Ein detaillierter Blick auf diese gefährlichen Ausnutzungen von Mikroprozessor-Schwachstellen und warum es mehr davon geben könnte

Wir sind es gewohnt, Computerprozessoren als geordnete Maschinen zu betrachten, die mit vollständiger Regelmäßigkeit von einer einfachen Anweisung zur nächsten übergehen. Aber die Wahrheit ist, dass sie seit Jahrzehnten ihre Aufgaben nicht mehr in Ordnung machen und nur raten, was als nächstes kommen sollte. Sie sind natürlich sehr gut darin. In der Tat so gut, dass diese Fähigkeit, spekulative Ausführung genannt, einen Großteil der Verbesserung der Rechenleistung in den letzten 25 Jahren oder so untermauert hat. Aber am 3. Januar 2018 erfuhr die Welt, dass dieser Trick, der so viel für das moderne Computing getan hatte, jetzt eine seiner größten Schwachstellen war.
Im Laufe des Jahres 2017 haben Forscher von Cyberus Technology, Google Project Zero, der Technischen Universität Graz, Rambus, der University of Adelaide und der University of Pennsylvania sowie unabhängige Forscher wie der Kryptograf Paul Kocher separat Angriffe ausgearbeitet, die spekulative Ausführung ausnutzten. Unsere eigene Gruppe hatte 2016 die ursprüngliche Sicherheitslücke hinter einem dieser Angriffe entdeckt, aber wir haben nicht alle Teile zusammengefügt.
Diese Arten von Angriffen, Meltdown und Spectre genannt, waren keine gewöhnlichen Fehler. Zum Zeitpunkt der Entdeckung konnte Meltdown alle Intel x86-Mikroprozessoren und IBM Power-Prozessoren sowie einige ARM-basierte Prozessoren hacken. Spectre und seine vielen Variationen fügten dieser Liste Prozessoren von Advanced Micro Devices (AMD) hinzu. Mit anderen Worten, fast die gesamte Computerwelt war anfällig.
Und da die spekulative Ausführung weitgehend in die Prozessorhardware integriert ist, war die Behebung dieser Sicherheitsanfälligkeiten keine leichte Aufgabe. Dies zu tun, ohne dass die Rechengeschwindigkeit in einen niedrigen Gang geschaltet wird, hat es noch schwieriger gemacht. In der Tat, ein Jahr später, ist der Job noch lange nicht vorbei. Sicherheitspatches wurden nicht nur von den Prozessorherstellern benötigt, sondern auch von denjenigen, die weiter unten in der Lieferkette waren, wie Apple, Dell, Linux und Microsoft. Die ersten Computer, die mit Chips betrieben werden, die absichtlich so konzipiert sind, dass sie selbst gegen einige dieser Schwachstellen resistent sind, sind erst kürzlich eingetroffen.
Spectre und Meltdown sind das Ergebnis des Unterschieds zwischen dem, was Software tun soll, und der Mikroarchitektur des Prozessors — den Details, wie sie diese Dinge tatsächlich tun. Diese beiden Klassen von Hacks haben einen Weg aufgedeckt, wie Informationen durch diesen Unterschied austreten können. Und es gibt allen Grund zu der Annahme, dass weitere Wege aufgedeckt werden. Wir haben letztes Jahr geholfen, zwei zu finden, Branchscope und SpectreRSB.
Wenn wir das Tempo der Computerverbesserungen beibehalten wollen, ohne die Sicherheit zu beeinträchtigen, müssen wir verstehen, wie diese Hardware-Schwachstellen auftreten. Und das beginnt mit dem Verständnis von Spectre und Meltdown.
In modernen Computersystemen werden Softwareprogramme, die in für Menschen verständlichen Sprachen wie C ++ geschrieben sind, zu Anweisungen in Assemblersprache kompiliert – grundlegende Operationen, die der Computerprozessor ausführen kann. Um die Ausführung zu beschleunigen, verwenden moderne Prozessoren einen Ansatz namens Pipelining. Wie eine Montagelinie besteht die Pipeline aus einer Reihe von Stufen, von denen jede ein Schritt ist, der zum Abschließen einer Anweisung erforderlich ist. Einige typische Phasen für einen Intel x86-Prozessor umfassen solche, die die Anweisung aus dem Speicher einbringen und dekodieren, um zu verstehen, was die Anweisung bedeutet. Pipelining bringt die Parallelität grundsätzlich auf die Ebene der Befehlsausführung: Wenn eine Anweisung mit einer Stufe ausgeführt wird, kann die nächste Anweisung sie frei verwenden.
