tietovarasto on sähköinen järjestelmä, joka kerää tietoa useista eri lähteistä yrityksen sisällä ja käyttää tietoja johdon päätöksenteon tukena.
yritykset ovat siirtymässä yhä enemmän pilvipohjaisiin tietovarastoihin perinteisten toimitilajärjestelmien sijaan. Pilvipohjaiset tietovarastot eroavat perinteisistä varastoista seuraavasti:
- ei ole tarvetta ostaa fyysistä laitteistoa.
- pilvitietovarastojen pystyttäminen ja skaalaaminen on nopeampaa ja halvempaa.
- pilvipohjaiset tietovarasto-arkkitehtuurit voivat tyypillisesti suorittaa monimutkaisia analyyttisiä kyselyjä paljon nopeammin, koska ne käyttävät massiivisesti rinnakkaista käsittelyä (MPP).
tämän artikkelin loppuosa käsittelee perinteistä tietovarastoarkkitehtuuria ja esittelee joitakin arkkitehtonisia ideoita ja konsepteja, joita Suosituimmat pilvipohjaiset tietovarastopalvelut käyttävät.
lisätietoja on tässä oppaassa sivuillamme tietovaraston käsitteistä.
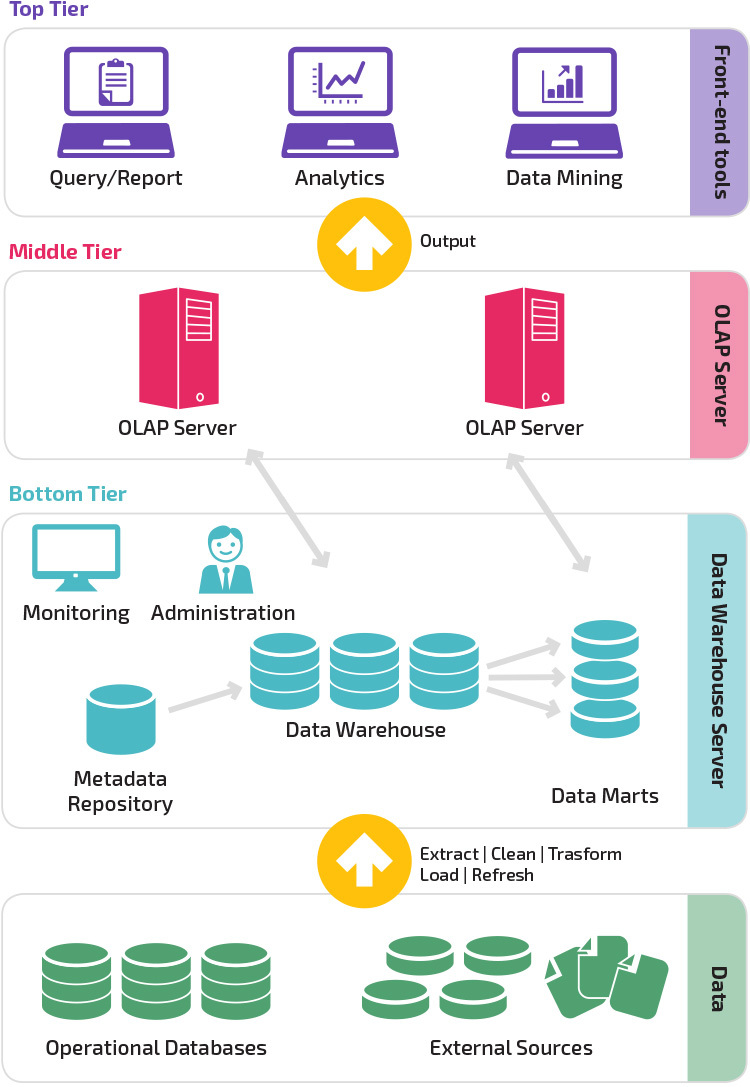
perinteinen Tietovarastoarkkitehtuuri
seuraavat käsitteet korostavat joitakin vakiintuneita ideoita ja suunnitteluperiaatteita, joita käytetään perinteisten tietovarastojen rakentamisessa.
kolmiportainen Arkkitehtuuri
perinteinen tietovarastoarkkitehtuuri käyttää kolmiportaista rakennetta, joka koostuu seuraavista tasoista.
