregati da utilizzare a fini di reporting, mentre la tabella delle dimensioni descrive i dati memorizzati.
I progetti denormalizzati sono meno complessi perché i dati sono raggruppati. La tabella dei fatti utilizza un solo collegamento per unirsi a ciascuna tabella delle dimensioni. Il design più semplice dello schema a stella rende molto più facile scrivere query complesse.
Lo schema del fiocco di neve è diverso perché normalizza i dati. Normalizzazione significa organizzare in modo efficiente i dati in modo da definire tutte le dipendenze dei dati e ogni tabella contiene ridondanze minime. Le tabelle di dimensione singola si diramano quindi in tabelle di dimensione separate.
Lo schema snowflake utilizza meno spazio su disco e preserva meglio l’integrità dei dati. Lo svantaggio principale è la complessità delle query necessarie per accedere ai dati: ogni query deve scavare in profondità per raggiungere i dati rilevanti perché ci sono più join.
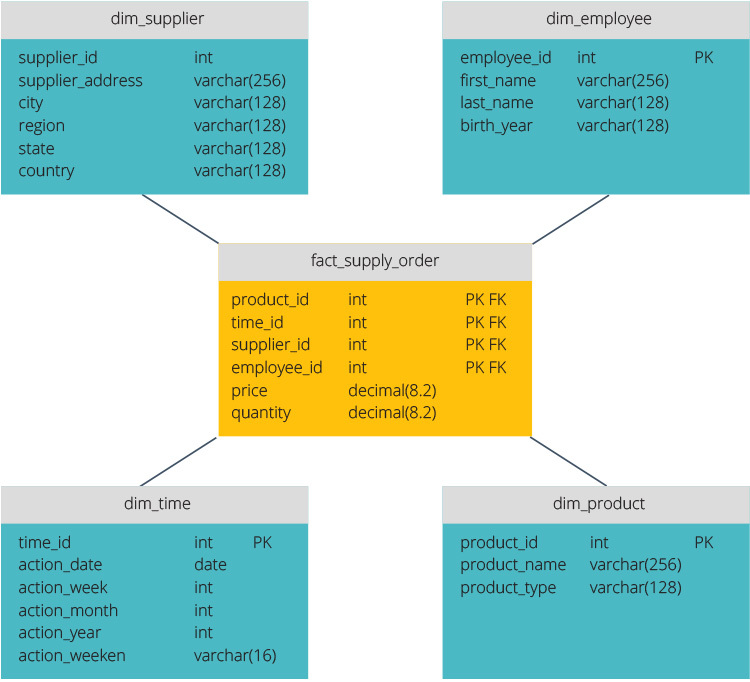
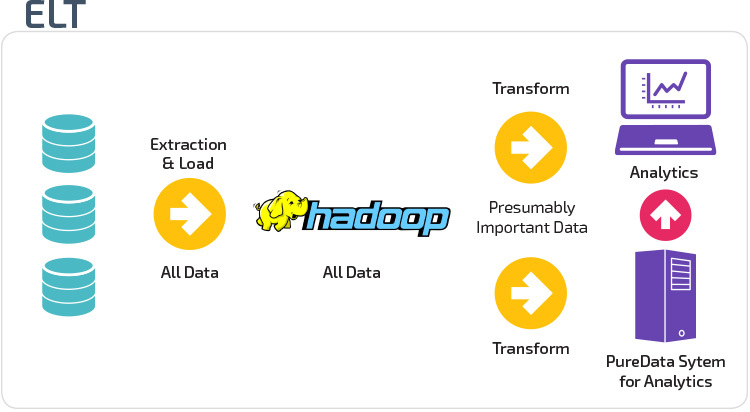
ETL vs. ELT
ETL ed ELT sono due diversi metodi di caricamento dei dati in un magazzino.
