szczegółowe spojrzenie na te niebezpieczne wykorzystanie luk w zabezpieczeniach mikroprocesorów i dlaczego może ich być więcej

jesteśmy przyzwyczajeni do myślenia o procesorach komputerowych jako uporządkowanych maszynach, które z całkowitą regularnością przechodzą od jednej prostej instrukcji do drugiej. Ale prawda jest taka, że od dziesięcioleci wykonują swoje zadania nie po kolei i tylko zgadują, co będzie dalej. Są w tym bardzo dobrzy, oczywiście. Tak dobra, że ta zdolność, zwana spekulatywną egzekucją, przyczyniła się do poprawy mocy obliczeniowej w ciągu ostatnich 25 lat. Ale 3 stycznia 2018 r. świat dowiedział się, że ta sztuczka, która zrobiła tak wiele dla nowoczesnego komputera, jest teraz jedną z jego największych słabości.
przez cały 2017 r.badacze z Cyberus Technology, Google Project Zero, Graz University of Technology, Rambus, University of Adelaide i University of Pennsylvania, a także niezależni badacze, tacy jak kryptograf Paul Kocher, oddzielnie opracowywali ataki, które wykorzystywały spekulacyjne egzekucje. Nasza grupa odkryła pierwotną lukę w zabezpieczeniach jednego z tych ataków już w 2016 roku, ale nie zebraliśmy wszystkich elementów.
tego typu ataki, zwane Meltdown i Spectre, nie były zwykłymi błędami. W momencie odkrycia, Meltdown mógł zhakować wszystkie mikroprocesory Intel x86 i procesory IBM Power, a także niektóre procesory oparte na ARM. Spectre i jego wiele odmian dodało do tej listy Procesory Advanced Micro Devices (AMD). Innymi słowy, prawie cały świat komputerów był podatny na zagrożenia.
a ponieważ spekulatywne wykonanie jest w dużej mierze wypalone w sprzęcie procesora, naprawienie tych luk nie było łatwym zadaniem. Nie powodując, że prędkość obliczeniowa szlifuje się na niskim biegu, stało się to jeszcze trudniejsze. W rzeczywistości, rok później, praca jest daleka od końca. Poprawki bezpieczeństwa były potrzebne nie tylko od producentów procesorów, ale od tych, którzy są dalej w łańcuchu dostaw, takich jak Apple, Dell, Linux i Microsoft. Pierwsze komputery zasilane chipami, które są celowo zaprojektowane tak, aby były odporne na nawet niektóre z tych luk, pojawiły się dopiero niedawno.
Spectre I Meltdown są wynikiem różnicy między tym, co oprogramowanie ma robić, a mikroarchitekturą procesora—szczegóły tego, jak faktycznie robi te rzeczy. Te dwie klasy hacków odkryły sposób na wyciek informacji przez tę różnicę. I są powody, by wierzyć, że odkryjemy więcej sposobów. Pomogliśmy znaleźć dwa, Branchscope i SpectreRSB, w zeszłym roku.
jeśli mamy utrzymać tempo ulepszeń obliczeniowych bez poświęcania bezpieczeństwa, będziemy musieli zrozumieć, w jaki sposób występują luki w zabezpieczeniach sprzętu. A to zaczyna się od zrozumienia widma i Meltdown.
we współczesnych systemach komputerowych programy napisane w językach zrozumiałych dla człowieka, takich jak C++, są kompilowane do instrukcji assembly-language-podstawowych operacji, które może wykonać procesor komputera. Aby przyspieszyć wykonywanie, nowoczesne procesory wykorzystują podejście zwane pipelining. Podobnie jak linia montażowa, rurociąg jest szeregiem etapów, z których każdy jest krokiem potrzebnym do wykonania instrukcji. Niektóre typowe etapy dla procesora Intel x86 obejmują te, które wprowadzają instrukcję z pamięci i dekodują ją, aby zrozumieć, co oznacza Instrukcja. Pipelining zasadniczo sprowadza równoległość do poziomu wykonania instrukcji: gdy jedna instrukcja jest wykonywana za pomocą etapu, Następna instrukcja może z niej korzystać.
