Un regard approfondi sur ces exploitations dangereuses des vulnérabilités des microprocesseurs et pourquoi il pourrait y en avoir davantage

Nous avons l’habitude de considérer les processeurs informatiques comme des machines ordonnées qui passent d’une simple instruction à l’autre avec une régularité totale. Mais la vérité est que depuis des décennies, ils font leurs tâches en désordre et ne font que deviner ce qui devrait suivre. Ils sont très doués, bien sûr. Si bonne en fait, que cette capacité, appelée exécution spéculative, a soutenu une grande partie de l’amélioration de la puissance de calcul au cours des 25 dernières années environ. Mais le 3 janvier 2018, le monde a appris que cette astuce, qui avait tant fait pour l’informatique moderne, était désormais l’une de ses plus grandes vulnérabilités.
Tout au long de 2017, des chercheurs de Cyberus Technology, de Google Project Zero, de l’Université de technologie de Graz, de Rambus, de l’Université d’Adélaïde et de l’Université de Pennsylvanie, ainsi que des chercheurs indépendants tels que le cryptographe Paul Kocher, ont élaboré séparément des attaques qui ont profité d’une exécution spéculative. Notre propre groupe avait découvert la vulnérabilité originale derrière l’une de ces attaques en 2016, mais nous n’avons pas rassemblé toutes les pièces.
Ces types d’attaques, appelées Meltdown et Spectre, n’étaient pas des bogues ordinaires. Au moment de sa découverte, Meltdown pouvait pirater tous les microprocesseurs Intel x86 et les processeurs de puissance IBM, ainsi que certains processeurs basés sur ARM. Spectre et ses nombreuses variantes ont ajouté des processeurs Advanced Micro Devices (AMD) à cette liste. En d’autres termes, presque tout le monde de l’informatique était vulnérable.
Et comme l’exécution spéculative est largement intégrée au matériel du processeur, la correction de ces vulnérabilités n’a pas été une tâche facile. Cela sans faire passer les vitesses de calcul à la vitesse basse a rendu les choses encore plus difficiles. En fait, un an après, le travail est loin d’être terminé. Des correctifs de sécurité étaient nécessaires non seulement auprès des fabricants de processeurs, mais également auprès de ceux situés plus en bas de la chaîne d’approvisionnement, tels qu’Apple, Dell, Linux et Microsoft. Les premiers ordinateurs alimentés par des puces intentionnellement conçues pour résister même à certaines de ces vulnérabilités ne sont arrivés que récemment.
Spectre et Meltdown sont le résultat de la différence entre ce que le logiciel est censé faire et la microarchitecture du processeur — les détails de la façon dont il fait réellement ces choses. Ces deux classes de hacks ont découvert un moyen de fuite d’informations à travers cette différence. Et il y a tout lieu de croire que d’autres moyens seront découverts. Nous avons aidé à en trouver deux, Branchscope et SpectreRSB, l’année dernière.
Si nous voulons maintenir le rythme des améliorations informatiques sans sacrifier la sécurité, nous allons devoir comprendre comment ces vulnérabilités matérielles se produisent. Et cela commence par comprendre Spectre et Meltdown.
Dans les systèmes informatiques modernes, les logiciels écrits dans des langages compréhensibles par l’homme tels que C++ sont compilés en instructions en langage d’assemblage — des opérations fondamentales que le processeur de l’ordinateur peut exécuter. Pour accélérer l’exécution, les processeurs modernes utilisent une approche appelée pipelining. Comme une chaîne de montage, le pipeline est une série d’étapes, chacune étant une étape nécessaire pour compléter une instruction. Certaines étapes typiques d’un processeur Intel x86 incluent celles qui apportent l’instruction de la mémoire et la décodent pour comprendre ce que signifie l’instruction. Le pipelining réduit fondamentalement le parallélisme au niveau de l’exécution des instructions: Lorsqu’une instruction est effectuée à l’aide d’une étape, l’instruction suivante est libre de l’utiliser.
