データウェアハウスとは、企業内の幅広いソースからデータを収集し、そのデータを使用して経営の意思決定を支援する電子システムです。
企業は、従来のオンプレミスシステムではなく、クラウドベースのデータウェアハウスに移行しています。 クラウドベースのデータウェアハウスは、次の点で従来のウェアハウスとは異なります:
- 物理的なハードウェアを購入する必要はありません。
- クラウドデータウェアハウスの設定と拡張は、より迅速かつ安価です。
- クラウドベースのデータウェアハウスアーキテクチャは、mpp(massively parallel processing)を使用するため、通常、複雑な分析クエリをはるかに高速に実行できます。
この記事の残りの部分では、従来のデータウェアハウスアーキテクチャについて説明し、最も一般的なクラウドベースのデータウェアハウスサービスで使用されているいくつかのアーキテクチャのアイデアと概念を紹介します。
詳細については、このガイドのデータウェアハウスの概念に関するページを参照してください。
従来のデータウェアハウスアーキテクチャ
以下の概念は、従来のデータウェアハウスの構築に使用されている確立されたアイデアと設計原則のいず
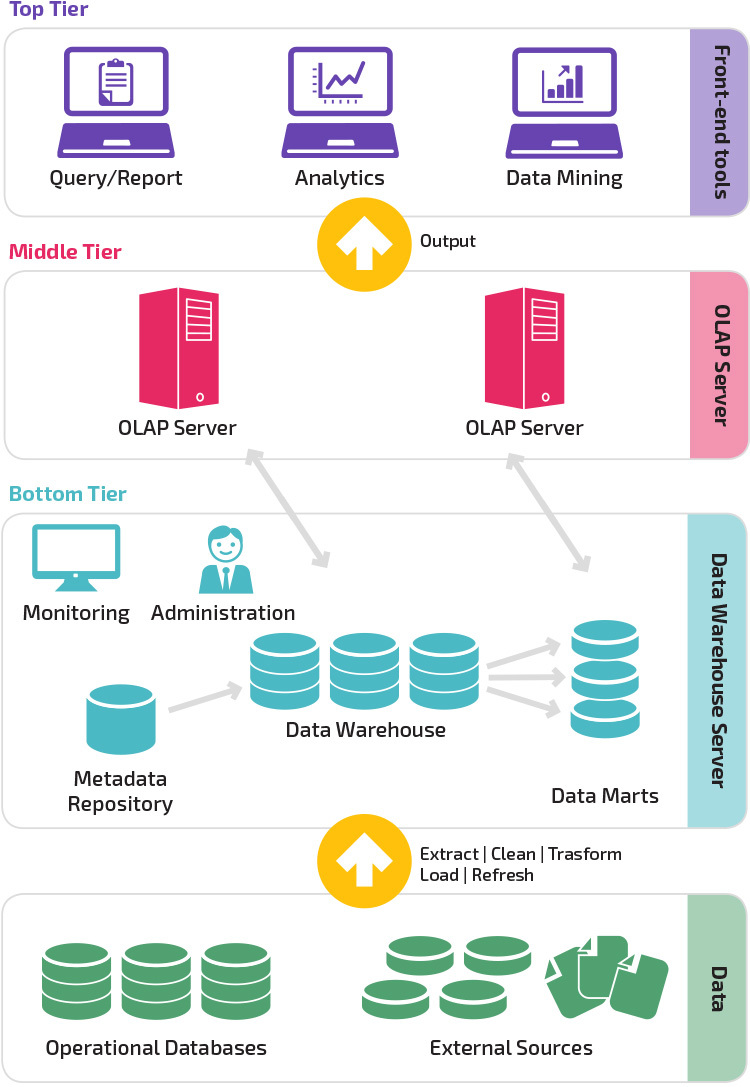
三層アーキテクチャ
従来のデータウェアハウスアーキテクチャは、以下の層で構成される三層構造を採用しています。
- Bottom tier:この層には、フロントエンドアプリケーションに使用されるトランザクションデータベースなど、さまざまなソースからデータを抽出するために使用さ
- 中間層: 中間層にはOLAPサーバーがあり、分析や複雑なクエリに適した構造にデータを変換します。 OLAPサーバーは、多次元データの操作を標準リレーショナル操作(Relational OLAP)にマップする拡張リレーショナルデータベース管理システムとして、または多次元データと操作を直
- 最上位層:最上位層はクライアント層です。 この層には、高レベルのデータ分析、クエリレポート、およびデータマイニングに使用されるツールが保持されます。
Kimball vs.Inmon