od lat 90.mikroprocesory polegały na dwóch sztuczkach, aby przyspieszyć proces rurociągu: wykonanie poza kolejnością i spekulacja. Jeśli dwie instrukcje są niezależne od siebie—to znaczy, że wyjście jednej z nich nie wpływa na wejście drugiej—można je zmienić, a ich wynik nadal będzie poprawny. Jest to pomocne, ponieważ pozwala procesorowi na kontynuowanie pracy, jeśli instrukcja zatrzyma się w potoku. Na przykład, jeśli instrukcja wymaga danych, które znajdują się w pamięci głównej DRAM, a nie w pamięci podręcznej znajdującej się w samym procesorze, może to potrwać kilkaset cykli zegara, aby uzyskać te dane. Zamiast czekać, procesor może przenieść kolejną instrukcję przez potok.
druga sztuczka to spekulacje. Aby to zrozumieć, zacznij od tego, że niektóre instrukcje koniecznie prowadzą do zmiany, w której instrukcje będą następne. Rozwaĺź program zawierajÄ … cy instrukcjÄ ™ „if”: sprawdza on warunek, a jeĹ ” li warunek jest prawdziwy, procesor przeskakuje w inne miejsce w programie. Jest to przykład instrukcji gałęzi warunkowej, ale istnieją inne instrukcje, które również prowadzą do zmian w przepływie instrukcji.
teraz zastanów się, co się dzieje, gdy taka instrukcja gałęzi wchodzi do potoku. To sytuacja, która prowadzi do zagadki. Kiedy Instrukcja pojawia się na początku rurociągu, nie znamy jej wyniku, dopóki nie posunęła się dość głęboko w rurociąg. I nie znając tego rezultatu, nie możemy pobrać następnej instrukcji. Prostym, ale naiwnym rozwiązaniem jest uniemożliwienie wprowadzania nowych instrukcji do potoku, dopóki Instrukcja branch nie osiągnie punktu, w którym wiemy, skąd przyjdzie Następna Instrukcja. Wiele cykli zegara jest marnowanych w tym procesie, ponieważ rurociągi zwykle mają od 15 do 25 etapów. Co gorsza, instrukcje branch pojawiają się dość często, stanowiąc ponad 20 procent wszystkich instrukcji w wielu programach.
aby uniknąć wysokich kosztów związanych z opóźnieniem potoku, nowoczesne procesory używają jednostki architektonicznej zwanej predyktorem gałęzi, aby odgadnąć, skąd przyjdzie Następna instrukcja, po gałęzi. Celem tego predyktora jest spekulowanie na temat kilku kluczowych punktów. Po pierwsze, czy zostanie podjęta gałąź warunkowa, powodująca Przejście programu do innej sekcji programu,czy też będzie kontynuowana na istniejącej ścieżce? A po drugie, jeśli branch zostanie podjęta, gdzie pójdzie program-Jaka będzie następna Instrukcja? Uzbrojony w te przewidywania, rurociąg procesora może być utrzymywany w pełni.
ponieważ wykonywanie instrukcji opiera się na predykcji, jest ona wykonywana „spekulatywnie”: jeśli PREDYKCJA jest poprawna, wydajność znacznie się poprawia. Jeśli jednak przewidywanie okaże się nieprawidłowe, procesor musi być w stanie stosunkowo szybko cofnąć efekty wszelkich spekulatywnie wykonanych instrukcji.
projekt predictora gałęzi jest od wielu lat intensywnie badany w środowisku architektury komputerowej. Współczesne predyktory wykorzystują historię wykonania w programie jako podstawę swoich wyników. Ten schemat osiąga dokładność przekraczającą 95 procent w wielu różnych rodzajach programów, co prowadzi do dramatycznej poprawy wydajności w porównaniu z mikroprocesorem, który nie spekuluje. Missspeculation, jednak, jest możliwe. I niestety, ataki widma wykorzystują brak zaskoczenia.
