et datalager er et elektronisk system, der samler data fra en lang række kilder i en virksomhed og bruger dataene til at understøtte ledelsesbeslutning.
virksomheder bevæger sig i stigende grad mod skybaserede datalagre i stedet for traditionelle on-premise systemer. Cloud-baserede datalagre adskiller sig fra traditionelle lagre på følgende måder:
- der er ikke behov for at købe fysisk udstyr.
- det er hurtigere og billigere at oprette og skalere cloud-datalagre.
- Cloud-baserede datalagerarkitekturer kan typisk udføre komplekse analytiske forespørgsler meget hurtigere, fordi de bruger massivt parallel behandling (MPP).
resten af denne artikel dækker traditionel datalagerarkitektur og introducerer nogle arkitektoniske ideer og koncepter, der bruges af de mest populære skybaserede datalagertjenester.
For flere detaljer, se vores side om datalagerkoncepter i denne vejledning.
traditionel Datalagerarkitektur
følgende begreber fremhæver nogle af de etablerede ideer og designprincipper, der anvendes til opbygning af traditionelle datalagre.
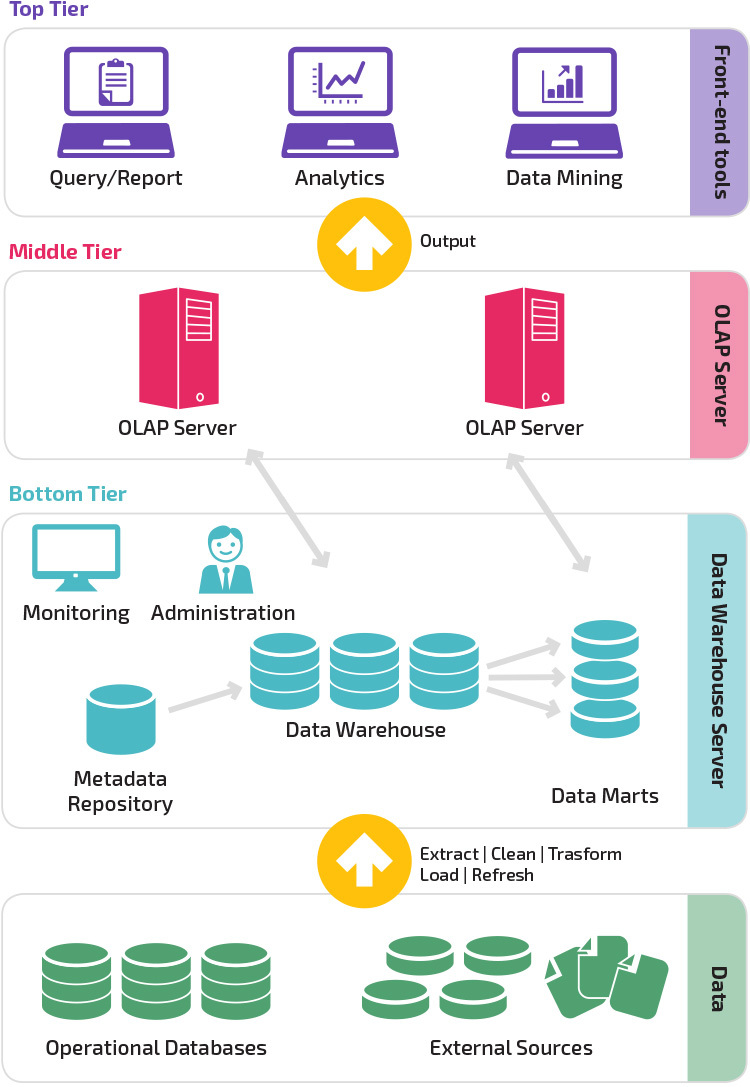
tre-lags arkitektur
traditionel datalagerarkitektur anvender en tre-lags struktur sammensat af følgende niveauer.
- nederste niveau: dette niveau indeholder den databaseserver, der bruges til at udtrække data fra mange forskellige kilder, f.eks.
- mellemste niveau: Det midterste niveau huser en OLAP-server, der omdanner dataene til en struktur, der er bedre egnet til analyse og kompleks forespørgsel. OLAP-serveren kan fungere på to måder: enten som et udvidet relationsdatabasestyringssystem, der kortlægger operationerne på multidimensionelle data til standard relationelle operationer (relationelle OLAP) eller ved hjælp af en multidimensionel OLAP-model, der direkte implementerer de multidimensionelle data og operationer.