- alin taso: Tämä taso sisältää tietokantapalvelimen, jota käytetään tietojen poimimiseen monista eri lähteistä, kuten kaupallisista tietokannoista, joita käytetään etupään sovelluksissa.
- keskitaso: Keskimmäinen taso taloa OLAP-palvelin, joka muuntaa tiedot rakenne sopii paremmin analyysiin ja monimutkainen kyselyssä. OLAP-palvelin voi toimia kahdella tavalla: joko laajennettuna relaatiotietokannan hallintajärjestelmä, joka kartoittaa toimintaa moniulotteinen data standardin relaatiotoimintaa (Relational OLAP), tai käyttämällä moniulotteinen OLAP malli, joka suoraan toteuttaa moniulotteinen tiedot ja toiminnot.
- Ylin taso: ylin taso on asiakaskerros. Tämä taso sisältää korkean tason tietojen analysointiin, kyselyraportointiin ja tiedon louhintaan käytettävät työkalut.
Kimball vs. Inmon
kahdella tietovarastoinnin pioneerilla Bill Inmonilla ja Ralph Kimballilla oli erilaisia lähestymistapoja tietovaraston suunnitteluun.
Ralph Kimballin lähestymistavassa korostettiin datamarkettien merkitystä, jotka ovat tiettyihin toimialoihin kuuluvien tietojen arkistoja. Tietovarasto on yksinkertaisesti erilaisten datamarkettien yhdistelmä, joka helpottaa raportointia ja analysointia. Kimball-tietovaraston suunnittelussa käytetään ”alhaalta ylöspäin” – lähestymistapaa.
Bill Inmon piti tietovarastoa keskitettynä tietovarastona kaikelle yritystiedolle. Tässä lähestymistavassa organisaatio luo ensin normalisoidun tietovarastomallin. Dimensional data marts luodaan varastomallin pohjalta. Tätä kutsutaan ylhäältä alas-lähestymistavaksi tietovarastointiin.
Tietovarastomallit
perinteisessä arkkitehtuurissa on kolme yhteistä tietovarastomallia: virtual warehouse, data mart ja enterprise data warehouse:
- virtuaalinen tietovarasto on joukko erillisiä tietokantoja, joita voidaan kysellä yhdessä, jotta käyttäjä voi tehokkaasti käyttää kaikkia tietoja ikään kuin ne olisi tallennettu yhteen tietovarastoon.
- data mart-mallia käytetään liiketoimintalinjakohtaiseen raportointiin ja analysointiin. Tässä tietovarastomallissa tiedot kootaan yhteen useista tietyn liiketoiminta-alueen kannalta merkityksellisistä lähdejärjestelmistä, kuten myynnistä tai rahoituksesta.
- yrityksen tietovarastomallin mukaan tietovarasto sisältää koko organisaation kattavaa aggregoitua tietoa. Tässä mallissa tietovarasto nähdään yrityksen tietojärjestelmän ytimenä, johon on integroitu tieto kaikista liiketoimintayksiköistä.
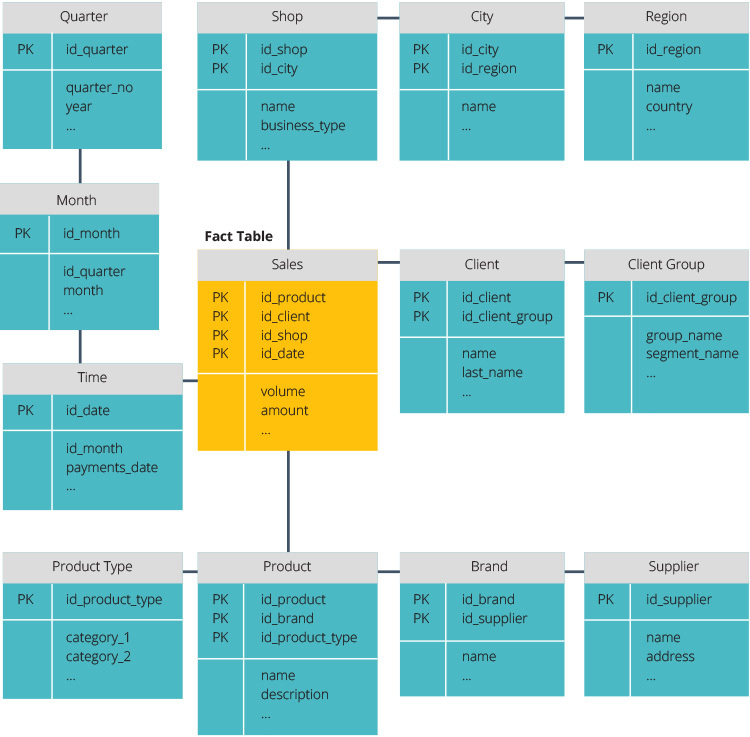
Tähtikaavio vs. lumihiutale-skeema
tähtikaavio ja lumihiutale-skeema ovat kaksi tapaa jäsentää tietovarasto.