inną formą spekulacji, która doprowadziła do problemów, są spekulacje w ramach jednej instrukcji w przygotowaniu. To dość zawiła koncepcja, więc rozpakujmy ją. Załóżmy, że instrukcja wymaga uprawnień do wykonania. Na przykład, instrukcja może skierować komputer do zapisu fragmentu danych do części pamięci zarezerwowanej dla rdzenia systemu operacyjnego. Nie chciałbyś, żeby tak się stało, chyba że zostało to zatwierdzone przez sam system operacyjny, albo ryzykujesz awarię komputera. Przed odkryciem Meltdown i Spectre, konwencjonalną mądrością było to, że można rozpocząć wykonywanie instrukcji spekulacyjnie, nawet zanim procesor osiągnie punkt sprawdzenia, czy instrukcja ma pozwolenie na wykonywanie swojej pracy.
w końcu, jeśli uprawnienie nie jest spełnione—w naszym przykładzie system operacyjny nie usankcjonował tej próby manipulowania pamięcią—wyniki są wyrzucane, a program wskazuje błąd. Ogólnie rzecz biorąc, procesor może spekulować wokół dowolnej części instrukcji, która może spowodować jej oczekiwanie, pod warunkiem, że warunek zostanie ostatecznie rozwiązany, a wszelkie wyniki złych domysłów zostaną skutecznie cofnięte. To właśnie tego typu spekulacje wewnątrz instrukcji stoją za wszystkimi wariantami błędu Meltdown, w tym jego prawdopodobnie bardziej niebezpieczną wersją, zapowiedzią.
wgląd, który umożliwia ataki spekulacyjne, jest taki: podczas missspeculation nie ma zmian, które program może bezpośrednio obserwować. Innymi słowy, nie ma programu, który mógłby napisać, że po prostu wyświetla dane wygenerowane podczas spekulacyjnego wykonania. Jednak fakt, że spekulacje mają miejsce, pozostawia ślady, wpływając na czas wykonania instrukcji. I, niestety, teraz jest jasne, że możemy wykryć te sygnały czasowe i wydobyć z nich tajne dane.
co to za informacja o czasie i jak haker ją zdobywa? Aby to zrozumieć, musisz zrozumieć koncepcję kanałów bocznych. Kanał boczny jest niezamierzoną ścieżką, która przecieka informacje z jednego podmiotu do drugiego (zwykle oba są programami), zwykle za pośrednictwem wspólnego zasobu, takiego jak dysk twardy lub pamięć.
jako przykład ataku bocznego, rozważ urządzenie, które jest zaprogramowane do słuchania dźwięku emitowanego przez drukarkę, a następnie wykorzystuje ten dźwięk do wydedukowania, co jest drukowane. Dźwięk w tym przypadku jest kanałem bocznym.
w mikroprocesorach każdy udostępniony zasób sprzętowy może być zasadniczo używany jako kanał boczny, który wycieka informacje z programu ofiary do programu atakującego. W powszechnie używanym ataku na kanał boczny, współdzielonym zasobem jest pamięć podręczna procesora. Pamięć podręczna jest stosunkowo małą, szybko dostępną pamięcią na chipie procesora używaną do przechowywania danych najczęściej potrzebnych programowi. Gdy program uzyskuje dostęp do pamięci, procesor najpierw sprawdza pamięć podręczną; jeśli dane tam są (trafienie pamięci podręcznej), są one szybko odzyskiwane. Jeśli danych nie ma w pamięci podręcznej (brak), procesor musi poczekać, aż zostanie pobrany z pamięci głównej, która może potrwać kilkaset cykli zegara. Ale gdy dane dotrą z pamięci głównej, są dodawane do pamięci podręcznej, co może wymagać wyrzucenia innych danych, aby zrobić miejsce. Pamięć podręczna jest podzielona na segmenty zwane zestawami pamięci podręcznej, a każda lokalizacja w pamięci głównej ma odpowiedni zestaw w pamięci podręcznej. Ta organizacja ułatwia sprawdzenie, czy coś znajduje się w pamięci podręcznej, bez konieczności przeszukiwania całości.
ataki oparte na pamięci podręcznej były szeroko badane jeszcze przed pojawieniem się Spectre I Meltdown na scenie. Chociaż atakujący nie może bezpośrednio odczytać danych ofiary-nawet jeśli dane te znajdują się w zasobie udostępnionym, takim jak pamięć podręczna—atakujący może uzyskać informacje o adresach pamięci, do których ma dostęp ofiara. Adresy te mogą zależeć od poufnych danych, co pozwala sprytnemu atakującemu odzyskać te tajne dane.