Bill InmonとRalph Kimballという名前のデータウェアハウスの先駆者は、データウェアハウスの設計に異なるアプローチを持っていました。
Ralph Kimball氏のアプローチは、特定の事業分野に属するデータのリポジトリであるデータマートの重要性を強調した。 データウェアハウスは、単にレポートと分析を容易にする異なるデータマートの組み合わせです。 Kimballデータウェアハウスの設計では、”ボトムアップ”アプローチを使用します。
Bill Inmonは、データウェアハウスをすべての企業データの集中リポジトリとみなしました。 このアプローチでは、組織は最初に正規化されたデータウェアハウスモデルを作成します。 次に、倉庫モデルに基づいて次元データマートが作成されます。 これは、データウェアハウスへのトップダウンアプローチとして知られています。
データウェアハウスモデル
従来のアーキテクチャでは、仮想倉庫、データマート、エンタープライズデータウェアハウスの三つの一般的なデータウェアハウスモデ:
- 仮想データウェアハウスは、別々のデータベースのセットであり、一緒に照会できるため、ユーザーはすべてのデータに1つのデータウェアハウスに格納されているかのように効果的にアクセスできます。
- データマートモデルは、ビジネスライン固有のレポートと分析に使用されます。 このデータウェアハウスモデルでは、販売や財務など、特定のビジネス領域に関連するさまざまなソースシステムからデータが集計されます。
- エンタープライズデータウェアハウスモデルでは、データウェアハウスに組織全体にまたがる集計データが含まれていることが規定されています。 このモデルでは、データウェアハウスは企業の情報システムの中心であり、すべてのビジネスユニットからのデータが統合されています。
スタースキーマとSnowflakeスキーマ
スタースキーマとsnowflakeスキーマは、データウェアハウスを構造化する2つの方法です。
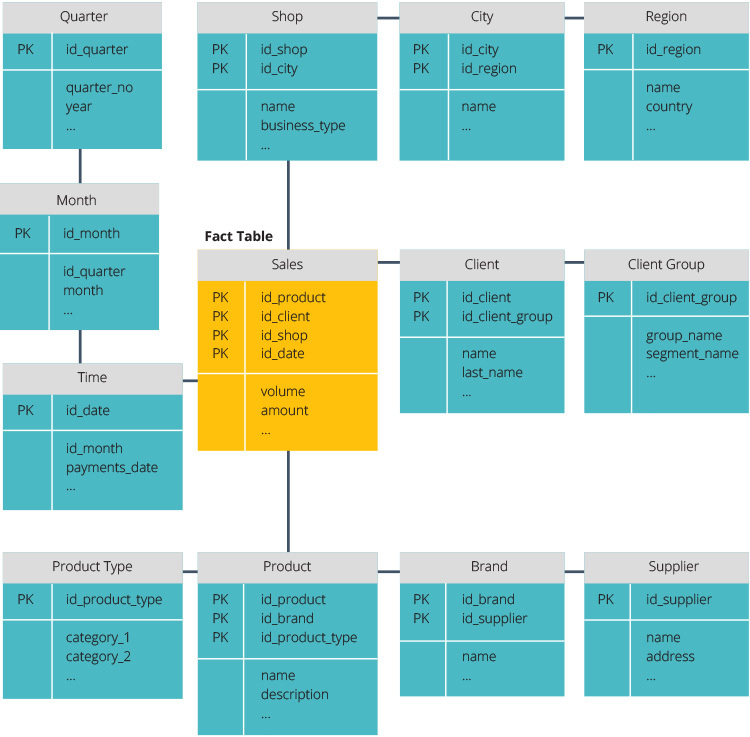