Extract, Transform, Load (ETL) estrae prima i dati da un pool di origini dati, che in genere sono database transazionali. I dati sono conservati in un database di staging temporaneo. Vengono quindi eseguite operazioni di trasformazione, per strutturare e convertire i dati in una forma adatta per il sistema di data warehouse di destinazione. I dati strutturati vengono quindi caricati nel magazzino, pronti per l’analisi.
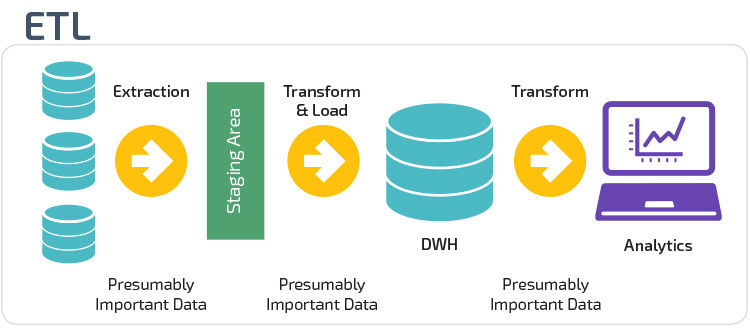
Con Extract Load Transform (ELT), i dati vengono immediatamente caricati dopo essere stati estratti dai pool di dati di origine. Non esiste un database di staging, il che significa che i dati vengono immediatamente caricati nel singolo repository centralizzato. I dati vengono trasformati all’interno del sistema di data warehouse per l’utilizzo con strumenti di business intelligence e analisi.
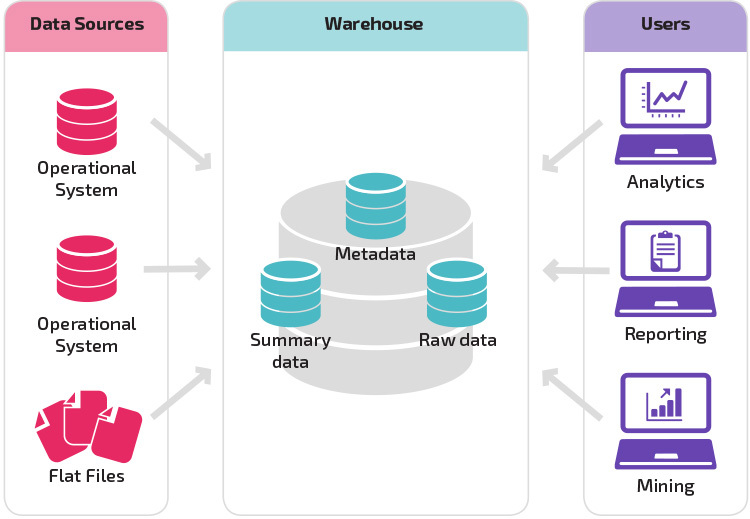
Maturità organizzativa
La struttura del data warehouse di un’organizzazione dipende anche dalla situazione e dalle esigenze attuali.
La struttura di base consente agli utenti finali del magazzino di accedere direttamente ai dati di riepilogo derivati dai sistemi di origine ed eseguire analisi, reporting e mining su tali dati. Questa struttura è utile per quando le origini dati derivano dagli stessi tipi di sistemi di database.
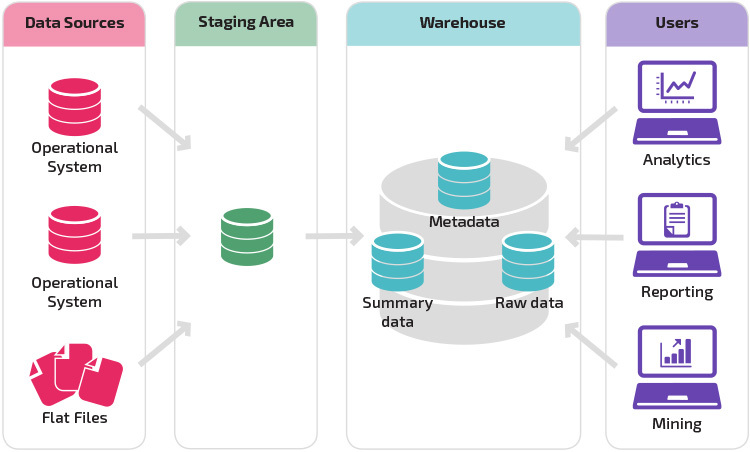
Un magazzino con un’area di staging è il passo logico successivo in un’organizzazione con origini dati disparate con diversi tipi e formati di dati. L’area di staging converte i dati in un formato strutturato di riepilogo che è più facile da interrogare con strumenti di analisi e reporting.