jak atakujący to robi? Istnieje kilka możliwych sposobów. Jedna z odmian, zwana Flush i Reload, rozpoczyna się od usunięcia przez atakującego udostępnionych danych z pamięci podręcznej za pomocą instrukcji „flush”. Atakujący czeka, aż ofiara uzyska dostęp do tych danych. Ponieważ nie ma go już w pamięci podręcznej, wszelkie dane, o które prosi ofiara, muszą zostać pobrane z pamięci głównej. Później atakujący uzyskuje dostęp do udostępnionych danych, mierząc czas, jaki to trwa. Trafienie w pamięć podręczną—co oznacza, że dane są z powrotem w pamięci podręcznej-oznacza, że ofiara uzyskała dostęp do danych. Brak pamięci podręcznej oznacza, że nie uzyskano dostępu do danych. Tak więc, po prostu mierząc, ile czasu zajęło uzyskanie dostępu do danych, atakujący może określić, które zestawy pamięci podręcznej były dostępne dla ofiary. Potrzeba trochę magii algorytmicznej, ale ta wiedza o tym, które zestawy pamięci podręcznej były dostępne, a które nie były, może prowadzić do odkrycia kluczy szyfrujących i innych tajemnic.
Meltdown, Spectre i ich warianty są zgodne z tym samym wzorem. Po pierwsze, wywołują spekulacje, aby wykonać kod pożądany przez atakującego. Ten kod odczytuje tajne dane bez pozwolenia. Następnie ataki przekazują sekret za pomocą Flush i Reload lub podobnego kanału bocznego. Ta ostatnia część jest dobrze zrozumiana i podobna we wszystkich wariantach ataku. Tak więc ataki różnią się tylko w pierwszym komponencie, czyli jak wyzwalać i wykorzystywać spekulacje.
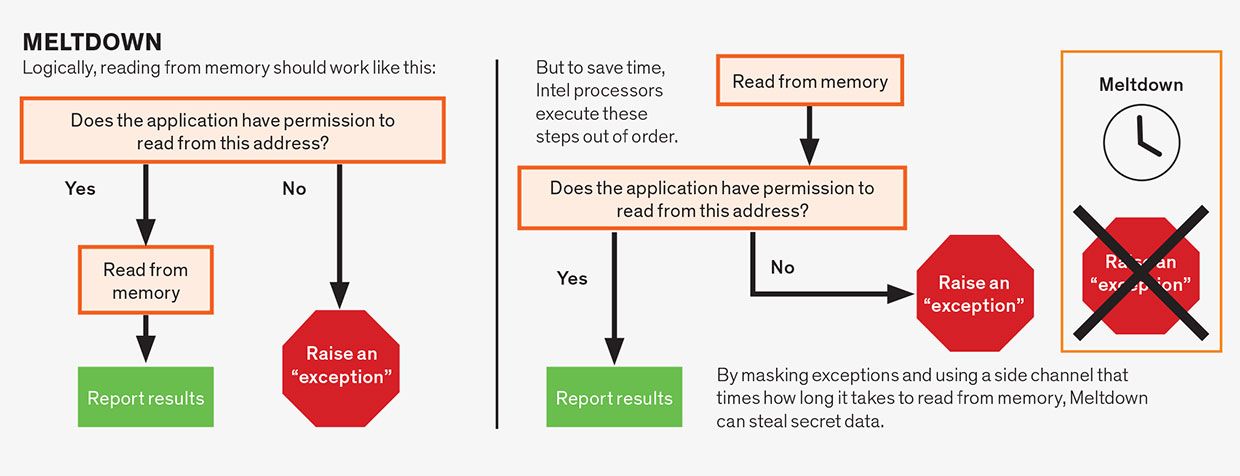
ataki typu Meltdown
ataki typu Meltdown wykorzystują spekulacje w ramach jednej instrukcji. Chociaż instrukcje assembly-language są zazwyczaj proste, pojedyncza Instrukcja często składa się z wielu operacji, które mogą zależeć od siebie nawzajem. Na przykład operacje odczytu pamięci są często zależne od instrukcji spełniającej uprawnienia związane z odczytywanym adresem pamięci. Aplikacja zwykle ma uprawnienia do odczytu tylko z pamięci, która została do niej przypisana, a nie z pamięci przydzielonej np. systemowi operacyjnemu lub programowi innego użytkownika. Logicznie rzecz biorąc, powinniśmy sprawdzić uprawnienia przed pozwoleniem na kontynuowanie odczytu, co robią niektóre mikroprocesory, zwłaszcza te z AMD. Jednak pod warunkiem, że końcowy wynik jest poprawny, projektanci procesorów zakładali, że mogą spekulacyjnie wykonywać te operacje nie po kolei. Dlatego mikroprocesory Intela odczytują lokalizację pamięci przed sprawdzeniem uprawnień, ale tylko „zatwierdzają” instrukcję—dzięki czemu wyniki są widoczne dla programu—gdy uprawnienia są spełnione. Ale ponieważ tajne dane zostały pobrane spekulacyjnie, można je odkryć za pomocą bocznego kanału, co czyni procesory Intela podatnymi na ten atak.