スタースキーマには、ファクトテーブルに格納された集中型のデータリポジトリがあります。 スキーマは、ファクトテーブルを一連の非正規化ディメンションテーブルに分割します。 ファクトテーブルには、レポートの目的で使用される集計データが含まれ、ディメンションテーブルには格納されたデータが記述されます。
非正規化された計画は、データがグループ化されているため複雑ではありません。 ファクトテーブルは、各ディメンションテーブルに結合するために1つのリンクのみを使用します。 Starスキーマのシンプルな設計により、複雑なクエリを書くのがはるかに簡単になります。
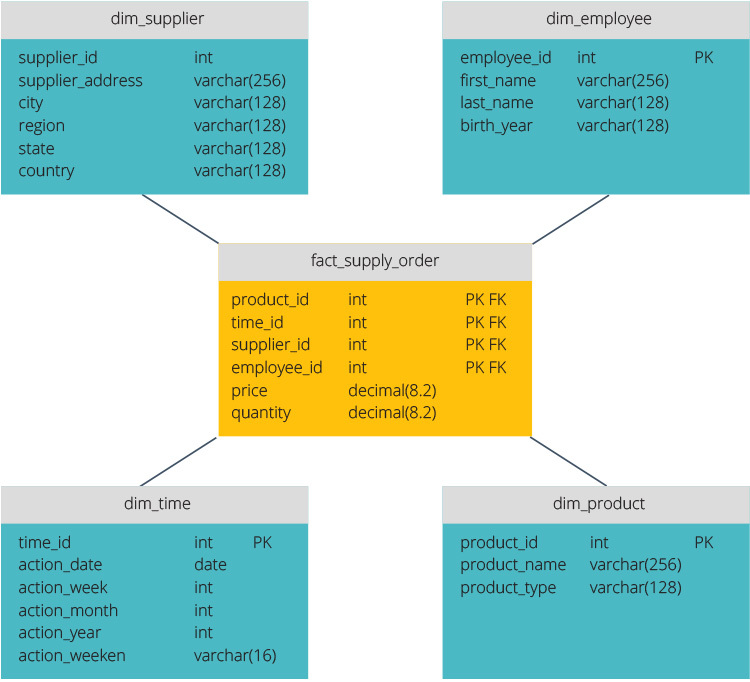
snowflakeスキーマは、データを正規化するために異なります。 正規化とは、すべてのデータ依存関係が定義され、各テーブルに最小限の冗長性が含まれるように、データを効率的に整理することを意味します。 したがって、単一の次元テーブルは別々の次元テーブルに分岐します。
snowflakeスキーマは、使用するディスク領域が少なく、データの整合性が良好に維持されます。 主な欠点は、データへのアクセスに必要なクエリの複雑さです—複数の結合があるため、各クエリは関連するデータに到達するために深く掘る必要があ
etlとELT
ETLとELTは、データを倉庫にロードする2つの異なる方法です。
Extract,Transform,Load(ETL)は、まず、通常はトランザクションデータベースであるデータソースのプールからデータを抽出します。 データは一時的なステージングデータベースに保持されます。 次に、変換操作を実行して、データを構造化し、ターゲットデータウェアハウスシステムに適した形式に変換します。 その後、構造化データが倉庫にロードされ、分析の準備が整います。
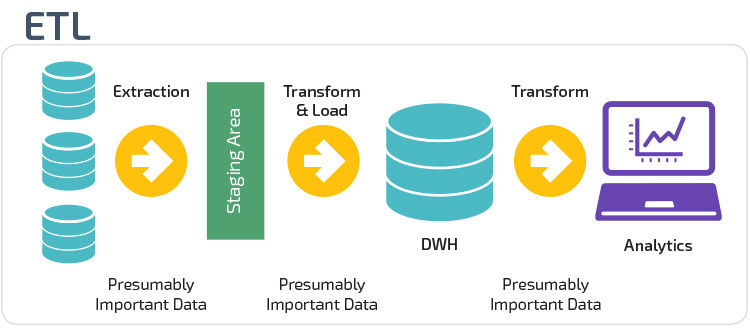
Extract Load Transform(ELT)を使用すると、データはソース・データ・プールから抽出された後すぐにロードされます。 ステージングデータベースはなく、データはすぐに単一の集中リポジトリにロードされます。 データは、ビジネスインテリジェンスツールと分析で使用するために、データウェアハウスシステム内で変換されます。