Seit den 1990er Jahren verlassen sich Mikroprozessoren auf zwei Tricks, um den Pipeline-Prozess zu beschleunigen: Out-of-Order-Ausführung und Spekulation. Wenn zwei Anweisungen unabhängig voneinander sind — das heißt, die Ausgabe einer Anweisung hat keinen Einfluss auf die Eingabe einer anderen Anweisung —, können sie neu angeordnet werden, und ihr Ergebnis ist immer noch korrekt. Dies ist hilfreich, da der Prozessor weiterarbeiten kann, wenn ein Befehl in der Pipeline zum Stillstand kommt. Wenn ein Befehl beispielsweise Daten benötigt, die sich im DRAM-Hauptspeicher und nicht im Cache-Speicher in der CPU selbst befinden, kann es einige hundert Taktzyklen dauern, bis diese Daten abgerufen werden. Anstatt zu warten, kann der Prozessor eine andere Anweisung durch die Pipeline verschieben.
Der zweite Trick ist Spekulation. Um es zu verstehen, beginnen Sie mit der Tatsache, dass einige Anweisungen notwendigerweise zu einer Änderung führen, welche Anweisungen als nächstes kommen. Stellen Sie sich ein Programm vor, das eine „if“ -Anweisung enthält: Es sucht nach einer Bedingung, und wenn die Bedingung wahr ist, springt der Prozessor an eine andere Stelle im Programm. Dies ist ein Beispiel für eine bedingte Verzweigungsanweisung, aber es gibt andere Anweisungen, die ebenfalls zu Änderungen im Befehlsfluss führen.
Überlegen Sie nun, was passiert, wenn ein solcher Verzweigungsbefehl in eine Pipeline eintritt. Es ist eine Situation, die zu einem Rätsel führt. Wenn die Anweisung am Anfang der Pipeline ankommt, kennen wir ihr Ergebnis erst, wenn sie ziemlich tief in die Pipeline eingedrungen ist. Und ohne dieses Ergebnis zu kennen, können wir die nächste Anweisung nicht abrufen. Eine einfache, aber naive Lösung besteht darin, zu verhindern, dass neue Anweisungen in die Pipeline gelangen, bis der Verzweigungsbefehl einen Punkt erreicht, an dem wir wissen, woher der nächste Befehl kommen wird. Viele Taktzyklen werden bei diesem Prozess verschwendet, da Pipelines typischerweise 15 bis 25 Stufen haben. Schlimmer noch, Verzweigungsanweisungen werden häufig angezeigt und machen in vielen Programmen mehr als 20 Prozent aller Anweisungen aus.
Um die hohen Leistungskosten für das Abwürgen der Pipeline zu vermeiden, verwenden moderne Prozessoren eine Architektureinheit, die als Verzweigungsprädiktor bezeichnet wird, um zu erraten, woher die nächste Anweisung nach einer Verzweigung kommen wird. Der Zweck dieses Prädiktors besteht darin, über einige wichtige Punkte zu spekulieren. Wird zunächst eine bedingte Verzweigung vorgenommen, die dazu führt, dass das Programm in einen anderen Abschnitt des Programms wechselt, oder wird es auf dem vorhandenen Pfad fortgesetzt? Und zweitens, wenn der Zweig genommen wird, wohin wird das Programm gehen — was wird die nächste Anweisung sein? Mit diesen Vorhersagen kann die Prozessorpipeline voll gehalten werden.
Da die Befehlsausführung auf einer Vorhersage basiert, wird sie „spekulativ“ ausgeführt: Wenn die Vorhersage korrekt ist, verbessert sich die Leistung erheblich. Wenn sich die Vorhersage jedoch als falsch erweist, muss der Prozessor in der Lage sein, die Auswirkungen spekulativ ausgeführter Anweisungen relativ schnell rückgängig zu machen.
Das Design des Branch Predictor wird in der Computer-Architektur-Community seit vielen Jahren intensiv erforscht. Moderne Prädiktoren verwenden die Ausführungshistorie innerhalb eines Programms als Grundlage für ihre Ergebnisse. Dieses Schema erreicht bei vielen verschiedenen Arten von Programmen Genauigkeiten von mehr als 95 Prozent, was zu dramatischen Leistungsverbesserungen im Vergleich zu einem Mikroprozessor führt, der nicht spekuliert. Fehlspekulationen sind jedoch möglich. Und leider ist es eine falsche Spekulation, die die Spectre-Angriffe ausnutzen.