tähtikaaviossa on keskitetty tietovarasto, joka on tallennettu faktataulukkoon. Skeema jakaa faktataulukon sarjaksi denormalisoituja ulottuvuustaulukoita. Faktataulukko sisältää aggregoidut tiedot, joita käytetään raportointitarkoituksiin, kun taas muuttujataulukossa kuvataan tallennetut tiedot.
Denormalisoidut kuviot ovat yksinkertaisempia, koska aineisto on ryhmitelty. Faktataulukko käyttää vain yhtä linkkiä liittyäkseen jokaiseen ulottuvuustaulukkoon. Tähtikaavion yksinkertaisempi muotoilu tekee monimutkaisten kyselyiden kirjoittamisesta paljon helpompaa.
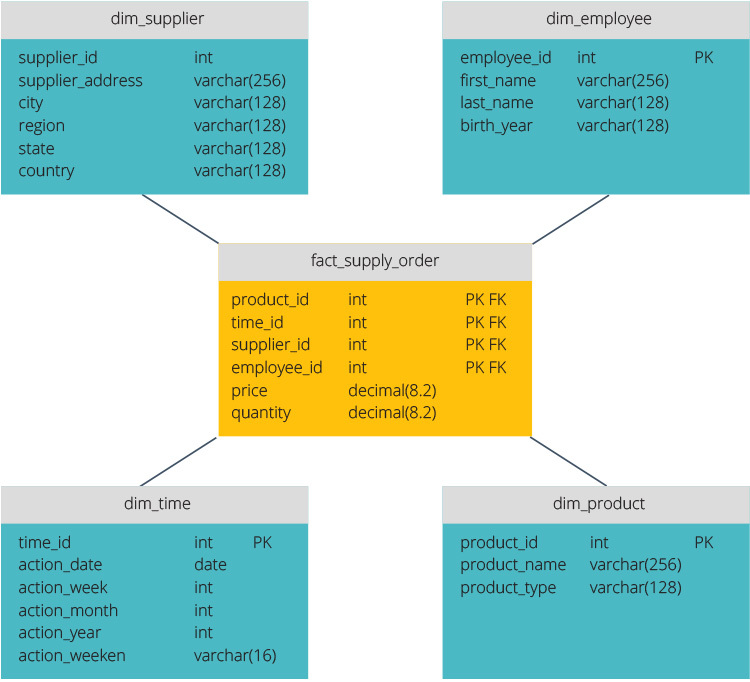
lumihiutale-skeema on erilainen, koska se normalisoi dataa. Normalisointi tarkoittaa tietojen tehokasta järjestämistä siten, että kaikki datariippuvuudet määritellään, ja jokainen taulukko sisältää minimaaliset irtisanomiset. Yhden ulottuvuuden taulukot haarautuvat siten erillisiksi ulottuvuustaulukoiksi.
lumihiutale-skeema käyttää vähemmän levytilaa ja säilyttää paremmin tietojen eheyden. Suurin haitta on tietojen saamiseksi vaadittavien kyselyiden monimutkaisuus-jokaisen kyselyn on kaivauduttava syvälle päästäkseen asiaankuuluviin tietoihin, koska liittymiä on useita.
ETL vs. ELT
ETL ja ELT ovat kaksi eri tapaa ladata tietoja varastoon.