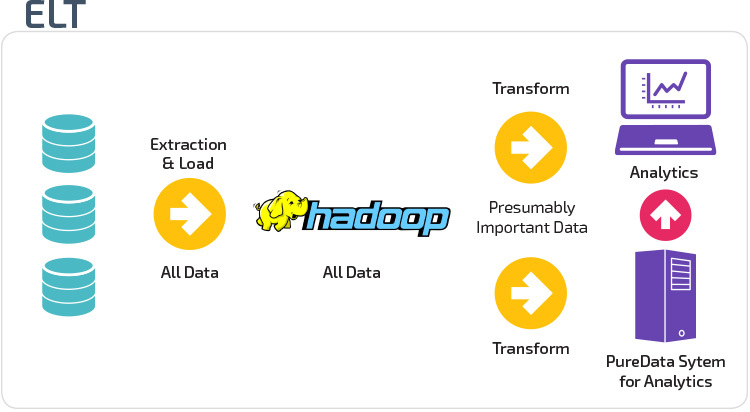
組織の成熟度
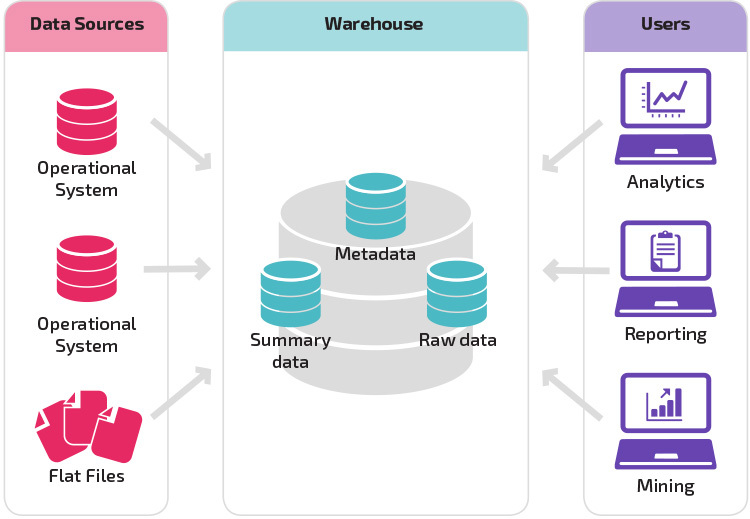
組織のデータウェアハウスの構造は、現在の状況とニーズにも依存します。
基本構造により、倉庫のエンドユーザーはソースシステムから派生した要約データに直接アクセスし、そのデータの分析、レポート作成、マイニングを実行できます。 この構造は、データソースが同じタイプのデータベースシステムから派生する場合に便利です。
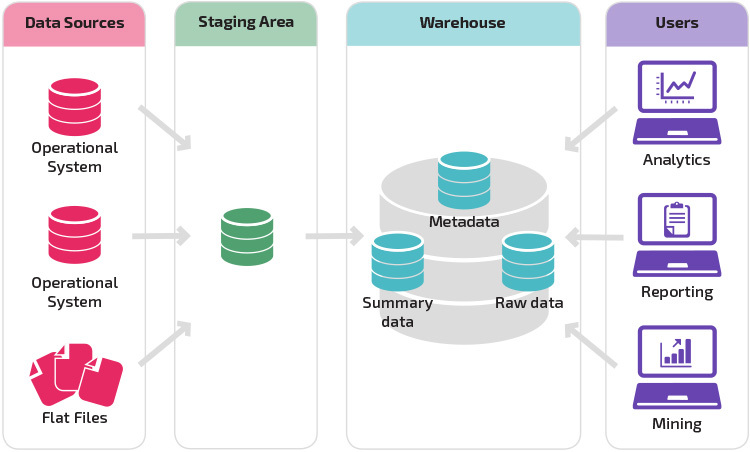
ステージング領域を持つウェアハウスは、さまざまな種類と形式のデータを持つ異種のデータソースを持つ組織の次の論理的なステップです。 ステージング領域では、分析ツールやレポートツールを使用して簡単にクエリできる要約構造化形式にデータが変換されます。
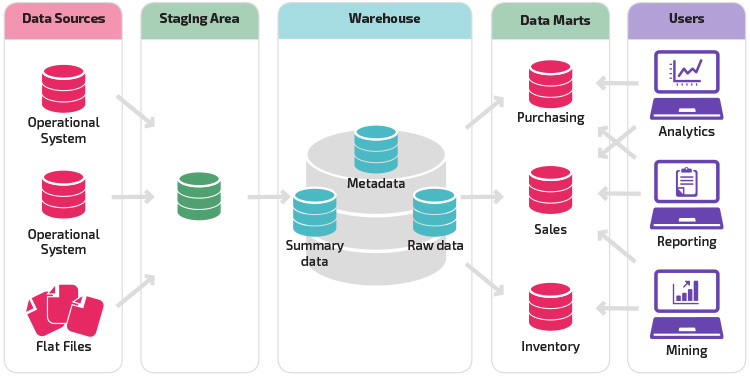
ステージング構造のバリエーションは、データウェアハウスへのデータマートの追加です。 データマートには、特定のビジネスラインの要約データが格納されているため、特定の形式の分析でそのデータに簡単にアクセスできます。 たとえば、データマートを追加すると、財務アナリストが販売データの詳細なクエリをより簡単に実行し、顧客の行動に関する予測を行うことができます。 データマートは、エンドユーザーのニーズを満たすためにデータを特別に調整することで、分析を容易にします。
新しいデータウェアハウスアーキテクチャ
近年、データウェアハウスはクラウドに移行しています。 新しいクラウドベースのデータウェアハウスは従来のアーキテクチャに準拠しておらず、各データウェアハウスには固有のアーキテクチャがあります。
このセクションでは、最も人気のあるクラウドベースの倉庫のうち、Amazon RedshiftとGoogle BigQueryの二つで使用されているアーキテクチャを要約します。
Amazon Redshift
Amazon Redshiftは、従来のデータウェアハウスのクラウドベースの表現です。