atak Foreshadow jest odmianą luki Meltdown. Atak ten dotyczy mikroprocesorów Intela z powodu słabości, którą Intel określa jako L1 Terminal Fault (L1tf). Podczas gdy oryginalny atak Meltdown polegał na opóźnieniu w sprawdzaniu uprawnień, Foreshadow opiera się na spekulacjach, które mają miejsce podczas etapu potoku zwanego tłumaczeniem adresu.
oprogramowanie postrzega pamięć i zasoby pamięci komputera jako pojedynczy przyległy odcinek pamięci wirtualnej. Ale fizycznie zasoby te są dzielone i dzielone między różne programy i procesy. Translacja adresów zamienia wirtualny adres pamięci w fizyczny adres pamięci.
wyspecjalizowane obwody mikroprocesora pomagają w tłumaczeniu adresów pamięci wirtualnej na fizyczną, ale może to być powolne, wymagające wielokrotnego wyszukiwania pamięci. Aby przyspieszyć proces, mikroprocesory Intela pozwalają na spekulacje podczas procesu tłumaczenia, umożliwiając programowi spekulatywne odczytywanie zawartości części pamięci podręcznej o nazwie L1, niezależnie od tego, kto jest właścicielem tych danych. Atakujący może to zrobić, a następnie ujawnić dane za pomocą podejścia side-channel, które już opisaliśmy.
pod pewnymi względami jest bardziej niebezpieczny niż Meltdown, pod innymi względami jest mniejszy. W przeciwieństwie do Meltdown, Foreshadow może odczytywać zawartość Tylko pamięci podręcznej L1, ze względu na specyfikę implementacji przez Intela architektury procesorów. Jednak Foreshadow może odczytać dowolną zawartość w L1-nie tylko dane adresowalne przez program.