Extract, Transform, Load (ETL) poimii ensin tiedot tietolähteistä, jotka ovat tyypillisesti kaupallisia tietokantoja. Tiedot säilytetään tilapäisessä vaiheistustietokannassa. Tämän jälkeen suoritetaan muunnostoimet, joilla aineisto jäsennetään ja muunnetaan kohdetietovarastojärjestelmälle sopivaan muotoon. Jäsennelty data ladataan sitten varastoon valmiina analysoitavaksi.
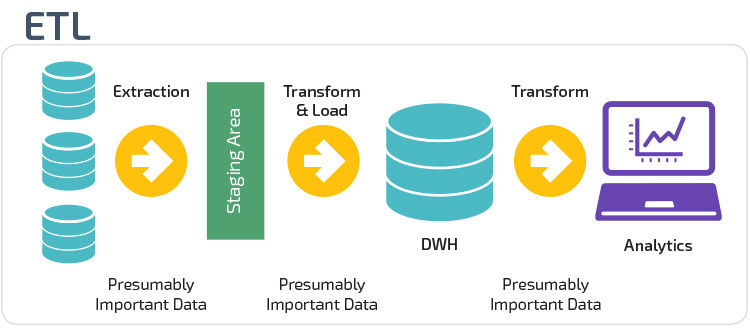
Extract Load Transform (ELT) – menetelmällä tiedot ladataan välittömästi sen jälkeen, kun ne on uutettu lähdetietopooleista. Lavastustietokantaa ei ole, eli tiedot ladataan välittömästi keskitettyyn arkistoon. Data muunnetaan tietovarastojärjestelmän sisällä business intelligence-työkalujen ja analytiikan käyttöön.
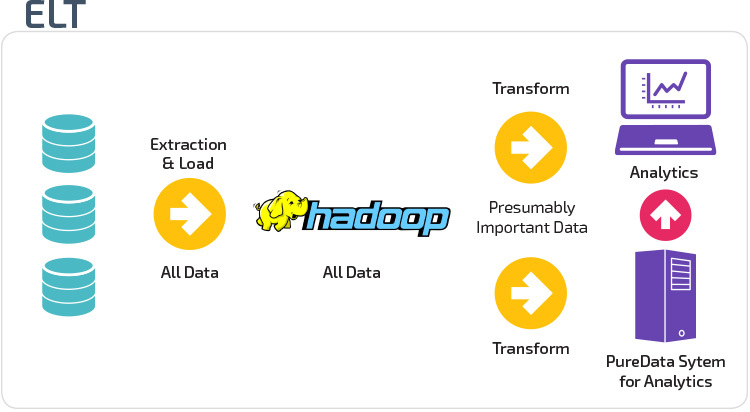
organisaation kypsyys
organisaation tietovaraston rakenne riippuu myös sen nykytilanteesta ja tarpeista.
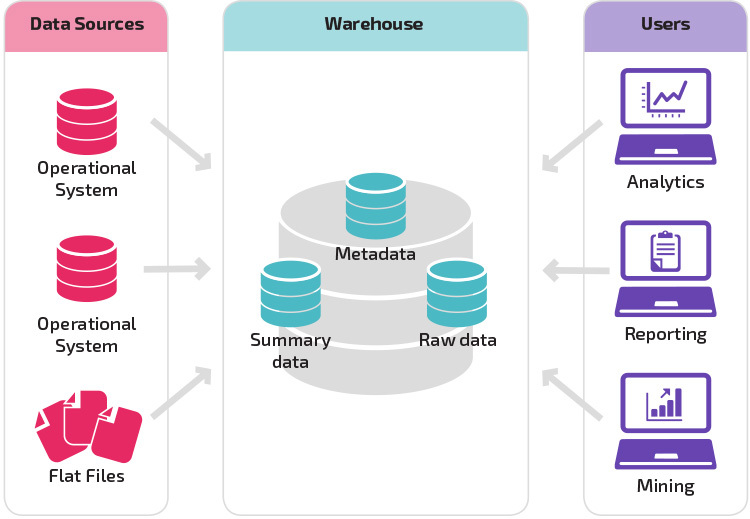
perusrakenteen avulla varaston loppukäyttäjät pääsevät suoraan käsiksi lähdejärjestelmistä johdettuihin yhteenvetotietoihin ja analysoivat, raportoivat ja louhivat näitä tietoja. Tämä rakenne on hyödyllinen silloin, kun tietolähteet ovat peräisin samantyyppisistä tietokantajärjestelmistä.