- øverste niveau: det øverste niveau er klientlaget. Dette niveau indeholder de værktøjer, der bruges til dataanalyse på højt niveau, forespørgsel rapportering, og data mining.
Kimball vs. Inmon
to pionerer inden for datalagring ved navn Bill Inmon og Ralph Kimball havde forskellige tilgange til datalagerdesign.
Ralph Kimballs tilgang understregede vigtigheden af datamarts, som er lagre af data, der tilhører bestemte forretningsområder. Datalageret er simpelthen en kombination af forskellige datamarts, der letter rapportering og analyse. Kimball data lager design bruger en” bottom-up ” tilgang.
Bill Inmon betragtede datalageret som det centraliserede lager for alle virksomhedsdata. I denne tilgang opretter en organisation først en normaliseret datalagermodel. Dimensionelle data marts oprettes derefter baseret på lagermodellen. Dette er kendt som en top-ned tilgang til datalagring.
Datalagermodeller
i en traditionel arkitektur er der tre almindelige datalagermodeller: virtuelt lager, datamart og virksomhedsdatalager:
- et virtuelt datalager er et sæt separate databaser, som kan forespørges sammen, så en bruger effektivt kan få adgang til alle dataene, som om de var gemt i et datalager.
- en data mart-model bruges til forretningslinjespecifik rapportering og analyse. I denne datalagermodel aggregeres data fra en række kildesystemer, der er relevante for et specifikt forretningsområde, såsom salg eller finansiering.
- en virksomhedsdatalagermodel foreskriver, at datalageret indeholder aggregerede data, der spænder over hele organisationen. Denne model ser datalageret som hjertet i virksomhedens informationssystem med integrerede data fra alle forretningsenheder.
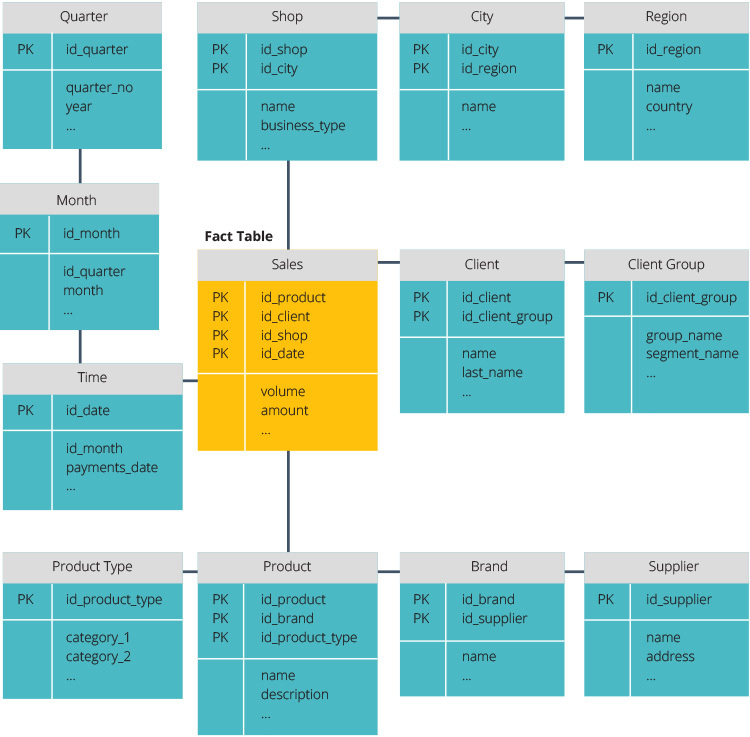
Stjerneskema vs. snefnugskema
stjerneskemaet og snefnugskemaet er to måder at strukturere et datalager på.
stjerneskemaet har et centraliseret datalager, gemt i en faktatabel. Skemaet opdeler faktatabellen i en række denormaliserede dimensionstabeller. Faktatabellen indeholder aggregerede data, der skal bruges til rapporteringsformål, mens dimensionstabellen beskriver de lagrede data.
denormaliserede designs er mindre komplekse, fordi dataene er grupperet. Faktatabellen bruger kun et link til at deltage i hver dimensionstabel. Stjerneskemaets enklere design gør det meget lettere at skrive komplekse forespørgsler.