Depuis les années 1990, les microprocesseurs se sont appuyés sur deux astuces pour accélérer le processus de pipeline: l’exécution hors service et la spéculation. Si deux instructions sont indépendantes l’une de l’autre — c’est—à-dire que la sortie de l’une n’affecte pas l’entrée d’une autre – elles peuvent être réorganisées et leur résultat sera toujours correct. C’est utile, car cela permet au processeur de continuer à fonctionner si une instruction bloque dans le pipeline. Par exemple, si une instruction nécessite des données qui sont dans la mémoire principale de la DRAM plutôt que dans la mémoire cache située dans le processeur lui-même, il peut prendre quelques centaines de cycles d’horloge pour obtenir ces données. Au lieu d’attendre, le processeur peut déplacer une autre instruction dans le pipeline.
La deuxième astuce est la spéculation. Pour le comprendre, commencez par le fait que certaines instructions conduisent nécessairement à un changement dans lequel les instructions viennent ensuite. Considérons un programme contenant une instruction « if »: Il vérifie une condition, et si la condition est vraie, le processeur saute à un emplacement différent dans le programme. Ceci est un exemple d’instruction de branche conditionnelle, mais il existe d’autres instructions qui entraînent également des modifications du flux d’instructions.
Considérez maintenant ce qui se passe lorsqu’une telle instruction de branche entre dans un pipeline. C’est une situation qui mène à une énigme. Lorsque l’instruction arrive au début du pipeline, nous ne connaissons pas son résultat tant qu’elle n’a pas progressé assez profondément dans le pipeline. Et sans connaître ce résultat, nous ne pouvons pas aller chercher l’instruction suivante. Une solution simple mais naïve consiste à empêcher de nouvelles instructions d’entrer dans le pipeline jusqu’à ce que l’instruction de branche atteigne un point auquel nous savons d’où viendra l’instruction suivante. De nombreux cycles d’horloge sont gaspillés dans ce processus, car les pipelines ont généralement 15 à 25 étapes. Pire encore, les instructions de branche apparaissent assez souvent, représentant plus de 20% de toutes les instructions de nombreux programmes.
Pour éviter le coût élevé des performances lié au blocage du pipeline, les processeurs modernes utilisent une unité architecturale appelée prédicteur de branche pour deviner d’où viendra l’instruction suivante, après une branche. Le but de ce prédicteur est de spéculer sur quelques points clés. Premièrement, une branche conditionnelle sera-t-elle prise, ce qui fera virer le programme vers une section différente du programme, ou continuera-t-elle sur le chemin existant? Et deuxièmement, si la branche est prise, où ira le programme — quelle sera la prochaine instruction? Armé de ces prédictions, le pipeline du processeur peut être rempli.
Parce que l’exécution de l’instruction est basée sur une prédiction, elle est exécutée « spéculativement »: Si la prédiction est correcte, les performances s’améliorent considérablement. Mais si la prédiction s’avère incorrecte, le processeur doit pouvoir annuler les effets de toute instruction exécutée de manière spéculative relativement rapidement.
La conception du prédicteur de branche fait l’objet de recherches approfondies dans la communauté de l’architecture informatique depuis de nombreuses années. Les prédicteurs modernes utilisent l’historique d’exécution d’un programme comme base de leurs résultats. Ce schéma permet d’obtenir des précisions supérieures à 95% sur de nombreux types de programmes différents, ce qui entraîne des améliorations spectaculaires des performances, par rapport à un microprocesseur qui ne spécule pas. Une erreur de spécification, cependant, est possible. Et malheureusement, c’est une erreur de spécification que les attaques de Spectre exploitent.