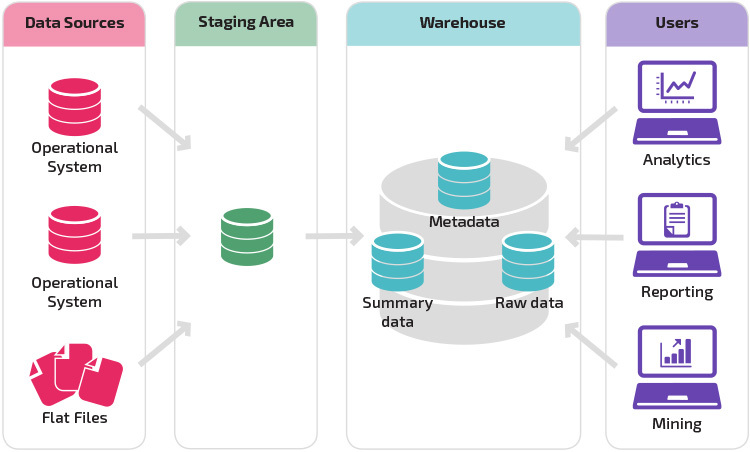
varasto, jossa on valmistelualue, on seuraava looginen askel organisaatiossa, jossa on erilaisia tietolähteitä, joissa on monia erilaisia ja erityyppisiä tietoja. Valmistelualue muuntaa tiedot tiivistettyyn jäsenneltyyn muotoon, jota on helpompi kysellä analyysi-ja raportointityökalujen avulla.
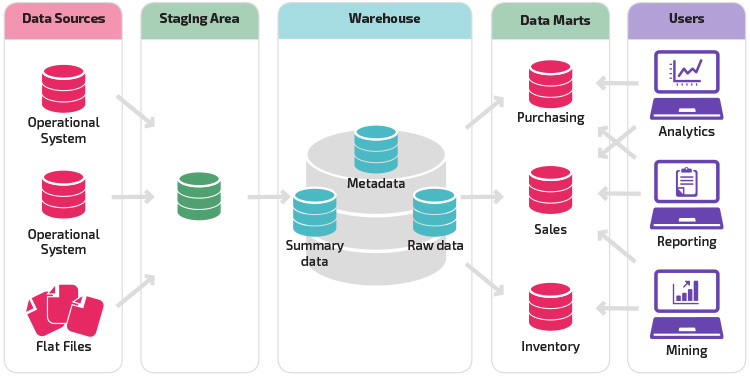
muunnelma vaiheistusrakenteesta on datamarttien lisääminen tietovarastoon. Datamarketeissa on tiivistetty tietyn toimialan tiedot, joten tiedot ovat helposti saatavilla tiettyjä analyysimuotoja varten. Esimerkiksi lisäämällä data marts voi mahdollistaa rahoitusanalyytikko helpommin suorittaa yksityiskohtaisia kyselyjä myyntitietoja, tehdä ennusteita asiakkaiden käyttäytymistä. Datamarketit helpottavat analysointia räätälöimällä dataa erityisesti loppukäyttäjän tarpeisiin.
Uudet Tietovarastoarkkitehtuurit
viime vuosina tietovarastot ovat siirtymässä pilveen. Uudet pilvipohjaiset tietovarastot eivät noudata perinteistä arkkitehtuuria, vaan jokaisella tietovarastotarjonnalla on ainutlaatuinen arkkitehtuuri.
tässä osiossa on yhteenveto arkkitehtuureista, joita kaksi suosituinta pilvipohjaista varastoa: Amazon Redshift ja Google BigQuery.
Amazonin Punasiirtymä
Amazonin Punasiirtymä on pilvipohjainen esitys perinteisestä tietovarastosta.