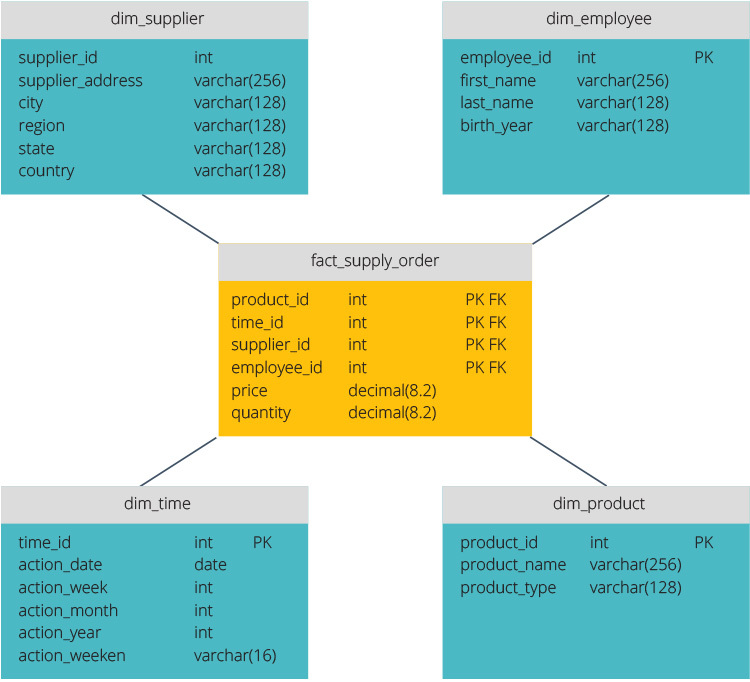
snefnugskemaet er anderledes, fordi det normaliserer dataene. Normalisering betyder effektiv organisering af dataene, så alle dataafhængigheder defineres, og hver tabel indeholder minimale afskedigelser. Tabeller med en enkelt dimension forgrener sig således i separate dimensionstabeller.
snefnugskemaet bruger mindre diskplads og bevarer dataintegriteten bedre. Den største ulempe er kompleksiteten af forespørgsler, der kræves for at få adgang til data—hver forespørgsel skal grave dybt for at komme til de relevante data, fordi der er flere joinforbindelser.
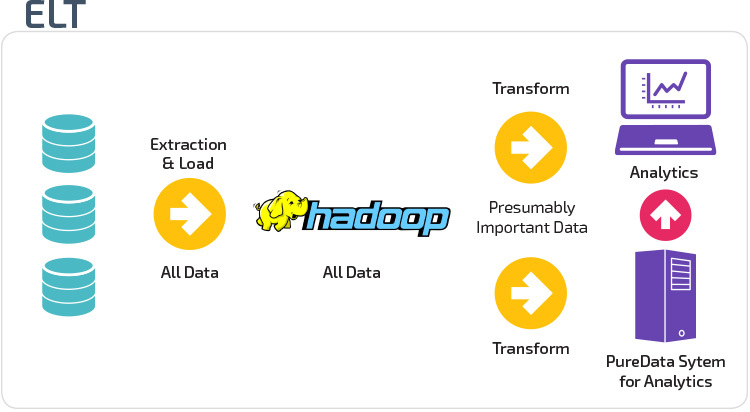
ETL vs. ELT
ETL og ELT er to forskellige metoder til indlæsning af data i et lager.
Uddrag, Transform, Load (ETL) udtrækker først dataene fra en pulje af datakilder, som typisk er transaktionsdatabaser. Dataene opbevares i en midlertidig iscenesættelsesdatabase. Transformationsoperationer udføres derefter for at strukturere og konvertere dataene til en passende form til måldatalagersystemet. De strukturerede data indlæses derefter i lageret, klar til analyse.
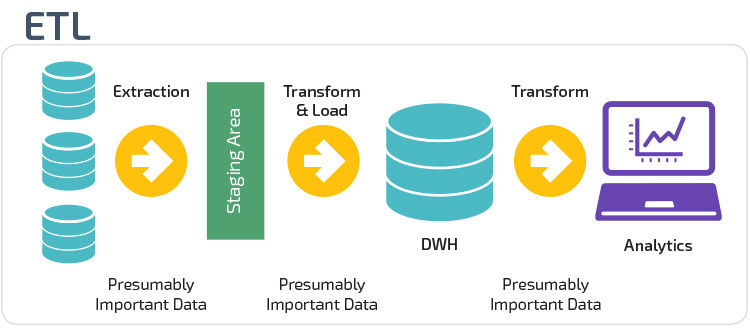
med ekstrakt Load Transform (ELT) indlæses data straks efter at være ekstraheret fra kildedatapoolerne. Der er ingen iscenesættelsesdatabase, hvilket betyder, at dataene straks indlæses i det enkelte, centraliserede lager. Dataene transformeres inde i datalagersystemet til brug med business intelligence-værktøjer og analyser.
organisatorisk modenhed
strukturen i en organisations datalager afhænger også af dens nuværende situation og behov.
