datový sklad je elektronický systém, který shromažďuje data z široké škály zdrojů v rámci společnosti a používá data pro podporu řízení rozhodování.
společnosti se stále více pohybují směrem k cloudovým datovým skladům namísto tradičních on-premise systémů. Cloudové datové sklady se liší od tradičních skladů následujícími způsoby:
- není třeba kupovat fyzický hardware.
- nastavení a škálování cloudových datových skladů je rychlejší a levnější.
- cloudové architektury datových skladů mohou obvykle provádět složité analytické dotazy mnohem rychleji, protože používají masivně paralelní zpracování (MPP).
zbytek tohoto článku vztahuje na tradiční datového skladu, architektura a zavádí některé architektonické nápady a koncepty používají nejvíce populární cloud-based data warehouse služby.
další podrobnosti naleznete na naší stránce o konceptech datového skladu v této příručce.
tradiční architektura datového skladu
následující pojmy zdůrazňují některé zavedené myšlenky a principy návrhu používané pro budování tradičních datových skladů.
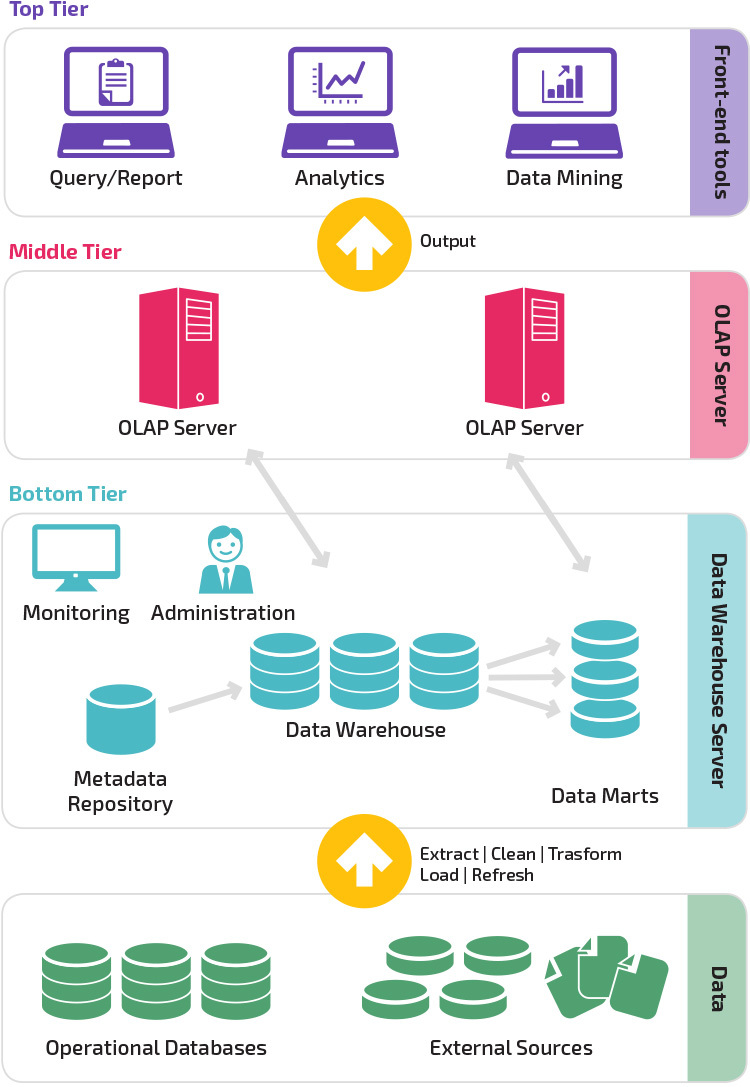
třístupňová Architektura
tradiční architektura datového skladu využívá třístupňovou strukturu složenou z následujících úrovní.
- Spodní vrstva: Tato vrstva obsahuje databázový server používá k extrakci dat z mnoha různých zdrojů, například z transakčních databází pro front-end aplikací.
- Střední Vrstva: Ve střední vrstvě je umístěn server OLAP, který transformuje data do struktury vhodnější pro analýzu a komplexní dotazování. OLAP server může pracovat dvěma způsoby: buď jako rozšířená relační databáze řízení systému, který mapuje operace na multidimenzionálních dat standardní relační operace (Relační OLAP), nebo pomocí multidimenzionální OLAP model, který přímo implementuje multidimensional dat a operací.