Punasiirtymä edellyttää laskentaresurssien varaamista ja asettamista klustereiksi, jotka sisältävät yhden tai useamman solmun kokoelman. Jokaisella solmulla on oma suoritin, tallennustila ja RAM. Leader-solmu kokoaa kyselyt ja siirtää ne laskemaan solmuja, jotka suorittavat kyselyt.
jokaisella solmulla tiedot tallennetaan paloina, joita kutsutaan viipaleiksi. Redshift käyttää columnar varastointi, eli jokainen lohko tietoja sisältää arvoja yhdestä sarakkeesta useiden rivien, sen sijaan, että yksi rivi arvoja useista sarakkeista.
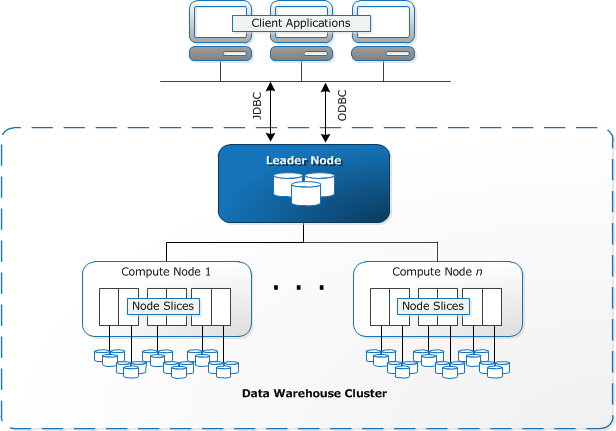
lähde: AWS-dokumentaatio
Punasiirtymä käyttää MPP-arkkitehtuuria ja jakaa suuret tietojoukot paloihin, jotka on jaettu paloihin kunkin solmun sisällä. Kyselyt suorittaa nopeammin, koska laskea solmut prosessi kyselyt kunkin siivun samanaikaisesti. Leader-solmu kokoaa tulokset ja palauttaa ne asiakassovellukseen.
asiakassovellukset, kuten BI-ja analytiikkatyökalut, voivat muodostaa suoran yhteyden Redshift-järjestelmään avoimen lähdekoodin PostgreSQL JDBC-ja ODBC-ajurien avulla. Analyytikot voivat siis suoriutua tehtävistään suoraan Punasiirtymätiedoilla.
Punasiirtymä voi ladata vain jäsenneltyä dataa. On mahdollista ladata tietoja Redshift käyttäen valmiiksi integroituja järjestelmiä, kuten Amazon S3 ja DynamoDB, painamalla tietoja mistä tahansa on-premise isäntä SSH connectivity, tai integroimalla muita tietolähteitä käyttäen Redshift API.
Google BigQuery
BigQueryn arkkitehtuuri on palvelematonta, eli Google hallitsee dynaamisesti koneresurssien jakamista. Kaikki resurssinhallintapäätökset ovat siis käyttäjältä piilossa.
BigQuery antaa asiakkaiden ladata tietoja Google Cloud Storagesta ja muista luettavista tietolähteistä. Vaihtoehtona on suoratoistaa dataa, jonka avulla kehittäjät voivat lisätä dataa tietovarastoon reaaliaikaisesti rivi riviltä sitä mukaa, kun se tulee saataville.
BigQuery käyttää Dremel-nimistä kyselyn suoritusmoottoria, joka pystyy skannaamaan miljardeja rivejä dataa muutamassa sekunnissa. Dremel käyttää massiivisesti rinnakkaista kyselyä tietojen skannaamiseen taustalla olevassa Colossus-tiedostonhallintajärjestelmässä. Colossus jakaa tiedostoja 64 megatavun suuruisiin paloihin monien Tietopalveluiden solmuiksi nimettyjen resurssien joukossa, jotka on ryhmitelty klustereiksi.
Dremel käyttää pylväsmäistä tietorakennetta, joka muistuttaa Punasiirtymää. Puuarkkitehtuuri lähettää kyselyjä tuhansien koneiden keskuudessa sekunneissa.
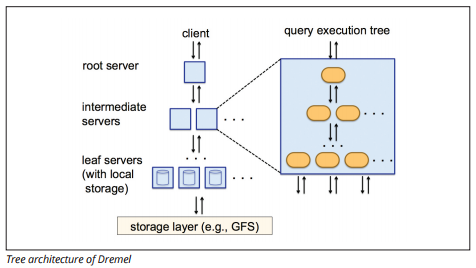
Kuvanlähde
yksinkertaisia SQL-komentoja käytetään tietojen kyselyihin.