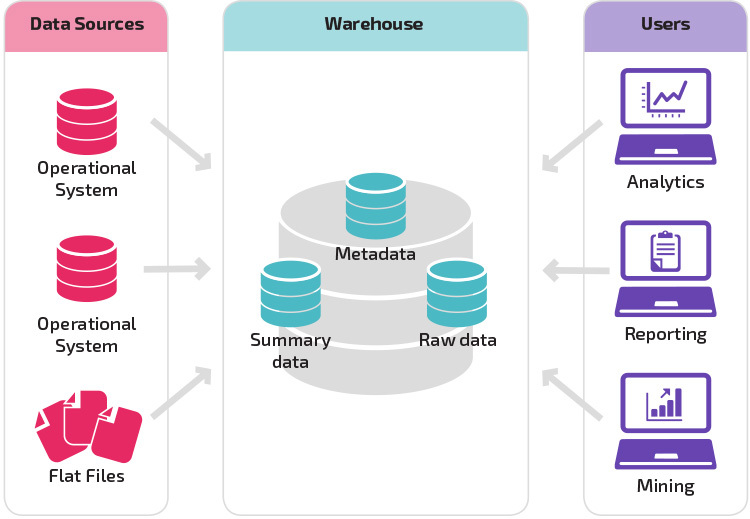
den grundlæggende struktur giver slutbrugere af lageret direkte adgang til oversigtsdata afledt af kildesystemer og udfører analyse, rapportering og minedrift på disse data. Denne struktur er nyttig, når datakilder stammer fra de samme typer databasesystemer.
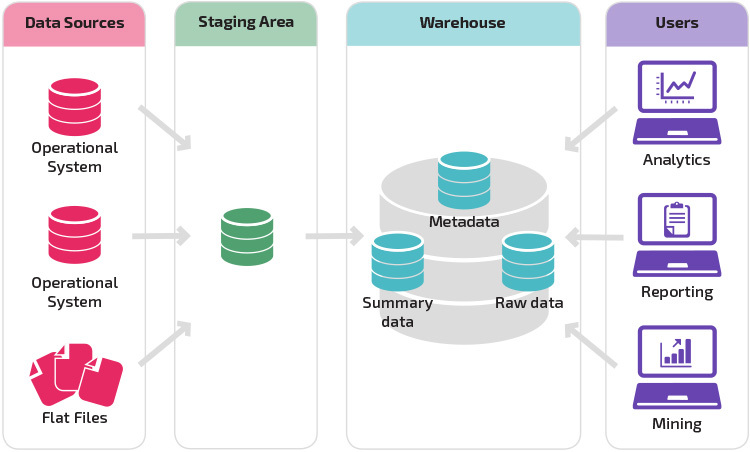
et lager med et iscenesættelsesområde er det næste logiske trin i en organisation med forskellige datakilder med mange forskellige typer og formater af data. Iscenesættelsesområdet konverterer dataene til et opsummeret struktureret format, der er lettere at forespørge med analyse-og rapporteringsværktøjer.
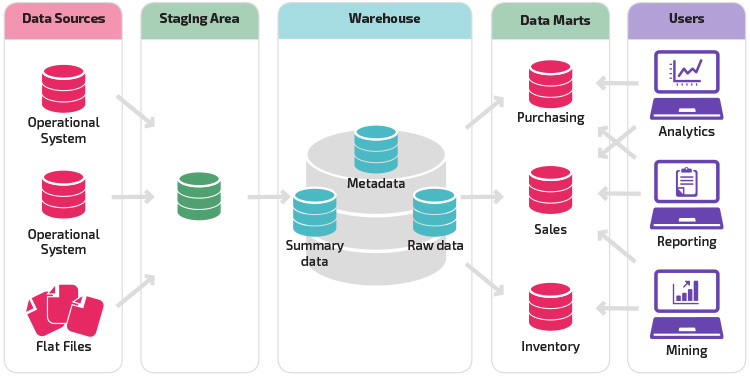
en variation på iscenesættelsesstrukturen er tilføjelsen af datamarts til datalageret. Data marts gemmer opsummerede data for en bestemt branche, hvilket gør disse data let tilgængelige til specifikke analyseformer. For eksempel kan tilføjelse af datamarts give en finansanalytiker lettere mulighed for at udføre detaljerede forespørgsler om salgsdata for at forudsige kundeadfærd. Data marts gør analysen lettere ved at skræddersy data specifikt til at imødekomme slutbrugerens behov.
nye Datalagerarkitekturer
i de senere år flytter datalagre til skyen. De nye skybaserede datalagre overholder ikke den traditionelle arkitektur; hvert datalagerudbud har en unik arkitektur.
dette afsnit opsummerer de arkitekturer, der bruges af to af de mest populære skybaserede lagre:.