- horní vrstva: horní vrstva je klientská vrstva. Tato úroveň obsahuje nástroje používané pro analýzu dat na vysoké úrovni, dotazování reporting, a dolování dat.
Kimball vs. Inmon
Dva průkopníci data warehousingu Bill Inmon a Ralph Kimball měl různé přístupy k návrhu datového skladu.
přístup Ralpha Kimballa zdůraznil význam datových tržišť, což jsou úložiště dat patřících do konkrétních oblastí podnikání. Datový sklad je jednoduše kombinací různých datových tržišť, které usnadňují reporting a analýzu. Návrh datového skladu Kimball používá přístup“ zdola nahoru“.
Bill Inmon považoval datový sklad za centralizované úložiště pro všechna podniková data. V tomto přístupu organizace nejprve vytvoří normalizovaný model datového skladu. Dimenzionální datové tržiště jsou pak vytvořeny na základě modelu skladu. Toto je známé jako přístup shora dolů k ukládání dat.
modely datového skladu
v tradiční architektuře existují tři běžné modely datového skladu: virtuální sklad, datový obchod a podnikový datový sklad:
- virtuální datový sklad je sada samostatných databází, které mohou být dotazovány společně, takže uživatel může účinně přístup všechna data, jako kdyby byla uložena v jednom datovém skladu.
- datový mart model se používá pro Business-line specifické reporting a analýzy. V tomto modelu datového skladu jsou data agregována z řady zdrojových systémů relevantních pro konkrétní oblast podnikání, jako je prodej nebo finance.
- model podnikového datového skladu předepisuje, že datový sklad obsahuje agregovaná data, která pokrývají celou organizaci. Tento model vidí datový sklad jako srdce podnikového informačního systému s integrovanými daty ze všech obchodních jednotek.
Star Schema vs. Snowflake Schema
star schema a snowflake schema jsou dva způsoby, jak strukturovat datový sklad.
hvězdné schéma má centralizované úložiště dat uložené v tabulce faktů. Schéma rozděluje tabulku faktů do řady denormalizovaných kótovacích tabulek. Tabulka faktů obsahuje agregovaná data, která mají být použita pro účely podávání zpráv, zatímco dimenze popisuje uložená data.
Denormalizované návrhy jsou méně složité, protože data jsou seskupena. Tabulka faktů používá k připojení ke každé tabulce dimenzí pouze jeden odkaz. Jednodušší design hvězdného schématu usnadňuje psaní složitých dotazů.
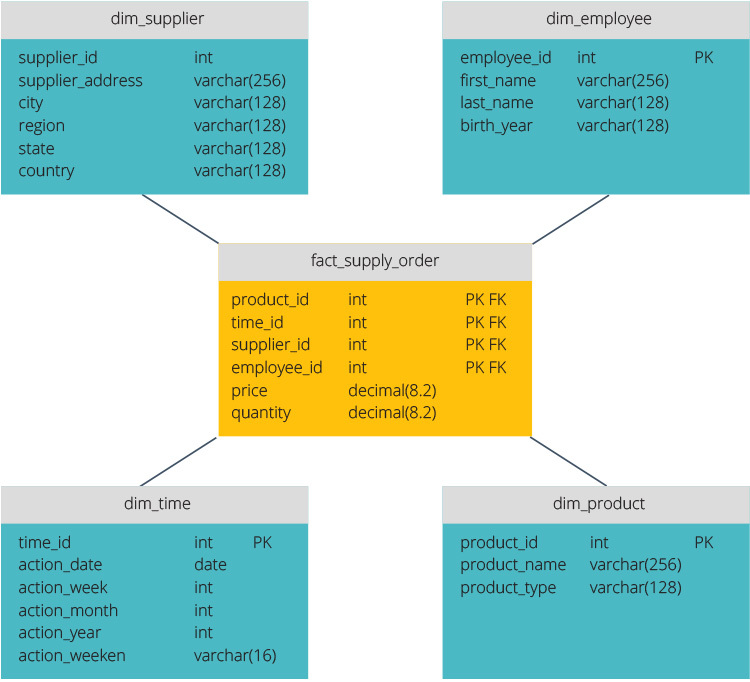
schéma sněhové vločky je jiné, protože normalizuje data. Normalizace znamená efektivní uspořádání dat tak, aby byly definovány všechny závislosti dat a každá tabulka obsahuje minimální propouštění. Jednorozměrné tabulky se tak rozvětvují do samostatných rozměrových tabulek.
schéma sněhové vločky využívá méně místa na disku a lépe zachovává integritu dat. Hlavní nevýhodou je složitost dotazů požadované pro přístup k datům—každý dotaz musí sáhnout hluboko do příslušného data, protože tam jsou více připojí.