Panoply
Panoply tarjoaa päästä päähän-tiedonhallintapalvelua. Sen ainutlaatuinen itseoptimoiva arkkitehtuuri hyödyntää koneoppimista ja natural language processingia (NLP) mallintamaan ja virtaviivaistamaan tiedon kulkua lähteestä analyysiin, lyhentäen aikaa datasta arvoon mahdollisimman lähelle nollaa.
Panoplyn älykäs datainfrastruktuuri sisältää seuraavat ominaisuudet:
- kyselyiden ja tietojen analysointi-kunkin käyttötapauksen parhaan kokoonpanon tunnistaminen, sen säätäminen ajan mittaan, ja rakennusindeksit, sortkeys, diskeys, tietotyypit, Imurointi ja osiointi.
- tunnistaa kyselyt, jotka eivät noudata parhaita käytäntöjä – kuten ne, jotka sisältävät sisäkkäisiä silmukoita tai implisiittistä valamista – ja kirjoittaa ne uudelleen vastaavaan kyselyyn, joka vaatii murto-osan suoritusajasta tai resursseista.
- Palvelinkokoonpanojen optimointi ajan mittaan kyselykuvioiden perusteella ja oppimalla, mikä palvelinasetuksista toimii parhaiten. Alusta vaihtaa palvelintyyppejä saumattomasti ja mittaa tuloksena olevaa suorituskykyä.
Beyond Cloud Data storages
pilvipohjaiset tietovarastot ovat iso askel eteenpäin perinteisistä arkkitehtuureista. Käyttäjillä on kuitenkin edelleen useita haasteita niiden käyttöönotossa.:
- tietojen lataaminen pilvitietovarastoihin ei ole triviaalia, ja suurten tietoputkistojen osalta se vaatii ETL-prosessin perustamista, testaamista ja ylläpitoa. Tämä osa prosessia tehdään tyypillisesti kolmannen osapuolen työkaluja.
- päivitykset, korotukset ja poistot voivat olla hankalia, ja ne on tehtävä huolellisesti kyselytehon heikkenemisen estämiseksi.
- Puolistrukturoitua dataa on vaikea käsitellä-se on normalisoitava relaatiotietokantamuotoon, joka vaatii suurten datavirtojen automatisointia.
- sisäkkäisiä rakenteita ei tyypillisesti tueta pilvitietovarastoissa. Sinun täytyy litistää sisäkkäisiä taulukoita muotoon tietovarasto voi ymmärtää.
- klusterin optimointi—on olemassa erilaisia vaihtoehtoja Punasiirtymäklusterin perustamiseksi työkuormiesi ajamista varten. Erilaiset työkuormat, tietojoukot tai jopa erityyppiset kyselyt saattavat vaatia erilaisen asennuksen. Pysyäksesi optimaalisena sinun on jatkuvasti tarkistettava ja muokattava asetuksiasi.
- kyselyn optimointi-käyttäjän kyselyt eivät välttämättä noudata parhaita käytäntöjä, joten niiden suorittaminen kestää paljon kauemmin. Saatat huomata työskenteleväsi käyttäjien tai automatisoitujen asiakassovellusten kanssa optimoidaksesi kyselyt niin, että tietovarasto voi toimia odotetulla tavalla.
- Varmuuskopiointi ja palautus—vaikka tietovaraston myyjät tarjoavat lukuisia vaihtoehtoja tietojen varmuuskopiointiin, ne eivät ole vähäpätöisiä perustaa ja vaativat seurantaa ja tarkkaa huomiota.
Panoply on älykäs tietovarasto, joka lisää automaatiokerroksen, joka hoitaa kaikki edellä mainitut monimutkaiset tehtävät, säästää arvokasta aikaa ja auttaa sinua pääsemään datasta oivallukseen minuuteissa.
Lue lisää panoplyn älykkäistä tietovarastotyökaluista.
lisätietoja tietovarastoista
- tietovaraston käsitteet: perinteinen vs. Pilvi
- tietokanta vs. tietovarasto
- Datamart vs. tietovarasto
- Amazon Redshift Architecture