Eine andere Form der Spekulation, die zu Problemen geführt hat, ist die Spekulation innerhalb einer einzelnen Anweisung in der Pipeline. Das ist ein ziemlich abstruses Konzept, also packen wir es aus. Angenommen, eine Anweisung erfordert die Berechtigung zum Ausführen. Zum Beispiel könnte eine Anweisung den Computer anweisen, einen Datenblock in den Teil des Speichers zu schreiben, der für den Kern des Betriebssystems reserviert ist. Sie würden nicht wollen, dass das passiert, es sei denn, es wurde vom Betriebssystem selbst sanktioniert, oder Sie würden riskieren, den Computer zum Absturz zu bringen. Vor der Entdeckung von Meltdown und Spectre war die konventionelle Weisheit, dass es in Ordnung ist, den Befehl spekulativ auszuführen, noch bevor der Prozessor den Punkt erreicht hat, an dem überprüft wird, ob der Befehl die Berechtigung hat, seine Arbeit auszuführen.
Wenn die Berechtigung nicht erfüllt ist — in unserem Beispiel hat das Betriebssystem diesen Versuch, an seinem Speicher herumzuspielen, nicht genehmigt —, werden die Ergebnisse ausgegeben und das Programm zeigt einen Fehler an. Im Allgemeinen kann der Prozessor um irgendeinen Teil einer Anweisung spekulieren, der dazu führen könnte, dass er wartet, vorausgesetzt, dass die Bedingung schließlich gelöst wird und alle Ergebnisse von schlechten Vermutungen effektiv rückgängig gemacht werden. Es ist diese Art von Intra-Instruktions-Spekulation, die hinter allen Varianten des Meltdown-Fehlers steckt, einschließlich seiner wohl gefährlicheren Version, Foreshadow.
Die Erkenntnis, die Spekulationsangriffe ermöglicht, ist folgende: Während einer Fehlspekulation tritt keine Änderung auf, die ein Programm direkt beobachten kann. Mit anderen Worten, es gibt kein Programm, das Sie schreiben könnten, das einfach Daten anzeigt, die während der spekulativen Ausführung generiert werden. Die Tatsache, dass Spekulationen auftreten, hinterlässt jedoch Spuren, indem sie beeinflusst, wie lange die Ausführung von Anweisungen dauert. Und leider ist es jetzt klar, dass wir diese Timing-Signale erkennen und geheime Daten daraus extrahieren können.
Was sind diese Timing-Informationen und wie kommt ein Hacker an sie? Um das zu verstehen, müssen Sie das Konzept der Seitenkanäle verstehen. Ein Seitenkanal ist ein unbeabsichtigter Weg, der Informationen von einer Entität zur anderen (normalerweise sind beide Softwareprogramme) überträgt, typischerweise über eine gemeinsam genutzte Ressource wie eine Festplatte oder einen Speicher.
Betrachten Sie als Beispiel für einen Seitenkanalangriff ein Gerät, das so programmiert ist, dass es den von einem Drucker ausgehenden Ton hört und diesen Ton dann verwendet, um abzuleiten, was gedruckt wird. Der Ton ist in diesem Fall ein Seitenkanal.
In Mikroprozessoren kann jede gemeinsam genutzte Hardwareressource im Prinzip als Seitenkanal verwendet werden, der Informationen von einem Opferprogramm an ein Angreiferprogramm weitergibt. Bei einem häufig verwendeten Seitenkanalangriff ist die gemeinsam genutzte Ressource der Cache der CPU. Der Cache ist ein relativ kleiner Schnellzugriffsspeicher auf dem Prozessorchip, der zum Speichern der von einem Programm am häufigsten benötigten Daten verwendet wird. Wenn ein Programm auf den Speicher zugreift, überprüft der Prozessor zuerst den Cache; Wenn die Daten vorhanden sind (ein Cache-Treffer), werden sie schnell wiederhergestellt. Wenn sich die Daten nicht im Cache befinden (ein Fehler), muss der Prozessor warten, bis sie aus dem Hauptspeicher abgerufen werden, was mehrere hundert Taktzyklen dauern kann. Sobald die Daten jedoch aus dem Hauptspeicher stammen, werden sie dem Cache hinzugefügt, sodass möglicherweise andere Daten weggeworfen werden müssen, um Platz zu schaffen. Der Cache ist in Segmente unterteilt, die als Cache-Sets bezeichnet werden, und jeder Speicherort im Hauptspeicher hat einen entsprechenden Satz im Cache. Diese Organisation macht es einfach zu überprüfen, ob sich etwas im Cache befindet, ohne das Ganze durchsuchen zu müssen.