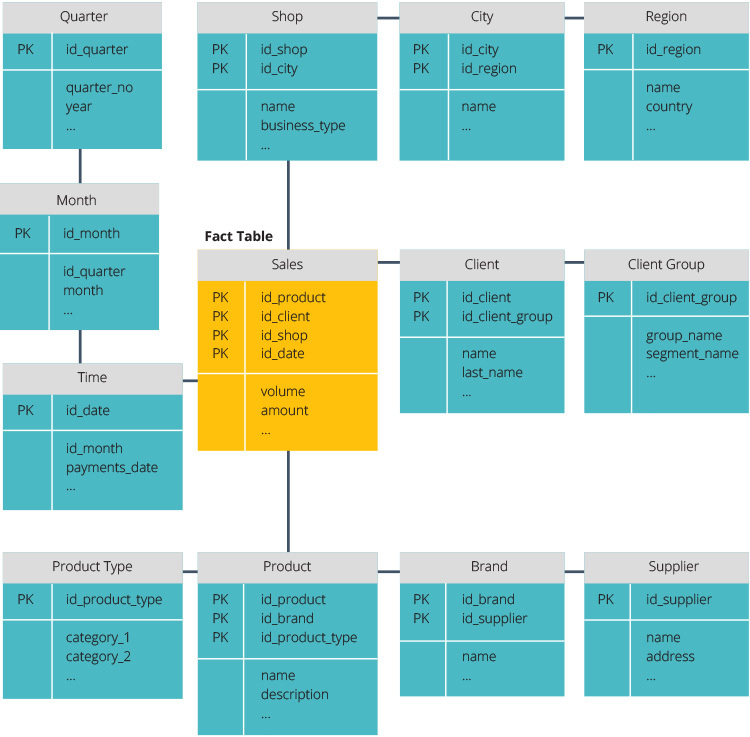
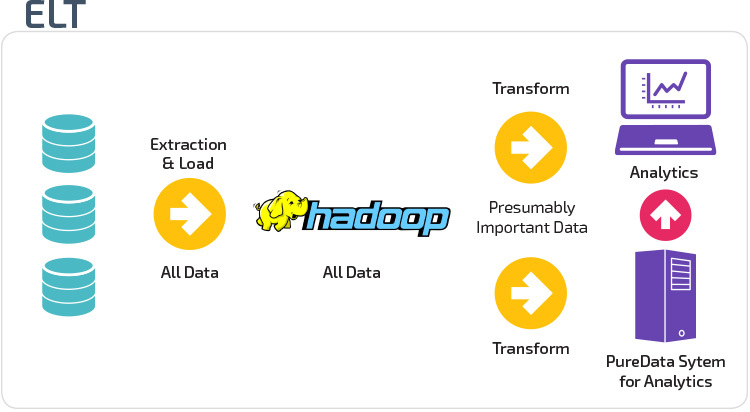
ETL vs ELT
ETL a ELT jsou dva různé způsoby načítání dat do skladu.
Extract, Transform, Load (ETL) nejprve extrahuje data z fondu datových zdrojů, které jsou typicky transakční databáze. Data jsou uchovávána v dočasné pracovní databázi. Poté jsou prováděny transformační operace, které strukturují a převádějí data do vhodné formy pro systém cílového datového skladu. Strukturovaná data jsou poté načtena do skladu a připravena k analýze.