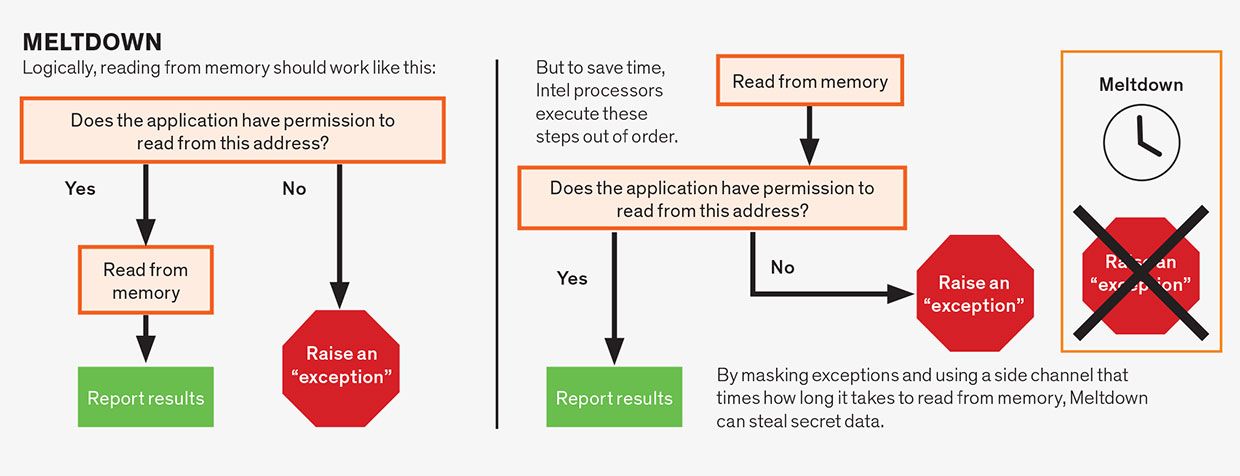
Une autre forme de spéculation qui a conduit à des problèmes est la spéculation au sein d’une seule instruction en cours. C’est un concept assez abstrait, alors déballons-le. Supposons qu’une instruction nécessite une autorisation d’exécution. Par exemple, une instruction pourrait ordonner à l’ordinateur d’écrire un morceau de données dans la partie de mémoire réservée au cœur du système d’exploitation. Vous ne voudriez pas que cela se produise, à moins que cela ne soit sanctionné par le système d’exploitation lui-même, ou que vous risquiez de planter l’ordinateur. Avant la découverte de Meltdown et Spectre, la sagesse conventionnelle était qu’il était acceptable de commencer à exécuter l’instruction de manière spéculative avant même que le processeur n’ait atteint le point de vérifier si l’instruction a ou non la permission de faire son travail.
Au final, si l’autorisation n’est pas satisfaite — dans notre exemple, le système d’exploitation n’a pas sanctionné cette tentative de jouer avec sa mémoire — les résultats sont rejetés et le programme indique une erreur. En général, le processeur peut spéculer sur n’importe quelle partie d’une instruction qui pourrait la faire attendre, à condition que la condition soit finalement résolue et que les résultats de mauvaises suppositions soient effectivement annulés. C’est ce type de spéculation intra-instruction qui est à l’origine de toutes les variantes du bogue Meltdown, y compris sa version sans doute plus dangereuse, Préfiguration.
L’aperçu qui permet les attaques de spéculation est le suivant: Lors d’une erreur de spécification, aucun changement ne se produit qu’un programme peut observer directement. En d’autres termes, il n’y a aucun programme que vous pourriez écrire qui afficherait simplement les données générées lors d’une exécution spéculative. Cependant, le fait que la spéculation se produise laisse des traces en affectant le temps nécessaire à l’exécution des instructions. Et, malheureusement, il est maintenant clair que nous pouvons détecter ces signaux de synchronisation et en extraire des données secrètes.
Quelles sont ces informations de synchronisation et comment un pirate informatique s’en empare-t-il? Pour comprendre cela, vous devez saisir le concept de canaux latéraux. Un canal latéral est une voie involontaire qui fuit des informations d’une entité à une autre (généralement les deux sont des programmes logiciels), généralement via une ressource partagée telle qu’un disque dur ou une mémoire.