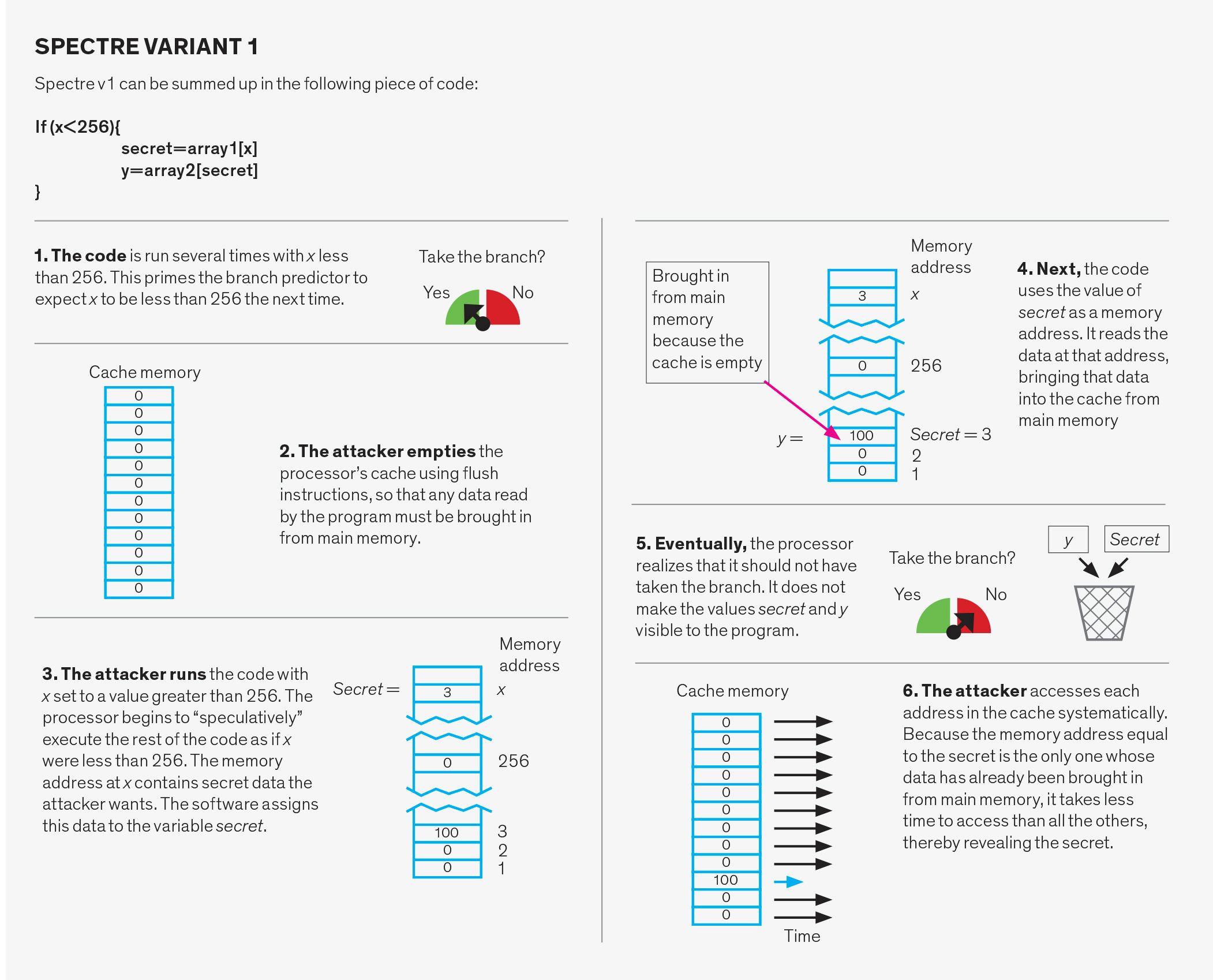
ataki Spectre
ataki Spectre manipulują systemem odgałęzień. System ten składa się z trzech części: predyktora kierunku gałęzi, predyktora celu gałęzi i bufora stosu zwrotnego.
predyktor branch-direction przewiduje, czy Branch warunkowy, taki jak ten używany do implementacji instrukcji „if” w języku programowania, zostanie pobrany czy nie. Aby to zrobić, śledzi poprzednie zachowanie podobnych gałęzi. Na przykład, może to oznaczać, że jeśli gałąź jest pobierana dwa razy z rzędu, przyszłe prognozy powiedzą, że powinna zostać pobrana.
predyktor branch-target przewiduje docelowy adres pamięci tzw. gałęzi pośrednich. W gałęzi warunkowej adres następnej instrukcji jest wypisywany, ale dla gałęzi pośredniej adres ten musi być najpierw obliczony. System przewidujący te wyniki to struktura bufora zwana buforem branch-target. Zasadniczo śledzi ostatni obliczony cel oddziałów pośrednich i wykorzystuje je do przewidywania, do czego powinien prowadzić następny oddział pośredni.