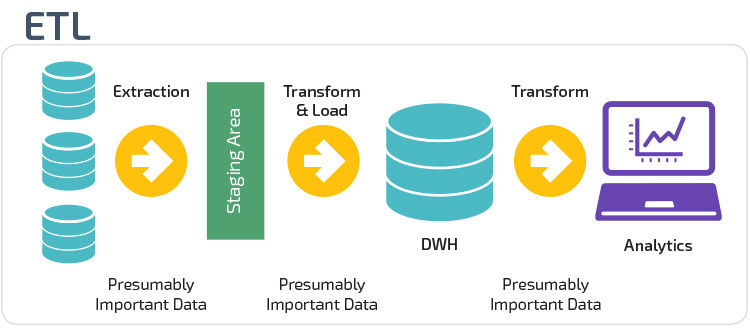
s Extract Load Transform (ELT) jsou data okamžitě načtena Po extrahování ze zdrojových datových fondů. Neexistuje žádná stagingová databáze, což znamená, že data jsou okamžitě načtena do jediného centralizovaného úložiště. Data jsou transformována v systému datového skladu pro použití s nástroji business intelligence a analytics.
organizační zralost
struktura datového skladu organizace závisí také na její aktuální situaci a potřebách.
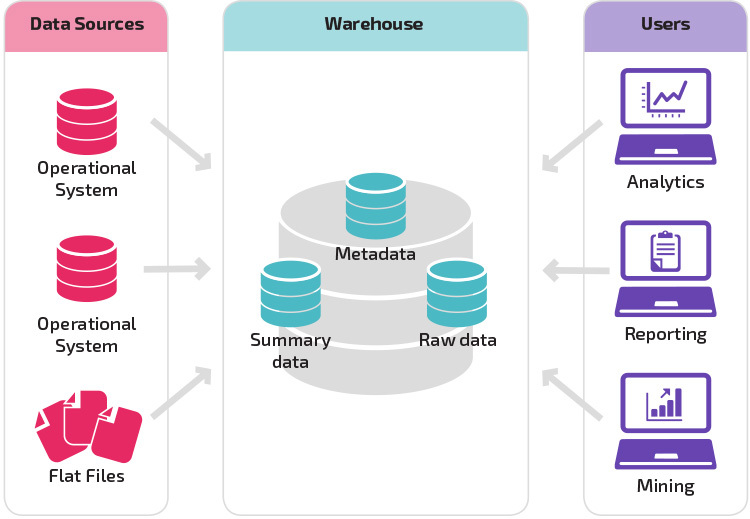
základní struktura umožňuje koncovým uživatelům skladu přímo přístup shrnutí dat získaných ze zdrojových systémů a provést analýzu, podávání zpráv, a mining na údaje. Tato struktura je užitečná, když zdroje dat pocházejí ze stejných typů databázových systémů.
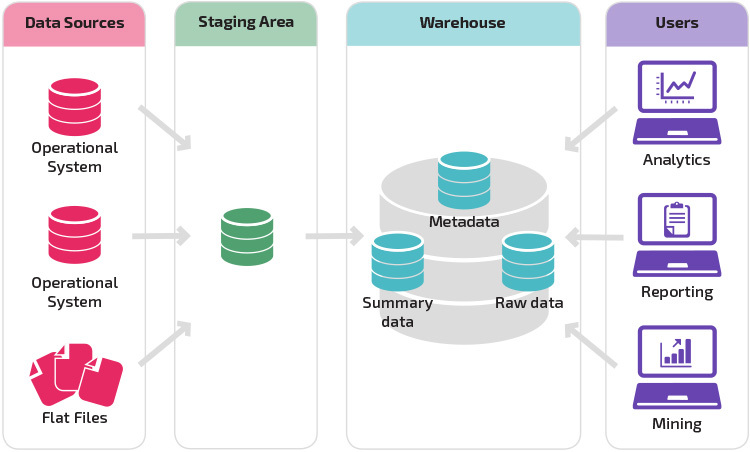
sklad s pracovní oblasti je další logický krok v organizaci různorodých datových zdrojů s mnoha různými typy a formáty dat. Pracovní oblast převádí data do souhrnného strukturovaného formátu, který lze snadněji dotazovat pomocí nástrojů pro analýzu a podávání zpráv.