À titre d’exemple d’attaque par canal latéral, considérons un appareil programmé pour écouter le son émanant d’une imprimante et qui utilise ensuite ce son pour déduire ce qui est imprimé. Le son, dans ce cas, est un canal latéral.
Dans les microprocesseurs, toute ressource matérielle partagée peut, en principe, être utilisée comme un canal latéral qui transmet des informations d’un programme victime à un programme attaquant. Dans une attaque par canal latéral couramment utilisée, la ressource partagée est le cache du processeur. Le cache est une mémoire à accès rapide relativement petite sur la puce du processeur utilisée pour stocker les données les plus fréquemment nécessaires à un programme. Lorsqu’un programme accède à la mémoire, le processeur vérifie d’abord le cache; si les données sont là (un coup de cache), elles sont récupérées rapidement. Si les données ne sont pas dans le cache (un manque), le processeur doit attendre qu’elles soient récupérées de la mémoire principale, ce qui peut prendre plusieurs centaines de cycles d’horloge. Mais une fois que les données arrivent de la mémoire principale, elles sont ajoutées au cache, ce qui peut nécessiter de jeter d’autres données pour faire de la place. Le cache est divisé en segments appelés ensembles de cache, et chaque emplacement de la mémoire principale a un ensemble correspondant dans le cache. Cette organisation permet de vérifier facilement si quelque chose se trouve dans le cache sans avoir à rechercher le tout.
Les attaques basées sur le cache avaient fait l’objet de recherches approfondies avant même que Spectre et Meltdown n’apparaissent sur les lieux. Bien que l’attaquant ne puisse pas lire directement les données de la victime, même lorsque ces données se trouvent dans une ressource partagée comme le cache, il peut obtenir des informations sur les adresses mémoire auxquelles la victime a accédé. Ces adresses peuvent dépendre de données sensibles, permettant à un attaquant intelligent de récupérer ces données secrètes.