bufor stosu zwrotnego służy do przewidywania celu instrukcji „return”. Kiedy podprogram jest „wywoływany” podczas programu, Instrukcja return powoduje, że program wznawia pracę w punkcie, z którego podprogram został wywołany. Próba przewidzenia właściwego punktu, do którego należy powrócić na podstawie wcześniejszych adresów zwrotnych nie zadziała, ponieważ ta sama funkcja może być wywoływana z wielu różnych lokalizacji w kodzie. Zamiast tego, system używa bufora stosu zwrotnego, fragmentu Pamięci PROCESORA, który przechowuje adresy zwrotne funkcji, tak jak są one wywoływane. Następnie używa tych adresów, gdy napotkany jest zwrot w kodzie podprogramu.
każda z tych trzech struktur może być wykorzystana na dwa różne sposoby. Po pierwsze, predyktor może zostać celowo źle potraktowany. W tym przypadku atakujący wykonuje pozornie niewinny kod zaprojektowany, aby wstrząsnąć systemem. Później atakujący celowo wykonuje gałąź, która nie będzie się sprawdzać, powodując, że program przeskoczy do fragmentu kodu wybranego przez atakującego, zwanego gadżetem. Następnie Gadżet ustawia kradzież danych.
drugi sposób ataku widmowego nazywa się bezpośrednim wstrzyknięciem. Okazuje się, że w pewnych warunkach trzy predyktory są dzielone między różne programy. Oznacza to, że atakujący program może wypełniać struktury predyktora starannie dobranymi złymi danymi podczas wykonywania. Gdy nieświadoma ofiara wykonuje swój program w tym samym czasie co osoba atakująca lub później, ofiara używa stanu predyktora wypełnionego przez osobę atakującą i nieświadomie uruchamia Gadżet. Ten drugi atak jest szczególnie niepokojący, ponieważ pozwala atakować program ofiary z innego programu. Takie zagrożenie jest szczególnie szkodliwe dla dostawców usług w chmurze, ponieważ nie mogą oni zagwarantować ochrony danych swoich klientów.
luki Spectre I Meltdown stanowiły zagadkę dla przemysłu komputerowego, ponieważ luka ta pochodzi ze sprzętu. W niektórych przypadkach najlepszym, co możemy zrobić dla istniejących systemów-które stanowią większość zainstalowanych serwerów i komputerów-jest próba przepisania oprogramowania w celu ograniczenia szkód. Ale rozwiązania te są doraźne, niekompletne i często skutkują dużym uderzeniem W wydajność komputera. Jednocześnie badacze i projektanci procesorów zaczęli zastanawiać się, jak zaprojektować przyszłe procesory, które utrzymają spekulacje bez uszczerbku dla bezpieczeństwa.
jedna obrona, zwana Kernel page-table isolation (KPTI) , jest teraz wbudowana w Linuksa i inne systemy operacyjne. Przypomnijmy, że każda aplikacja postrzega pamięć i zasoby pamięci masowej komputera jako pojedynczy przylegający fragment pamięci wirtualnej. Ale fizycznie zasoby te są dzielone i dzielone między różne programy i procesy. Tabela stron jest zasadniczo mapą systemu operacyjnego, informującą, które części adresu pamięci wirtualnej odpowiadają danym adresom pamięci fizycznej. Tabela stron jądra jest odpowiedzialna za to dla rdzenia systemu operacyjnego. KPTI i podobne systemy chronią się przed stopieniem, czyniąc tajne dane w pamięci, takie jak system operacyjny, niedostępnymi, gdy uruchomiony jest program użytkownika (i potencjalnie program atakującego). Robi to poprzez usunięcie zabronionych części z tabeli stron. W ten sposób nawet spekulatywnie wykonany kod nie może uzyskać dostępu do danych. Jednak to rozwiązanie oznacza dodatkową pracę dla systemu operacyjnego, aby zmapować te strony podczas ich wykonywania i usunąć je później.
kolejna klasa obrony daje programistom zestaw narzędzi do ograniczania niebezpiecznych spekulacji. Na przykład, Google ’ s Retpoline patch przepisuje rodzaj gałęzi, które są podatne na Spectre Variant 2, tak że zmusza spekulacje do celowania w łagodny, pusty Gadżet. Programiści mogą również dodać instrukcję assembly-language, która ogranicza Spectre v1, ograniczając odczyty pamięci spekulacyjnej, które następują po gałęziach warunkowych. Wygodnie, ta instrukcja jest już obecna w architekturze procesora i jest używana do wymuszania poprawnej kolejności między operacjami pamięci pochodzącymi z różnych rdzeni procesora.