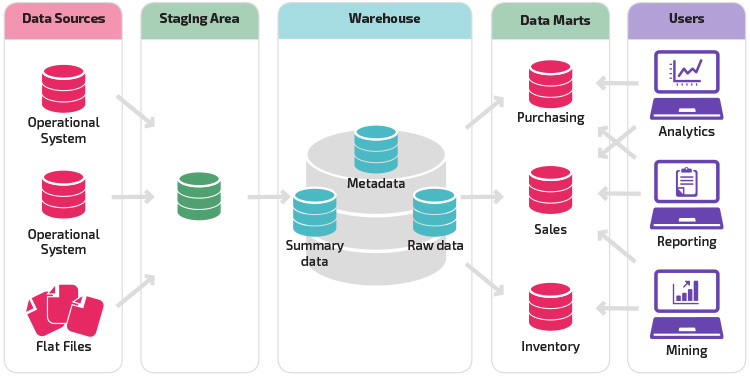
variace na fázové struktury je přidání datových tržišť do datového skladu. Data marts obchod shrnuty údaje pro konkrétní linii podnikání, která data snadno přístupné pro specifické formy analýzy. Například přidání datových tržišť může finančnímu analytikovi umožnit snadnější provádění podrobných dotazů na údaje o prodeji a předpovídání chování zákazníků. Datové tržiště usnadňují analýzu přizpůsobením dat specificky tak, aby vyhovovaly potřebám koncového uživatele.
nové architektury datového skladu
v posledních letech se datové sklady přesouvají do cloudu. Nové cloudové datové sklady nedodržují tradiční architekturu; každá nabídka datového skladu má jedinečnou architekturu.
tato část shrnuje architektury používané dvěma nejoblíbenějšími cloudovými sklady: Amazon Redshift a Google BigQuery.
Amazon Redshift
Amazon Redshift je cloudová reprezentace tradičního datového skladu.
Redshift vyžaduje, aby výpočetní prostředky byly zřízeny a nastaveny ve formě klastrů, které obsahují sbírku jednoho nebo více uzlů. Každý uzel má svůj vlastní procesor, úložiště a RAM. Vedoucí uzel sestavuje dotazy a přenáší je do výpočetních uzlů, které provádějí dotazy.
na každém uzlu jsou data uložena v kusech nazývaných řezy. Redshift používá sloupcové úložiště, což znamená, že každý blok dat obsahuje hodnoty z jednoho sloupce v několika řádcích, místo jednoho řádku s hodnotami z více sloupců.
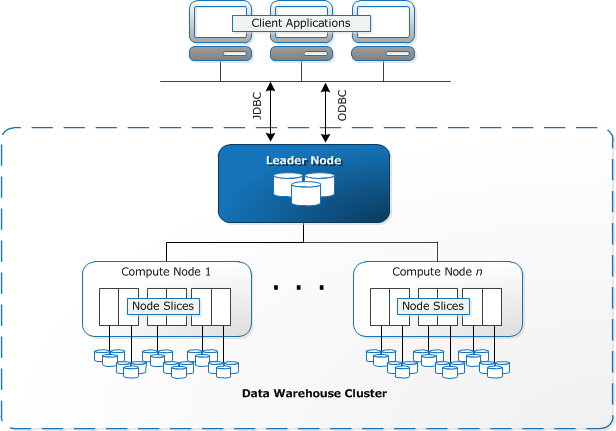
Zdroj: AWS Dokumentace
Redshift používá MPP architektury, rozbití velkých datových souborů do bloků, které jsou přiřazeny k plátky do každého uzlu. Dotazy fungují rychleji, protože výpočetní uzly zpracovávají dotazy v každém řezu současně. Uzel Leader agreguje výsledky a vrací je do klientské aplikace.
klientské aplikace, jako jsou BI a analytické nástroje, se mohou přímo připojit k Redshift pomocí Open source ovladačů PostgreSQL JDBC a ODBC. Analytici tak mohou plnit své úkoly přímo na datech Redshift.
Redshift může načíst pouze strukturovaná data. Je možné načíst data do Redshift pomocí předintegrovaných systémů, včetně Amazon S3 a DynamoDB, tlačením dat z libovolného hostitele na místě s připojením SSH nebo integrací jiných zdrojů dat pomocí rozhraní Redshift API.
Google BigQuery
Architektura BigQuery je bez serverů, což znamená, že Google dynamicky řídí alokaci strojových zdrojů. Všechna rozhodnutí o správě zdrojů jsou proto před uživatelem skryta.
BigQuery umožňuje klientům načíst data z úložiště Google Cloud a dalších čitelných zdrojů dat. Alternativní možností je streamovat data, což vývojářům umožňuje přidávat data do datového skladu v reálném čase, řádek po řádku, jakmile bude k dispozici.