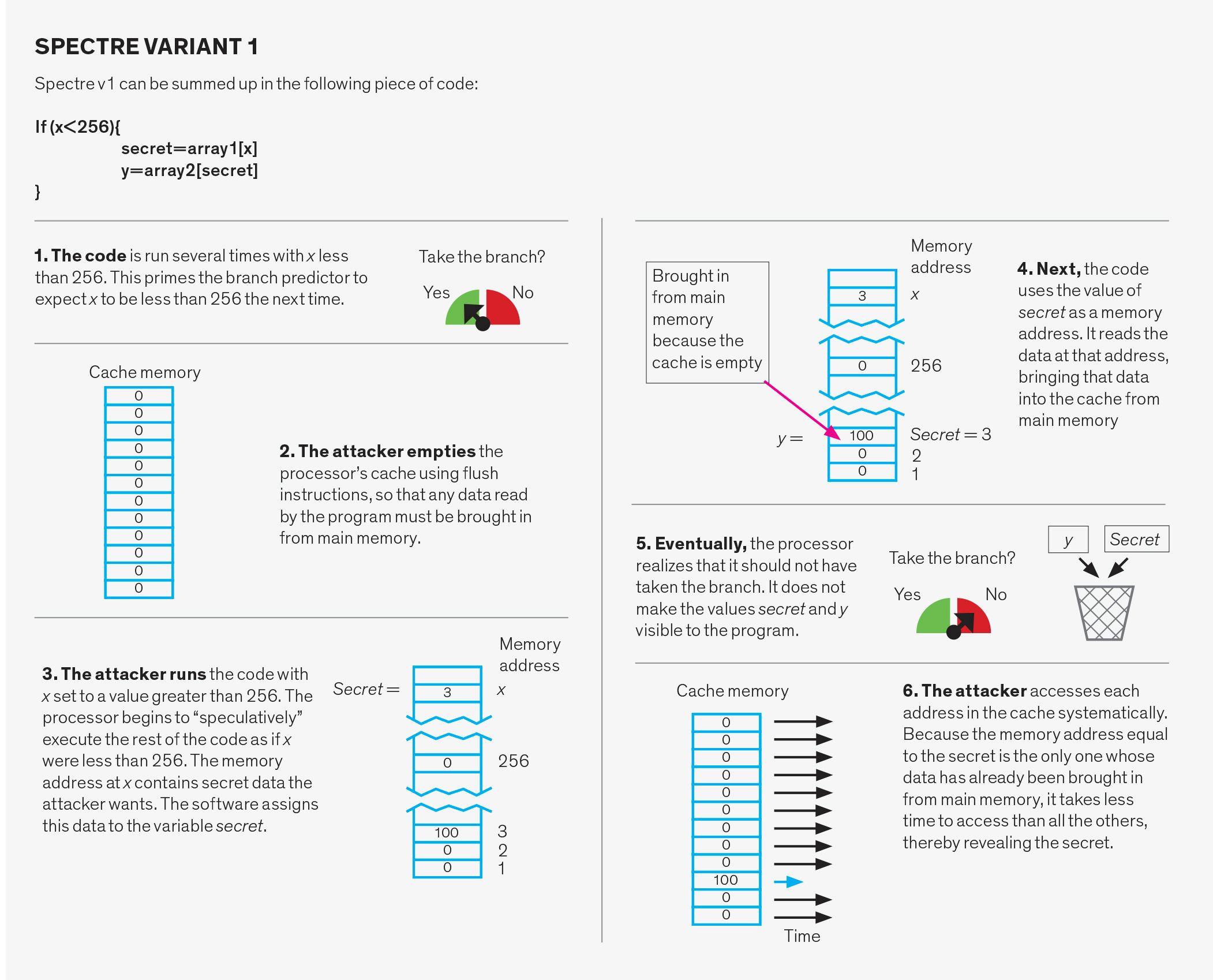
Comment l’attaquant fait-il cela? Il y a plusieurs façons possibles. Une variante, appelée Vidage et rechargement, commence par la suppression par l’attaquant des données partagées du cache à l’aide de l’instruction » vidage « . L’attaquant attend ensuite que la victime accède à ces données. Comme il n’est plus dans le cache, toutes les données demandées par la victime doivent être entrées de la mémoire principale. Plus tard, l’attaquant accède aux données partagées tout en chronométrant le temps que cela prend. Un accès au cache — ce qui signifie que les données sont de retour dans le cache – indique que la victime a accédé aux données. Un manque de cache indique que les données n’ont pas été consultées. Ainsi, simplement en mesurant le temps qu’il a fallu pour accéder aux données, l’attaquant peut déterminer les ensembles de cache auxquels la victime a accédé. Il faut un peu de magie algorithmique, mais cette connaissance des ensembles de cache auxquels on a accédé et qui ne l’ont pas été peut conduire à la découverte de clés de chiffrement et d’autres secrets.
Meltdown, Spectre et leurs variantes suivent toutes le même schéma. Tout d’abord, ils déclenchent des spéculations pour exécuter le code souhaité par l’attaquant. Ce code lit des données secrètes sans autorisation. Ensuite, les attaques communiquent le secret en utilisant Flush et Reload ou un canal latéral similaire. Cette dernière partie est bien comprise et similaire dans toutes les variantes d’attaque. Ainsi, les attaques ne diffèrent que par le premier composant, qui est de savoir comment déclencher et exploiter la spéculation.