Cache-basierte Angriffe waren bereits vor dem Erscheinen von Spectre und Meltdown ausführlich erforscht worden. Obwohl der Angreifer die Daten des Opfers nicht direkt lesen kann – selbst wenn sich diese Daten in einer gemeinsam genutzten Ressource wie dem Cache befinden —, kann der Angreifer Informationen über die Speicheradressen abrufen, auf die das Opfer zugreift. Diese Adressen können von sensiblen Daten abhängen, sodass ein cleverer Angreifer diese geheimen Daten wiederherstellen kann.
Wie macht der Angreifer das? Es gibt mehrere Möglichkeiten. Eine Variante, Flush und Reload genannt, beginnt damit, dass der Angreifer gemeinsam genutzte Daten mithilfe der Anweisung „flush“ aus dem Cache entfernt. Der Angreifer wartet dann darauf, dass das Opfer auf diese Daten zugreift. Da es sich nicht mehr im Cache befindet, müssen alle Daten, die das Opfer anfordert, aus dem Hauptspeicher abgerufen werden. Später greift der Angreifer auf die freigegebenen Daten zu, während er festlegt, wie lange dies dauert. Ein Cache-Treffer – dh die Daten befinden sich wieder im Cache — zeigt an, dass das Opfer auf die Daten zugegriffen hat. Ein Cache-Fehler zeigt an, dass nicht auf die Daten zugegriffen wurde. Indem der Angreifer einfach misst, wie lange der Zugriff auf Daten gedauert hat, kann er feststellen, auf welche Cache-Sets das Opfer zugegriffen hat. Es braucht ein bisschen algorithmische Magie, aber dieses Wissen darüber, auf welche Cache-Sets zugegriffen wurde und welche nicht, kann zur Entdeckung von Verschlüsselungsschlüsseln und anderen Geheimnissen führen.
Meltdown, Spectre und ihre Varianten folgen alle demselben Muster. Erstens lösen sie Spekulationen aus, um den vom Angreifer gewünschten Code auszuführen. Dieser Code liest geheime Daten ohne Erlaubnis. Dann kommunizieren die Angriffe das Geheimnis mit Flush und Reload oder einem ähnlichen Seitenkanal. Dieser letzte Teil ist gut verstanden und in allen Angriffsvarianten ähnlich. Daher unterscheiden sich die Angriffe nur in der ersten Komponente, nämlich wie Spekulationen ausgelöst und ausgenutzt werden.
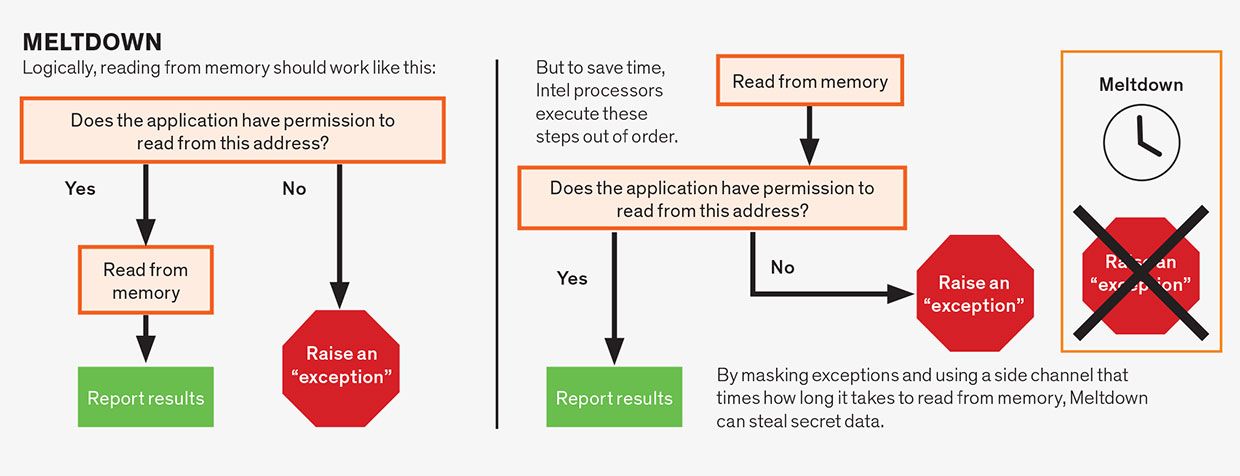
Meltdown-Angriffe
Meltdown-Angriffe nutzen Spekulationen innerhalb einer einzigen Anweisung aus. Obwohl Anweisungen in Assemblersprache normalerweise einfach sind, besteht eine einzelne Anweisung häufig aus mehreren Operationen, die voneinander abhängen können. Beispielsweise hängen Speicherleseoperationen häufig davon ab, dass der Befehl die Berechtigungen erfüllt, die der zu lesenden Speicheradresse zugeordnet sind. Eine Anwendung hat normalerweise die Berechtigung, nur aus dem ihr zugewiesenen Speicher zu lesen, nicht aus dem Speicher, der beispielsweise dem Betriebssystem oder dem Programm eines anderen Benutzers zugewiesen ist. Logischerweise sollten wir die Berechtigungen überprüfen, bevor wir das Lesen zulassen, was einige Mikroprozessoren tun, insbesondere die von AMD. Vorausgesetzt, das Endergebnis ist korrekt, gingen die CPU-Designer jedoch davon aus, dass sie diese Vorgänge spekulativ ausführen konnten. Daher lesen Intel-Mikroprozessoren den Speicherort, bevor sie die Berechtigungen überprüfen, „schreiben“ Sie die Anweisung jedoch nur dann fest, wenn die Berechtigungen erfüllt sind. Da die geheimen Daten jedoch spekulativ abgerufen wurden, können sie über einen Seitenkanal entdeckt werden, wodurch Intel-Prozessoren für diesen Angriff anfällig werden.