Redshiftでは、コンピューティングリソースをプロビジョニングし、一つ以上のノードのコレクションを含むクラスターの形で設定する必要があります。 各ノードには、独自のCPU、ストレージ、およびRAMがあります。 リーダーノードはクエリをコンパイルし、クエリを実行する計算ノードに転送します。
各ノードでは、データはスライスと呼ばれるチャンクに格納されます。 つまり、データの各ブロックには、複数の列からの値を持つ単一の行ではなく、複数の行にわたる単一の列からの値が含まれます。
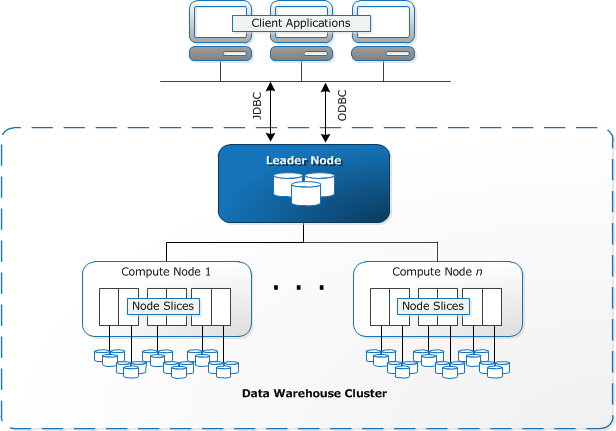
ソース:AWS Documentation
RedshiftはMPPアーキテクチャを使用し、大きなデータセットを各ノード内のスライスに割り当てられたチャンクに分割します。 計算ノードは各スライスのクエリを同時に処理するため、クエリの実行が高速になります。 リーダーノードは結果を集計し、クライアントアプリケーションに返します。
BIや分析ツールなどのクライアントアプリケーションは、オープンソースのPostgreSQL JDBCおよびODBCドライバを使用してRedshiftに直接接続できます。 このように、アナリストはRedshiftデータに対して直接タスクを実行できます。
Redshiftは構造化データのみをロードできます。 AMAZON S3やDynamoDBなどの事前統合システムを使用してREDSHIFTにデータをロードすることも、ssh接続を使用してオンプレミスホストからデータをプッシュすることも、Redshift APIを使用して他のデータソースを統合することもできます。
Google BigQuery
BigQueryのアーキテクチャはサーバーレスであり、Googleがマシンリソースの割り当てを動的に管理することを意味します。 したがって、すべてのリソース管理の決定は、ユーザーから隠されています。
BigQueryを使用すると、クライアントはGoogle Cloud Storageやその他の読み取り可能なデータソースからデータをロードできます。 これにより、開発者は、利用可能になったときに、リアルタイムで行ごとにデータウェアハウスにデータを追加することができます。