Attaques par fusion
Les attaques par fusion exploitent la spéculation au sein d’une seule instruction. Bien que les instructions en langage d’assemblage soient généralement simples, une seule instruction consiste souvent en plusieurs opérations qui peuvent dépendre les unes des autres. Par exemple, les opérations de lecture en mémoire dépendent souvent de l’instruction satisfaisant aux permissions associées à l’adresse mémoire en cours de lecture. Une application a généralement l’autorisation de lire uniquement à partir de la mémoire qui lui a été attribuée, et non de la mémoire allouée, par exemple, au système d’exploitation ou au programme d’un autre utilisateur. Logiquement, nous devrions vérifier les autorisations avant de permettre à la lecture de continuer, ce que font certains microprocesseurs, notamment ceux d’AMD. Cependant, à condition que le résultat final soit correct, les concepteurs de CPU ont supposé qu’ils étaient libres d’exécuter spéculativement ces opérations hors service. Par conséquent, les microprocesseurs Intel lisent l’emplacement de la mémoire avant de vérifier les autorisations, mais ne « valident » l’instruction — rendant les résultats visibles pour le programme — que lorsque les autorisations sont satisfaites. Mais comme les données secrètes ont été récupérées de manière spéculative, elles peuvent être découvertes à l’aide d’un canal latéral, rendant les processeurs Intel vulnérables à cette attaque.
L’attaque Foreshadow est une variante de la vulnérabilité Meltdown. Cette attaque affecte les microprocesseurs Intel en raison d’une faiblesse qu’Intel appelle Défaut de terminal L1 (L1TF). Alors que l’attaque Meltdown d’origine reposait sur un retard dans la vérification des autorisations, Foreshadow repose sur la spéculation qui se produit lors d’une étape du pipeline appelée traduction d’adresses.
Le logiciel considère la mémoire et les ressources de stockage de l’ordinateur comme un seul tronçon contigu de mémoire virtuelle qui lui est propre. Mais physiquement, ces actifs sont divisés et partagés entre différents programmes et processus. La traduction d’adresse transforme une adresse de mémoire virtuelle en une adresse de mémoire physique.
Des circuits spécialisés sur le microprocesseur aident à la traduction d’adresses mémoire virtuelle-physique, mais elle peut être lente, nécessitant plusieurs recherches de mémoire. Pour accélérer les choses, les microprocesseurs Intel permettent la spéculation pendant le processus de traduction, permettant à un programme de lire de manière spéculative le contenu d’une partie du cache appelée L1, quel que soit le propriétaire de ces données. L’attaquant peut le faire, puis divulguer les données en utilisant l’approche par canal latéral que nous avons déjà décrite.
À certains égards, la préfiguration est plus dangereuse que la fusion, à d’autres égards, elle l’est moins. Contrairement à Meltdown, Foreshadow ne peut lire que le contenu du cache L1, en raison des spécificités de la mise en œuvre par Intel de son architecture de processeur. Cependant, Foreshadow peut lire n’importe quel contenu en L1 — pas seulement des données adressables par le programme.
Attaques de spectre
Les attaques de spectre manipulent le système de prédiction de branche. Ce système comporte trois parties : le prédicteur de direction de branche, le prédicteur de cible de branche et le tampon de pile de retour.
Le prédicteur de direction de branche prédit si une branche conditionnelle, telle que celle utilisée pour implémenter une instruction » if » dans un langage de programmation, sera prise ou non. Pour ce faire, il suit le comportement précédent de branches similaires. Par exemple, cela peut signifier que si une branche est prise deux fois de suite, les prévisions futures diront qu’elle devrait être prise.
Le prédicteur cible de branche prédit l’adresse mémoire cible de ce qu’on appelle des branches indirectes. Dans une branche conditionnelle, l’adresse de l’instruction suivante est indiquée, mais pour une branche indirecte, cette adresse doit d’abord être calculée. Le système qui prédit ces résultats est une structure de cache appelée tampon cible de branche. Essentiellement, il garde une trace de la dernière cible calculée des branches indirectes et les utilise pour prédire où la prochaine branche indirecte devrait conduire.
Le tampon de pile de retour est utilisé pour prédire la cible d’une instruction « return ». Lorsqu’un sous-programme est « appelé » pendant un programme, l’instruction de retour fait que le programme reprend le travail au point à partir duquel le sous-programme a été appelé. Essayer de prédire le bon point vers lequel revenir en fonction uniquement des adresses de retour antérieures ne fonctionnera pas, car la même fonction peut être appelée à partir de nombreux emplacements différents dans le code. Au lieu de cela, le système utilise le tampon de pile de retour, un morceau de mémoire sur le processeur, qui conserve les adresses de retour des fonctions telles qu’elles sont appelées. Il utilise ensuite ces adresses lorsqu’un retour est rencontré dans le code du sous-programme.