Der Foreshadow-Angriff ist eine Variante der Meltdown-Schwachstelle. Dieser Angriff betrifft Intel-Mikroprozessoren aufgrund einer Schwäche, die Intel als L1 Terminal Fault (L1TF) bezeichnet. Während der ursprüngliche Meltdown-Angriff auf einer Verzögerung bei der Überprüfung von Berechtigungen beruhte, stützt sich Foreshadow auf Spekulationen, die während einer Phase der Pipeline namens Adressübersetzung auftreten.
Software betrachtet den Arbeitsspeicher und die Speicherressourcen des Computers als einen einzigen zusammenhängenden Abschnitt des virtuellen Speichers. Physisch werden diese Assets jedoch auf verschiedene Programme und Prozesse aufgeteilt und gemeinsam genutzt. Die Adressübersetzung wandelt eine virtuelle Speicheradresse in eine physische Speicheradresse um.
Spezielle Schaltkreise auf dem Mikroprozessor helfen bei der Übersetzung von virtuellen in physische Speicheradressen, können jedoch langsam sein und erfordern mehrere Speichersuchen. Um die Dinge zu beschleunigen, erlauben Intel-Mikroprozessoren Spekulationen während des Übersetzungsprozesses, so dass ein Programm den Inhalt eines Teils des Cache namens L1 spekulativ lesen kann, unabhängig davon, wem diese Daten gehören. Der Angreifer kann dies tun und dann die Daten mit dem bereits beschriebenen Seitenkanalansatz offenlegen.
In mancher Hinsicht ist Foreshadow gefährlicher als Meltdown, in anderer Hinsicht ist es weniger. Im Gegensatz zu Meltdown kann Foreshadow aufgrund der Besonderheiten der Intel-Implementierung seiner Prozessorarchitektur nur den Inhalt des L1-Caches lesen. Foreshadow kann jedoch alle Inhalte in L1 lesen – nicht nur Daten, die vom Programm adressiert werden können.