BigQueryはDremelという名前のクエリ実行エンジンを使用しており、数十億行のデータをわずか数秒でスキャンできます。 Dremelは、基になるColossusファイル管理システム内のデータをスキャンするために超並列クエリを使用します。 Colossusは、ノードという名前の多くのコンピューティングリソースの中で64メガバイトのチャンクにファイルを配布します。
Dremelは、redshiftに似た列データ構造を使用します。 ツリーアーキテクチャは、数千台のマシン間でクエリを数秒でディスパッチします。
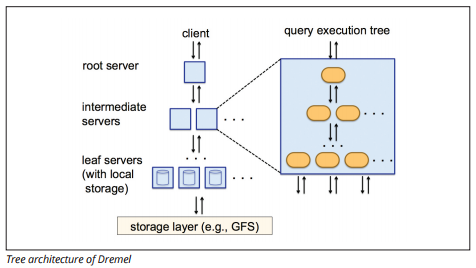
イメージソース
単純なSQLコマンドは、データに対するクエリを実行するために使用されます。
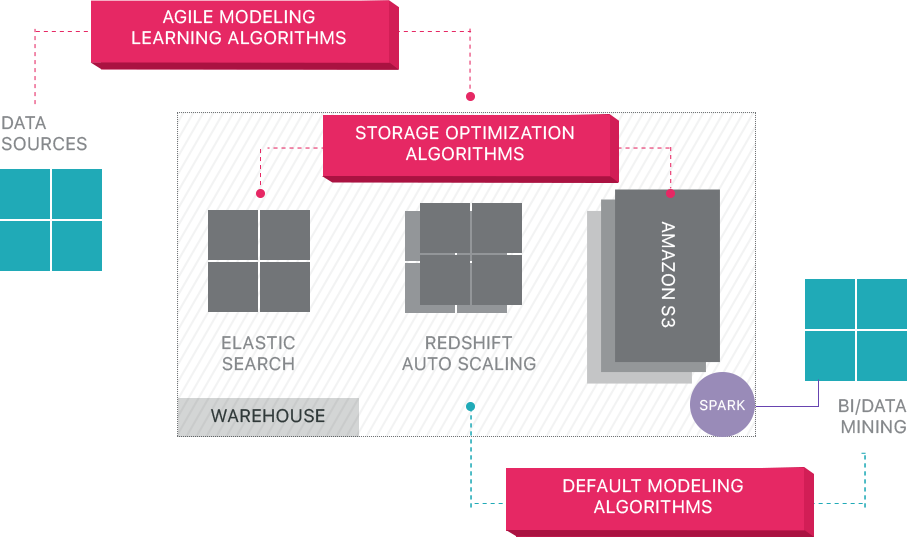
Panoply
Panoplyは、エンドツーエンドのデータ管理をサービスとして提供します。 独自の自己最適化アーキテクチャは、機械学習と自然言語処理(NLP)を利用して、ソースから分析までのデータの流れをモデル化して合理化し、データから価値
Panoplyのスマートデータインフラストラクチャには、以下の機能が含まれています:
- クエリとデータの分析–各ユースケースに最適な構成を特定し、時間の経過とともに調整し、インデックス、ソートキー、ディスク、データ型、バキューム、およびパーティショ
- ネストされたループや暗黙的なキャストを含むようなベストプラクティスに従わないクエリを識別し、ランタイムまたはリソースの一部を必要とする同等のクエリに書き換えます。
- クエリパターンに基づいて、どのサーバー設定が最適かを学習することにより、時間の経過とともにサーバー設定を最適化します。 プラットフォームは、サーバーの種類をシームレスに切り替えて、結果のパフォーマンスを測定します。
クラウドデータウェアハウスを超えて
クラウドベースのデータウェアハウスは、従来のアーキテクチャからの大きな一歩です。 ただし、ユーザーは設定時にいくつかの課題に直面しています:
- クラウドデータウェアハウスへのデータのロードは簡単ではなく、大規模なデータパイプラインの場合は、ETLプロセスの設定、テスト、および保守が必要です。 プロセスのこの部分は、通常、サードパーティ製のツールを使用して行われます。
- 更新、アップサート、および削除は難しい場合があり、クエリのパフォーマンスの低下を防ぐために慎重に行う必要があります。
- 半構造化データは扱いにくい-大規模なデータストリームの自動化が必要なリレーショナルデータベース形式に正規化する必要があります。
- ネストされた構造は、通常、クラウドデータウェアハウスではサポートされていません。 ネストされたテーブルをデータウェアハウスが理解できる形式にフラット化する必要があります。
- クラスターの最適化—ワークロードを実行するためにRedshiftクラスターを設定するには、さまざまなオプションがあります。 異なるワークロード、データセット、または異なるタイプのクエリでも、異なる設定が必要になる場合があります。 最適に滞在するには、継続的に再訪し、あなたのセットアップを微調整する必要があります。
- クエリの最適化—ユーザークエリはベストプラクティスに従わない可能性があり、結果的に実行に時間がかかります。 データウェアハウスが期待どおりに実行できるように、クエリを最適化するために、ユーザーや自動化されたクライアントアプ
- バックアップとリカバリ—データウェアハウスベンダーは、データをバックアップするための多数のオプションを提供していますが、設定するのは簡単ではなく、監視と細心の注意を必要とします。
Panoplyは、上記の複雑なタスクをすべて処理する自動化レイヤーを追加するスマートなデータウェアハウスで、貴重な時間を節約し、データから洞察に数分で
Panoplyのスマートデータウェアハウスツールの詳細については、こちらをご覧ください。
データウェアハウスの詳細
- データウェアハウスの概念:伝統的なものと伝統的なもの クラウド
- データベースとデータウェアハウス
- データマートとデータウェアハウス
- Amazon Redshiftアーキテクチャ