Chacune de ces trois structures peut être exploitée de deux manières différentes. Premièrement, le prédicteur peut être délibérément maltraité. Dans ce cas, l’attaquant exécute un code apparemment innocent conçu pour brouiller le système. Plus tard, l’attaquant exécute délibérément une branche qui se trompera, ce qui fera passer le programme à un morceau de code choisi par l’attaquant, appelé gadget. Le gadget se met alors à voler des données.
Une deuxième manière d’attaque de Spectre est appelée injection directe. Il s’avère que dans certaines conditions, les trois prédicteurs sont partagés entre différents programmes. Cela signifie que le programme attaquant peut remplir les structures de prédicteurs avec des données incorrectes soigneusement choisies lors de son exécution. Lorsqu’une victime involontaire exécute son programme en même temps que l’attaquant ou par la suite, la victime utilisera l’état prédicteur qui a été rempli par l’attaquant et déclenchera involontairement un gadget. Cette deuxième attaque est particulièrement inquiétante car elle permet à un programme victime d’être attaqué à partir d’un programme différent. Une telle menace est particulièrement dommageable pour les fournisseurs de services cloud car ils ne peuvent alors pas garantir la protection des données de leurs clients.
Les vulnérabilités Spectre et Meltdown ont présenté une énigme à l’industrie informatique car la vulnérabilité provient du matériel. Dans certains cas, le mieux que nous puissions faire pour les systèmes existants — qui constituent la majeure partie des serveurs et des PC installés — est d’essayer de réécrire le logiciel pour tenter de limiter les dommages. Mais ces solutions sont ad hoc, incomplètes et entraînent souvent un gros coup sur les performances de l’ordinateur. Dans le même temps, les chercheurs et les concepteurs de processeurs ont commencé à réfléchir à la façon de concevoir de futurs PROCESSEURS qui maintiennent la spéculation sans compromettre la sécurité.
Une défense, appelée kernel page-table isolation (KPTI), est désormais intégrée à Linux et à d’autres systèmes d’exploitation. Rappelons que chaque application considère la mémoire et les ressources de stockage de l’ordinateur comme un seul tronçon contigu de mémoire virtuelle qui lui est propre. Mais physiquement, ces actifs sont divisés et partagés entre différents programmes et processus. La table de pages est essentiellement la carte du système d’exploitation, lui indiquant quelles parties d’une adresse de mémoire virtuelle correspondent à quelles adresses de mémoire physique. La table des pages du noyau est chargée de le faire pour le cœur du système d’exploitation. Les systèmes KPTI et similaires se défendent contre la fusion en rendant les données secrètes en mémoire, telles que le système d’exploitation, inaccessibles lorsque le programme d’un utilisateur (et potentiellement le programme d’un attaquant) est en cours d’exécution. Il le fait en supprimant les parties interdites de la table des pages. De cette façon, même le code exécuté de manière spéculative ne peut pas accéder aux données. Cependant, cette solution signifie un travail supplémentaire pour le système d’exploitation pour mapper ces pages lorsqu’il s’exécute et les démapper par la suite.
Une autre classe de défenses donne aux programmeurs un ensemble d’outils pour limiter les spéculations dangereuses. Par exemple, le patch Retpoline de Google réécrit le type de branches vulnérables à la variante Spectre 2, de sorte qu’il oblige la spéculation à cibler un gadget bénin et vide. Les programmeurs peuvent également ajouter une instruction en langage assembleur qui limite Spectre v1, en limitant les lectures de mémoire spéculatives qui suivent des branches conditionnelles. De manière pratique, cette instruction est déjà présente dans l’architecture du processeur et est utilisée pour imposer l’ordre correct entre les opérations de mémoire provenant de différents cœurs de processeur.