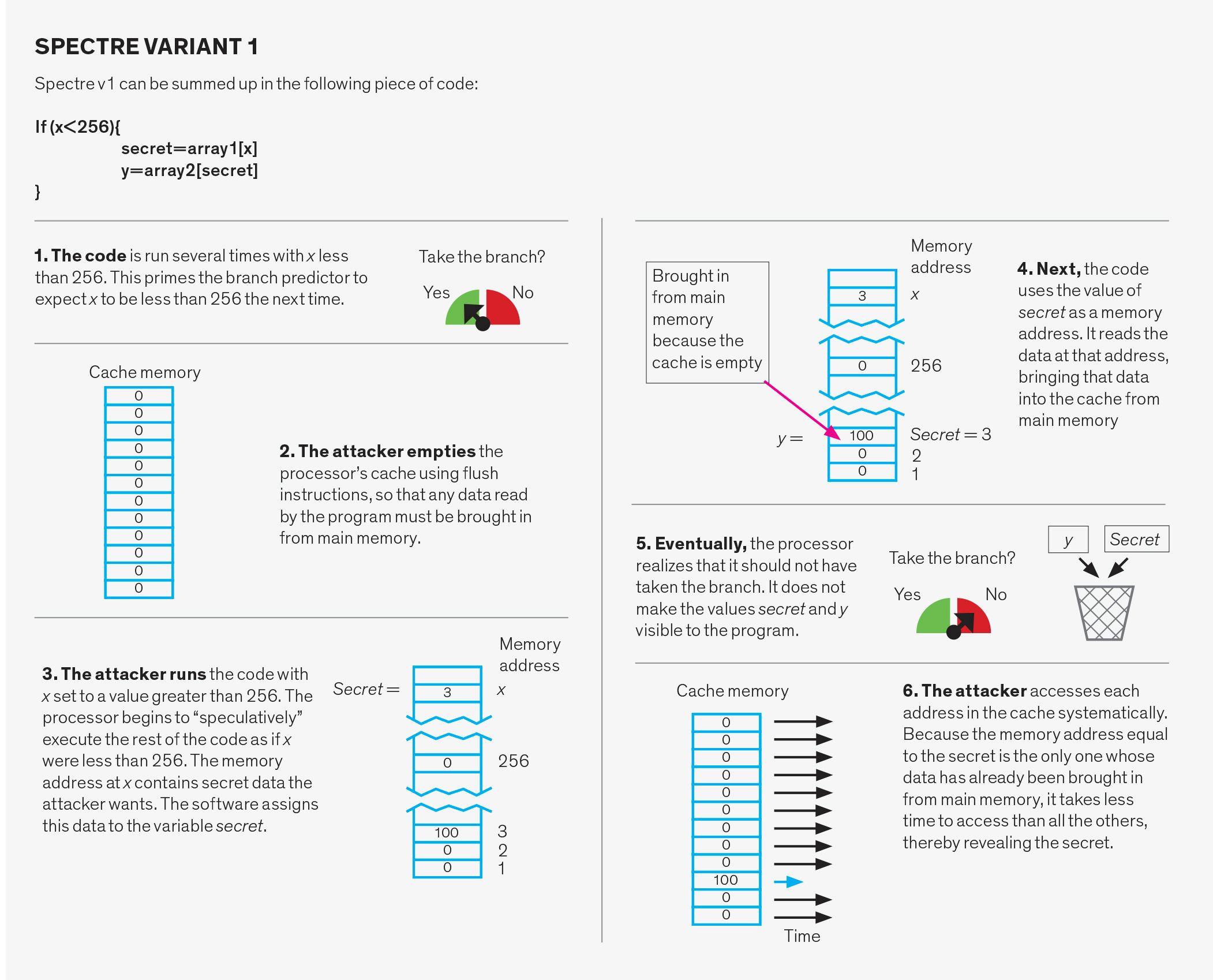
Spectre-Angriffe
Spectre-Angriffe manipulieren das Branch-Prediction-System. Dieses System besteht aus drei Teilen: dem Verzweigungsrichtungsprädiktor, dem Verzweigungszielprädiktor und dem Rückgabestapelpuffer.
Der Verzweigungsrichtungsprädiktor sagt voraus, ob eine bedingte Verzweigung, wie sie zum Implementieren einer „if“ -Anweisung in einer Programmiersprache verwendet wird, genommen oder nicht genommen wird. Dazu verfolgt es das vorherige Verhalten ähnlicher Zweige. Zum Beispiel kann es bedeuten, dass, wenn ein Zweig zweimal hintereinander genommen wird, zukünftige Vorhersagen sagen, dass es genommen werden sollte.
Der Branch-Target-Prädiktor prognostiziert die Zielspeicheradresse von sogenannten indirekten Branches. In einem bedingten Zweig wird die Adresse des nächsten Befehls angegeben, aber für einen indirekten Zweig muss diese Adresse zuerst berechnet werden. Das System, das diese Ergebnisse vorhersagt, ist eine Cache-Struktur, die als Branch-Target-Puffer bezeichnet wird. Im Wesentlichen verfolgt es das zuletzt berechnete Ziel der indirekten Zweige und verwendet diese, um vorherzusagen, wohin der nächste indirekte Zweig führen soll.
Der Return-Stack-Puffer wird verwendet, um das Ziel einer „return“ -Anweisung vorherzusagen. Wenn eine Unterroutine während eines Programms „aufgerufen“ wird, führt die return-Anweisung dazu, dass das Programm an dem Punkt, von dem aus die Unterroutine aufgerufen wurde, seine Arbeit wieder aufnimmt. Der Versuch, den richtigen Punkt für die Rückkehr nur anhand früherer Absenderadressen vorherzusagen, funktioniert nicht, da dieselbe Funktion möglicherweise von vielen verschiedenen Stellen im Code aus aufgerufen wird. Stattdessen verwendet das System den Return-Stack-Puffer, einen Speicher auf dem Prozessor, der die Rücksprungadressen von Funktionen beim Aufruf beibehält. Diese Adressen werden dann verwendet, wenn im Code des Unterprogramms eine Rückgabe auftritt.