BigQuery používá engine pro provádění dotazů s názvem Dremel, který dokáže skenovat miliardy řádků dat během několika sekund. Dremel používá masivně paralelní dotazování ke skenování dat v základním systému správy souborů Colossus. Colossus distribuuje soubory do bloků 64 megabajtů mezi mnoha výpočetními prostředky pojmenovanými uzly, které jsou seskupeny do klastrů.
Dremel používá sloupcovou datovou strukturu podobnou Redshift. Stromová Architektura odesílá dotazy mezi tisíci strojů během několika sekund.
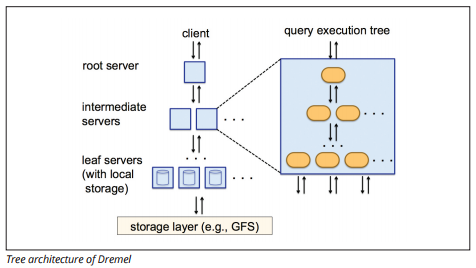
Zdroj obrázku
jednoduché příkazy SQL se používají k provádění dotazů na data.
Paletě
Paletu poskytuje end-to-end pro správu dat-as-a-service. Jeho unikátní self-optimalizace architektury využívá strojové učení a zpracování přirozeného jazyka (NLP) na modelu a zjednodušení datové cesty od zdroje k analýze, snížení času z údajů na hodnoty co nejblíže k žádné.
inteligentní datová infrastruktura Panoply zahrnuje následující funkce:
- Analýze dotazů a dat – identifikace nejlepší konfigurace pro každý případ použití, nastavení v průběhu času, a budovy indexy, sortkeys, diskeys, datové typy, vysávání a oddělování.
- Identifikovat dotazy, které nemají dodržovat osvědčené postupy, jako jsou ty, které obsahují vnořené smyčky nebo implicitní obsazení – a přepisuje je na ekvivalentní dotaz vyžadující zlomek runtime nebo zdroje.
- optimalizace konfigurace serveru v průběhu času na základě vzorů dotazů a učení, které nastavení serveru funguje nejlépe. Platforma plynule přepíná typy serverů a měří výsledný výkon.
kromě cloudových datových skladů
cloudové datové sklady jsou velkým krokem vpřed od tradičních architektur. Nicméně, uživatelé stále čelí několika výzvám při jejich nastavení:
- Načítání dat do cloudu, datových skladů je non-triviální, a pro rozsáhlé datové potrubí, to vyžaduje nastavení, testování a udržování ETL procesu. Tato část procesu se obvykle provádí pomocí nástrojů třetích stran.
- aktualizace, upserts, a odstranění může být složité a musí být provedeno opatrně, aby se zabránilo degradaci ve výkonu dotazu.
- Polostrukturovaná data je obtížné řešit-je třeba normalizovat do relačního databázového formátu, který vyžaduje automatizaci pro velké datové toky.
- vnořené struktury obvykle nejsou podporovány v cloudových datových skladech. Budete muset vyrovnat vnořené tabulky do formátu, kterému datový sklad rozumí.
- optimalizace clusteru—existují různé možnosti nastavení clusteru Redshift pro spuštění vašeho pracovního zatížení. Různé pracovní zátěže, datové sady nebo dokonce různé typy dotazů mohou vyžadovat jiné nastavení. Chcete-li zůstat optimální, budete muset své nastavení neustále revidovat a vylepšovat.
- optimalizace dotazů – uživatelské dotazy nemusí dodržovat osvědčené postupy,a proto bude trvat mnohem déle. Můžete pracovat s uživateli nebo automatizovanými klientskými aplikacemi na optimalizaci dotazů tak, aby datový sklad mohl fungovat podle očekávání.
- zálohování a obnova – zatímco dodavatelé datového skladu poskytují řadu možností pro zálohování vašich dat, nejsou triviální nastavení a vyžadují sledování a velkou pozornost.
Paletu je Chytrý Datový Sklad, který přidává vrstvu automatizace, která se postará o všechny složité úkoly výše, což šetří drahocenný čas a pomůže vám dostat se z údajů k nahlédnutí v minutách.
další informace o nástrojích Panoply smart data warehouse.
další informace o datových skladech
- koncepty datového skladu: tradiční vs. Cloud
- Database vs. Data Warehouse
- Data Mart vs. Data Warehouse
- Amazon Redshift Architecture