En tant que concepteurs de processeurs, Intel et AMD ont dû aller plus loin qu’un correctif logiciel ordinaire. Leurs correctifs mettent à jour le microcode du processeur. Le microcode est une couche d’instructions qui s’insère entre le langage d’assemblage du logiciel ordinaire et les circuits réels du processeur. Le microcode ajoute de la flexibilité à l’ensemble d’instructions qu’un processeur peut exécuter. Cela simplifie également la conception d’un processeur car lors de l’utilisation d’un microcode, les instructions complexes sont traduites en plusieurs instructions plus simples et plus faciles à exécuter dans un pipeline.
Fondamentalement, Intel et AMD ont ajusté leur microcode pour modifier le comportement de certaines instructions en langage d’assemblage de manière à limiter la spéculation. Par exemple, les ingénieurs d’Intel ont ajouté des options qui interfèrent avec certaines attaques en permettant au système d’exploitation de vider les structures prédictives de branche dans certaines circonstances.
Une autre classe de solutions tente d’interférer avec la capacité de l’attaquant à transmettre les données à l’aide de canaux latéraux. Par exemple, la technologie DAWG du MIT divise en toute sécurité le cache du processeur afin que les différents programmes ne partagent aucune de ses ressources. Plus ambitieux, il existe des propositions de nouvelles architectures de processeur qui introduiraient des structures sur le processeur dédiées à la spéculation et distinctes du cache du processeur et des autres matériels. De cette façon, toutes les opérations exécutées de manière spéculative mais qui ne sont finalement pas validées ne sont jamais visibles. Si le résultat de la spéculation est confirmé, les données spéculatives sont envoyées aux structures principales du processeur.
Les vulnérabilités de spéculation sont en sommeil dans les processeurs depuis plus de 20 ans et elles sont restées, pour autant que quelqu’un le sache, inexploitées. Leur découverte a considérablement ébranlé l’industrie et a mis en évidence le fait que la cybersécurité n’est pas seulement un problème pour les systèmes logiciels, mais également pour le matériel. Depuis la découverte initiale, une douzaine de variantes de Spectre et de Meltdown ont été révélées, et il est probable qu’il y en ait d’autres. Spectre et Meltdown sont, après tout, des effets secondaires des principes de conception de base sur lesquels nous nous sommes appuyés pour améliorer les performances de l’ordinateur, ce qui rend difficile l’élimination de telles vulnérabilités dans les conceptions de systèmes actuelles. Il est probable que de nouvelles conceptions de CPU évolueront pour conserver la spéculation, tout en empêchant le type de fuite de canal latéral qui permet ces attaques. Néanmoins, les futurs concepteurs de systèmes informatiques, y compris ceux qui conçoivent des puces de processeur, doivent être conscients des implications de leurs décisions en matière de sécurité et ne plus optimiser uniquement les performances, la taille et la puissance.
À propos de l’auteur
Nael Abu-Ghazaleh est président du programme de génie informatique de l’Université de Californie à Riverside. Dmitry Evtyushkin est professeur adjoint d’informatique au Collège de William et Mary, à Williamsburg, en Virginie. Dmitry Ponomarev est professeur d’informatique à l’Université d’État de New York à Binghamton.
Pour Sonder davantage
Paul Kocher et les autres chercheurs qui ont collectivement révélé Spectre l’ont d’abord expliqué ici. Moritz Lipp a expliqué Meltdown dans cette conférence à Usenix Security ’18. La préfiguration a été détaillée lors de la même conférence.
Un groupe de chercheurs, dont l’un des auteurs, a mis au point une évaluation systématique des attaques Spectre et Meltdown qui permet de découvrir d’autres attaques potentielles. Les ingénieurs d’IBM ont fait quelque chose de similaire, et les ingénieurs de Google sont récemment arrivés à la conclusion que les attaques à canal latéral et d’exécution spéculative sont là pour rester.