jako projektanci procesorów, Intel i AMD musieli pójść głębiej niż zwykły patch oprogramowania. Ich poprawki aktualizują mikrokod procesora. Mikrokod jest warstwą instrukcji, która mieści się między językiem asemblacji zwykłego oprogramowania a rzeczywistym obwodem procesora. Mikrokod dodaje elastyczność do zestawu instrukcji, które procesor może wykonać. Ułatwia to również projektowanie procesora, ponieważ podczas korzystania z mikrokodu złożone instrukcje są tłumaczone na wiele prostszych instrukcji, które są łatwiejsze do wykonania w potoku.
zasadniczo Intel i AMD dostosowali swój mikrokod, aby zmienić zachowanie niektórych instrukcji assembly-language w sposób, który ogranicza spekulacje. Na przykład inżynierowie Intela dodali opcje, które zakłócają niektóre ataki, umożliwiając systemowi operacyjnemu opróżnienie struktur branch-predictor w pewnych okolicznościach.
inna klasa rozwiązań próbuje zakłócić zdolność atakującego do przesyłania danych za pomocą kanałów bocznych. Na przykład technologia DAWG MIT bezpiecznie dzieli pamięć podręczną procesora, dzięki czemu różne programy nie udostępniają żadnych zasobów. Najbardziej ambitnie, istnieją propozycje nowych architektur procesorów, które wprowadzałyby struktury na procesorze, które są dedykowane spekulacji i oddzielone od pamięci podręcznej procesora i innego sprzętu. W ten sposób wszelkie operacje, które są wykonywane spekulatywnie, ale nie są ostatecznie popełnione, nigdy nie są widoczne. Jeśli wynik spekulacji zostanie potwierdzony, dane spekulacyjne są wysyłane do głównych struktur procesora.
luki spekulacyjne były uśpione w procesorach od ponad 20 lat i pozostały, o ile ktokolwiek wie, niewykorzystane. Ich odkrycie znacznie wstrząsnęło branżą i podkreśliło, że cyberbezpieczeństwo jest nie tylko problemem dla Systemów Oprogramowania, ale także dla sprzętu. Od czasu pierwszego odkrycia ujawniono około tuzina wariantów Spectre I Meltdown i prawdopodobnie jest ich więcej. Spectre I Meltdown są przecież efektami ubocznymi podstawowych zasad projektowania, na których polegaliśmy, aby poprawić wydajność komputera, co utrudnia wyeliminowanie takich luk w obecnych projektach systemów. Jest prawdopodobne, że nowe konstrukcje procesorów będą ewoluować, aby zachować spekulacje, jednocześnie zapobiegając rodzajowi wycieku kanału bocznego, który umożliwia te ataki. Niemniej jednak, przyszli projektanci systemów komputerowych, w tym projektujący układy procesorowe, muszą być świadomi konsekwencji związanych z bezpieczeństwem swoich decyzji i nie muszą już optymalizować tylko pod względem wydajności, rozmiaru i mocy.
o autorze
Nael Abu-Ghazaleh jest przewodniczącym programu Inżynierii Komputerowej na Uniwersytecie Kalifornijskim w Riverside. Dmitry Evtyushkin jest adiunktem informatyki w College of William And Mary, w Williamsburg, Va. Dmitrij Ponomariew jest profesorem informatyki na State University of New York w Binghamton.
aby zbadać dalej
Paul Kocher i inni badacze, którzy wspólnie ujawnili widmo, najpierw wyjaśnili to tutaj . Moritz Lipp wyjaśnił Meltdown w tym przemówieniu na Usenix Security ’ 18. Zapowiedź została szczegółowo omówiona na tej samej konferencji.
grupa badaczy, w tym jeden z autorów, opracowała systematyczną ocenę ataków widmowych i Meltdown, które odkrywają dodatkowe potencjalne ataki . Inżynierowie IBM zrobili coś podobnego, a inżynierowie Google doszli ostatnio do wniosku, że ataki typu side-channel i spekulacyjne egzekucje zostaną.