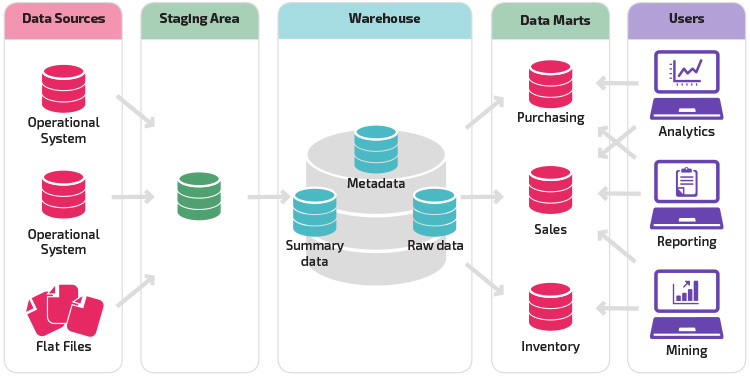
Una variante della struttura di staging è l’aggiunta di data mart al data warehouse. I data mart memorizzano i dati riepilogati per una particolare linea di business, rendendo i dati facilmente accessibili per specifiche forme di analisi. Ad esempio, l’aggiunta di data mart può consentire a un analista finanziario di eseguire più facilmente query dettagliate sui dati di vendita, per fare previsioni sul comportamento dei clienti. I data mart semplificano l’analisi adattando i dati in modo specifico alle esigenze dell’utente finale.
Nuove architetture di Data Warehouse
Negli ultimi anni, i data warehouse si stanno spostando verso il cloud. I nuovi data warehouse basati su cloud non aderiscono all’architettura tradizionale; ogni offerta di data warehouse ha un’architettura unica.
Questa sezione riassume le architetture utilizzate da due dei più diffusi magazzini basati su cloud: Amazon Redshift e Google BigQuery.
Amazon Redshift
Amazon Redshift è una rappresentazione basata su cloud di un data warehouse tradizionale.
Redshift richiede il provisioning e la configurazione delle risorse di calcolo sotto forma di cluster, che contengono una raccolta di uno o più nodi. Ogni nodo ha la propria CPU, storage e RAM. Un nodo leader compila le query e le trasferisce ai nodi di calcolo, che eseguono le query.
Su ogni nodo, i dati vengono memorizzati in blocchi, chiamati sezioni. Redshift utilizza una memoria colonnare, il che significa che ogni blocco di dati contiene valori da una singola colonna su un numero di righe, invece di una singola riga con valori da più colonne.
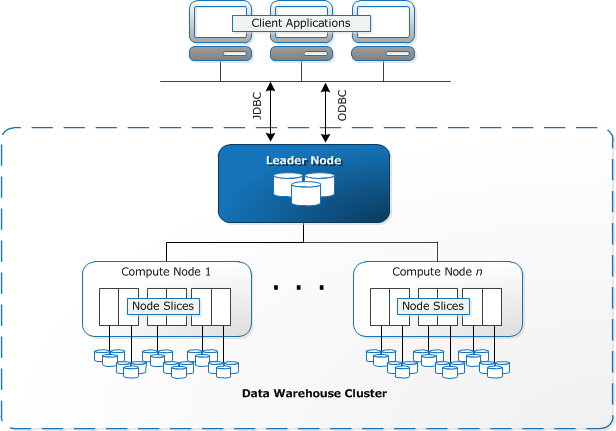
Fonte: AWS Documentation
Redshift utilizza un’architettura MPP, suddividendo set di dati di grandi dimensioni in blocchi assegnati a sezioni all’interno di ciascun nodo. Le query vengono eseguite più velocemente perché i nodi di calcolo elaborano simultaneamente le query in ciascuna sezione. Il Nodo Leader aggrega i risultati e li restituisce all’applicazione client.