Jede dieser drei Strukturen kann auf zwei verschiedene Arten ausgenutzt werden. Erstens kann der Prädiktor absichtlich missverstanden werden. In diesem Fall führt der Angreifer scheinbar unschuldigen Code aus, der das System verwirren soll. Später führt der Angreifer absichtlich einen Zweig aus, der falsch spekuliert, wodurch das Programm zu einem vom Angreifer ausgewählten Code springt, der als Gadget bezeichnet wird. Das Gadget macht sich dann daran, Daten zu stehlen.
Eine zweite Art des Spectre-Angriffs wird als Direkteinspritzung bezeichnet. Es stellt sich heraus, dass unter bestimmten Bedingungen die drei Prädiktoren von verschiedenen Programmen gemeinsam genutzt werden. Dies bedeutet, dass das angreifende Programm die Prädiktorstrukturen bei der Ausführung mit sorgfältig ausgewählten fehlerhaften Daten füllen kann. Wenn ein unwissentliches Opfer sein Programm entweder zur gleichen Zeit wie der Angreifer oder danach ausführt, verwendet das Opfer den Prädiktorstatus, der vom Angreifer ausgefüllt wurde, und löst unwissentlich ein Gadget aus. Dieser zweite Angriff ist besonders besorgniserregend, da er es ermöglicht, ein Opferprogramm von einem anderen Programm aus anzugreifen. Eine solche Bedrohung ist besonders schädlich für Cloud-Service-Provider, da sie dann nicht garantieren können, dass ihre Kundendaten geschützt sind.
Die Sicherheitslücken Spectre und Meltdown stellten die Computerindustrie vor ein Rätsel, da die Sicherheitsanfälligkeit ihren Ursprung in der Hardware hat. In einigen Fällen können wir für bestehende Systeme — die den Großteil der installierten Server und PCs ausmachen — am besten versuchen, Software neu zu schreiben, um den Schaden zu begrenzen. Diese Lösungen sind jedoch ad hoc, unvollständig und führen häufig zu einem großen Einfluss auf die Computerleistung. Gleichzeitig haben Forscher und CPU-Designer darüber nachgedacht, wie sie zukünftige CPUs entwerfen können, die die Spekulation aufrechterhalten, ohne die Sicherheit zu beeinträchtigen.
Eine Verteidigung namens Kernel Page-Table Isolation (KPTI) ist jetzt in Linux und anderen Betriebssystemen integriert. Denken Sie daran, dass jede Anwendung den Arbeitsspeicher und die Speicherressourcen des Computers als einen einzigen zusammenhängenden Abschnitt des virtuellen Speichers ansieht. Physisch werden diese Assets jedoch auf verschiedene Programme und Prozesse aufgeteilt und gemeinsam genutzt. Die Seitentabelle ist im Wesentlichen die Karte des Betriebssystems, die angibt, welche Teile einer virtuellen Speicheradresse welchen physischen Speicheradressen entsprechen. Die Kernel-Seitentabelle ist dafür verantwortlich, dies für den Kern des Betriebssystems zu tun. KPTI und ähnliche Systeme verteidigen sich gegen Meltdown, indem sie geheime Daten im Speicher, wie das Betriebssystem, unzugänglich machen, wenn das Programm eines Benutzers (und möglicherweise das Programm eines Angreifers) ausgeführt wird. Dies geschieht, indem die verbotenen Teile aus der Seitentabelle entfernt werden. Auf diese Weise kann selbst spekulativ ausgeführter Code nicht auf die Daten zugreifen. Diese Lösung bedeutet jedoch zusätzlichen Aufwand für das Betriebssystem, um diese Seiten bei der Ausführung zuzuordnen und die Zuordnung danach aufzuheben.
Eine weitere Klasse von Schutzmechanismen gibt Programmierern eine Reihe von Werkzeugen, um gefährliche Spekulationen zu begrenzen. Zum Beispiel schreibt der Retpoline-Patch von Google die Art von Zweigen neu, die für Spectre Variant 2 anfällig sind, sodass Spekulationen auf ein gutartiges, leeres Gadget abzielen. Programmierer können auch eine Anweisung in Assemblersprache hinzufügen, die Spectre v1 einschränkt, indem spekulative Speicherlesevorgänge eingeschränkt werden, die bedingten Verzweigungen folgen. Zweckmäßigerweise ist diese Anweisung bereits in der Prozessorarchitektur vorhanden und wird verwendet, um die korrekte Reihenfolge zwischen Speicheroperationen zu erzwingen, die von verschiedenen Prozessorkernen ausgehen.
