voordat we weten hoe H. O. G werkt, laat ons weten wat gradiënten in deze context zijn. Neem bijvoorbeeld de volgende afbeelding:
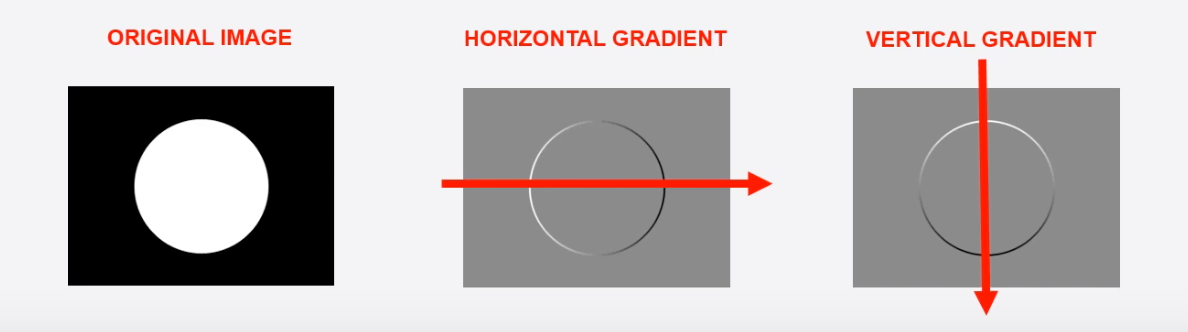
wanneer u van links naar rechts stap voor pixel, zult u merken dat na enkele stappen, er een plotselinge verandering in de pixelwaarde is, dat wil zeggen, van een zwart lager pixelnummer naar een wit hoger pixelnummer. Deze plotselinge verandering in de kleur wordt een gradiënt genoemd en het overgaan van een donkere toon naar een lichtere toon wordt een positieve gradiënt genoemd en vice versa. Van links naar rechts gaan geeft ons het horizontale verloop en zoals verwacht van boven naar beneden een verticaal verloop.
hoe de H. O. G werkt
HOG werkt met een blok dat lijkt op een schuifraam. Een blok wordt beschouwd als een pixelraster waarin gradiënten worden gevormd uit de grootte en richting van verandering in de intensiteit van de pixel binnen het blok.

dingen om op te merken: HOG werkt op grijswaarden afbeeldingen.
1 — dus de eerste stap zou zijn om een RGB-afbeelding te converteren naar grijswaarden.



2 — om een kijkje Te krijgen, laten we ons richten op een raster van grootte 8*8. Kijk naar de volgende foto.

in het blok van 64 pixels worden voor elke pixel horizontale en verticale gradiënten berekend. Net als in de bovenstaande afbeelding worden horizontale en verticale verlopen berekend als:
horizontaal verloop: 120 -70 = 50
verticaal verloop : 100 -50 = 50
3 — Zodra we de gradiënten hebben proberen we iets genaamd gradiënt magnitude en gradiënt hoek te berekenen voor elk van 64 pixels.

nu met die 64 gradiëntvectoren, proberen we ze te comprimeren tot 9 vectoren, om de maximale structuur te behouden. Om dit te doen proberen we een histogram van magnitudes en hoeken te plotten. Hier is de x-as hoeken en ze zijn geboord in 9 bakken elk met een grootte van 20 graden.
opmerking: het maken van 9 bakken wordt beslist door de auteurs van het HOG paper. Dus het is vrijwel overal constant.

de bovenstaande resultaten zijn voor één 8 * 8 raster en we hebben de weergave gecomprimeerd tot 9 vectoren.
4 – als we dat 8*8 raster over de hele afbeelding schuiven en proberen de histogram resultaten te interpreteren krijgen we iets als hieronder.

5 — en door het plotten van de kenmerken van het varken zullen we ontdekken dat de structuur van het object of gezicht goed wordt onderhouden, waardoor alle onbeduidende kenmerken worden verloren.

en dergelijke input kan worden gebruikt door een machine Learning algoritme om de classificatie of regressie te doen.
het is een zeer krachtige techniek die nog steeds wordt gebruikt en objectdetectie kan worden bereikt zonder het gebruik van zware architecturen van DL.
de beste plaats om HOG detectie functionaliteit te krijgen is van de bibliotheek dlib.
Nu u een oude handige tool kent om een afbeelding in een gecomprimeerd formaat weer te geven en nog steeds de structuur ervan behoudt, kunt u dit in veel computer vision use cases opnemen.