Le applicazioni client, come gli strumenti di BI e analisi, possono connettersi direttamente a Redshift utilizzando i driver PostgreSQL JDBC e ODBC open source. Gli analisti possono quindi svolgere le loro attività direttamente sui dati Redshift.
Redshift può caricare solo dati strutturati. È possibile caricare i dati su Redshift utilizzando sistemi pre-integrati tra cui Amazon S3 e DynamoDB, spingendo i dati da qualsiasi host on-premise con connettività SSH o integrando altre origini dati utilizzando l’API Redshift.
Google BigQuery
L’architettura di BigQuery è serverless, il che significa che Google gestisce dinamicamente l’allocazione delle risorse della macchina. Tutte le decisioni di gestione delle risorse sono quindi nascoste all’utente.
BigQuery consente ai clienti di caricare i dati da Google Cloud Storage e altre fonti di dati leggibili. L’opzione alternativa è lo streaming dei dati, che consente agli sviluppatori di aggiungere dati al data warehouse in tempo reale, riga per riga, man mano che diventa disponibile.
BigQuery utilizza un motore di esecuzione di query denominato Dremel, che può eseguire la scansione di miliardi di righe di dati in pochi secondi. Dremel utilizza query massicciamente parallele per scansionare i dati nel sottostante Colossus file management system. Colossus distribuisce i file in blocchi di 64 megabyte tra molte risorse di calcolo denominate nodi, che sono raggruppati in cluster.
Dremel utilizza una struttura dati colonnare, simile a Redshift. Un’architettura ad albero invia query tra migliaia di macchine in pochi secondi.
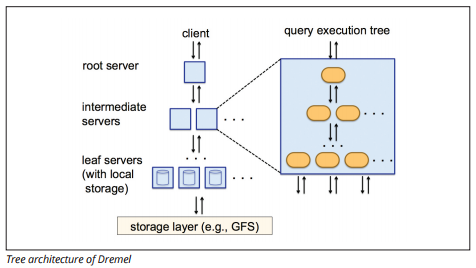
Image source
Semplici comandi SQL vengono utilizzati per eseguire query sui dati.
Panoply
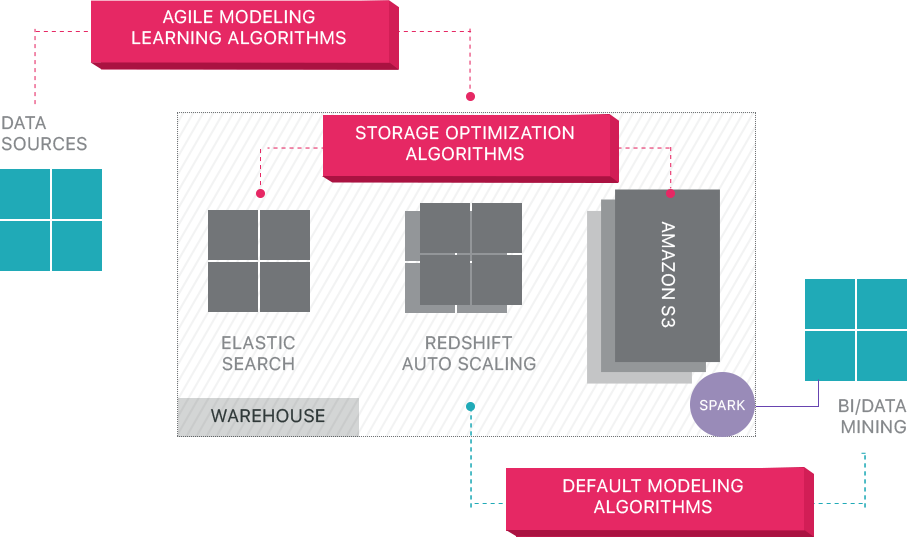
Panoply fornisce la gestione dei dati end-to-end-as-a-service. La sua esclusiva architettura auto-ottimizzante utilizza l’apprendimento automatico e l’elaborazione del linguaggio naturale (NLP) per modellare e semplificare il percorso dei dati dall’origine all’analisi, riducendo il tempo tra dati e valore il più vicino possibile a nessuno.