Als Prozessordesigner mussten Intel und AMD tiefer gehen als ein normaler Software-Patch. Ihre Korrekturen aktualisieren den Mikrocode des Prozessors. Mikrocode ist eine Schicht von Anweisungen, die zwischen der Assemblersprache der regulären Software und der tatsächlichen Schaltung des Prozessors passt. Mikrocode erhöht die Flexibilität des Befehlssatzes, den ein Prozessor ausführen kann. Es macht es auch einfacher, eine CPU zu entwerfen, da bei Verwendung von Mikrocode komplexe Anweisungen in mehrere einfachere Anweisungen übersetzt werden, die in einer Pipeline einfacher auszuführen sind.
Grundsätzlich haben Intel und AMD ihren Mikrocode angepasst, um das Verhalten einiger Anweisungen in Assemblersprache so zu ändern, dass Spekulationen eingeschränkt werden. Zum Beispiel haben Intel-Ingenieure Optionen hinzugefügt, die einige der Angriffe stören, indem sie es dem Betriebssystem ermöglichen, die Verzweigungsprädiktorstrukturen unter bestimmten Umständen zu leeren.
Eine andere Klasse von Lösungen versucht, die Fähigkeit des Angreifers zu stören, die Daten über Seitenkanäle zu übertragen. Zum Beispiel teilt die DAWG-Technologie des MIT den Prozessor-Cache sicher auf, so dass verschiedene Programme keine ihrer Ressourcen gemeinsam nutzen. Am ehrgeizigsten sind Vorschläge für neue Prozessorarchitekturen, die Strukturen auf der CPU einführen würden, die der Spekulation gewidmet und vom Cache des Prozessors und anderer Hardware getrennt sind. Auf diese Weise sind alle Operationen, die spekulativ ausgeführt, aber nicht endgültig festgeschrieben werden, niemals sichtbar. Wenn das Spekulationsergebnis bestätigt wird, werden die spekulativen Daten an die Hauptstrukturen des Prozessors gesendet.
Diese Sicherheitslücken schlummern seit über 20 Jahren in Prozessoren und blieben, soweit bekannt, ungenutzt. Ihre Entdeckung hat die Industrie erheblich erschüttert und gezeigt, dass Cybersicherheit nicht nur ein Problem für Softwaresysteme, sondern auch für Hardware ist. Seit der ersten Entdeckung wurden rund ein Dutzend Varianten von Spectre und Meltdown enthüllt, und es ist wahrscheinlich, dass es noch mehr gibt. Spectre und Meltdown sind schließlich Nebenwirkungen von Kerndesignprinzipien, auf die wir uns verlassen haben, um die Computerleistung zu verbessern, was es schwierig macht, solche Schwachstellen in aktuellen Systemdesigns zu beseitigen. Es ist wahrscheinlich, dass sich neue CPU-Designs weiterentwickeln werden, um Spekulationen beizubehalten und gleichzeitig die Art von Seitenkanallecks zu verhindern, die diese Angriffe ermöglichen. Dennoch müssen zukünftige Computersystemdesigner, einschließlich derjenigen, die Prozessorchips entwerfen, sich der Sicherheitsauswirkungen ihrer Entscheidungen bewusst sein und nicht mehr nur auf Leistung, Größe und Leistung optimieren.
Über den Autor
Nael Abu-Ghazaleh ist Vorsitzender des Computer Engineering Program an der University of California, Riverside. Dmitry Evtyushkin ist Assistenzprofessor für Informatik am College of William and Mary in Williamsburg, Virginia. Dmitry Ponomarev ist Professor für Informatik an der State University of New York in Binghamton.
Um weiter zu untersuchen
Paul Kocher und die anderen Forscher, die gemeinsam Spectre enthüllten, erklärten es zuerst hier . Moritz Lipp erklärte Meltdown in diesem Vortrag auf der Usenix Security ’18. Foreshadow wurde auf derselben Konferenz ausführlich beschrieben.
Eine Gruppe von Forschern, darunter einer der Autoren, hat eine systematische Auswertung von Spectre- und Meltdown-Angriffen erstellt, die zusätzliche potenzielle Angriffe aufdeckt . IBM-Ingenieure haben etwas Ähnliches getan, und Google-Ingenieure kamen kürzlich zu dem Schluss, dass Seitenkanal- und spekulative Ausführungsangriffe bleiben werden .