L’infrastruttura smart data di Panoply include le seguenti funzionalità:
- Analisi di query e dati – identificare la migliore configurazione per ogni caso d’uso, regolandola nel tempo e costruendo indici, sortkeys, diskeys, tipi di dati, aspirapolvere e partizionamento.
- Identificare le query che non seguono le best practice, come quelle che includono loop annidati o casting implicito, e riscriverle in una query equivalente che richiede una frazione del runtime o delle risorse.
- Ottimizzazione delle configurazioni del server nel tempo in base ai modelli di query e imparando quale configurazione del server funziona meglio. La piattaforma cambia i tipi di server senza problemi e misura le prestazioni risultanti.
Oltre i data Warehouse cloud
I data warehouse basati su cloud rappresentano un grande passo avanti rispetto alle architetture tradizionali. Tuttavia, gli utenti devono ancora affrontare diverse sfide durante la loro configurazione:
- Il caricamento dei dati nei data warehouse cloud non è banale e, per le pipeline di dati su larga scala, richiede la configurazione, il test e il mantenimento di un processo ETL. Questa parte del processo viene in genere eseguita con strumenti di terze parti.
- Gli aggiornamenti, gli upsert e le eliminazioni possono essere complicati e devono essere eseguiti con attenzione per prevenire il degrado delle prestazioni delle query.
- I dati semi-strutturati sono difficili da gestire: devono essere normalizzati in un formato di database relazionale, che richiede l’automazione per flussi di dati di grandi dimensioni.
- Le strutture nidificate in genere non sono supportate nei data warehouse cloud. Sarà necessario appiattire le tabelle nidificate in un formato che il data warehouse può comprendere.
- Ottimizzazione del cluster: esistono diverse opzioni per impostare un cluster Redshift per eseguire i carichi di lavoro. Carichi di lavoro diversi, set di dati o anche diversi tipi di query potrebbero richiedere una configurazione diversa. Per rimanere ottimale è necessario rivisitare continuamente e modificare la configurazione.
- Ottimizzazione delle query-le query degli utenti potrebbero non seguire le best practice e, di conseguenza, richiedere molto più tempo per essere eseguite. Potresti trovarti a lavorare con utenti o applicazioni client automatizzate per ottimizzare le query in modo che il data warehouse possa funzionare come previsto.
- Backup e ripristino-mentre i fornitori di data warehouse offrono numerose opzioni per il backup dei dati, non sono banali da configurare e richiedono monitoraggio e attenzione.
Panoply è un Data Warehouse intelligente che aggiunge un livello di automazione che si prende cura di tutte le attività complesse di cui sopra, risparmiando tempo prezioso e ti aiuta a ottenere dai dati alla comprensione in pochi minuti.
Ulteriori informazioni sugli strumenti smart data warehouse di Panoply.
Ulteriori informazioni sui data Warehouse
- Concetti di data Warehouse: tradizionale vs. Cloud
- Database vs Data Warehouse
- Data Mart vs Data Warehouse
- Amazon Redshift Architecture