Redshift
Redshift kræver, at computerressourcer klargøres og opsættes i form af klynger, der indeholder en samling af en eller flere noder. Hver node har sin egen CPU, opbevaring og RAM. En leder node kompilerer forespørgsler og overfører dem til beregne noder, som udfører forespørgsler.
på hver node gemmes data i bidder, kaldet skiver. Redshift bruger et kolonnelager, hvilket betyder, at hver datablok indeholder værdier fra en enkelt kolonne på tværs af et antal rækker i stedet for en enkelt række med værdier fra flere kolonner.
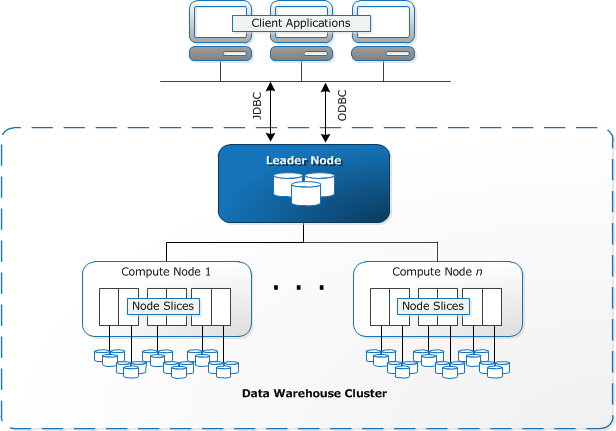
kilde: dokumentation
Redshift bruger en MPP-arkitektur, der opdeler store datasæt i bidder, der er tildelt skiver inden for hver node. Forespørgsler udføre hurtigere, fordi compute noder behandle forespørgsler i hver skive samtidigt. Leader-noden samler resultaterne og returnerer dem til klientapplikationen.
klientapplikationer, såsom BI-og analyseværktøjer, kan direkte oprette forbindelse til Redshift ved hjælp af open source-drivere. Analytikere kan således udføre deres opgaver direkte på Redshift-dataene.
Redshift kan kun indlæse strukturerede data. Det er muligt at indlæse data til Redshift ved hjælp af præintegrerede systemer, herunder
Google Storforespørgsel
Storforsøgets arkitektur er serverløs, hvilket betyder, at Google dynamisk styrer tildelingen af maskinressourcer. Alle ressourcestyringsbeslutninger er derfor skjult for brugeren.
Storforespørgsel lader klienter indlæse data fra Google Cloud Storage og andre læsbare datakilder. Den alternative mulighed er at streame data, som giver udviklere mulighed for at tilføje data til datalageret i realtid, række for række, når de bliver tilgængelige.
Storforespørgsel bruger en forespørgselsudførelsesmotor ved navn Dremel, som kan scanne milliarder af rækker med data på få sekunder. Dremel bruger massivt parallel forespørgsel til at scanne data i det underliggende Colossus file management system. Colossus distribuerer filer i bidder på 64 megabyte blandt mange computerressourcer navngivne noder, som er grupperet i klynger.
Dremel bruger en kolonneformet datastruktur, der ligner Redshift. En træarkitektur sender forespørgsler blandt tusinder af maskiner på få sekunder.
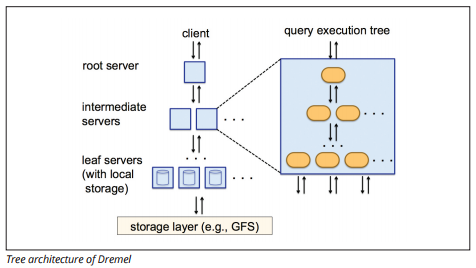
Billedkilde
Simple kommandoer bruges til at udføre forespørgsler på data.
Panoply
Panoply leverer end-to-end data management-as-a-service. Dens unikke selvoptimerende arkitektur bruger machine learning og natural language processing (NLP) til at modellere og strømline datarejsen fra kilde til analyse, hvilket reducerer tiden fra data til værdi så tæt som muligt på ingen.
Panoplys smarte datainfrastruktur indeholder følgende funktioner:
- analyse af forespørgsler og data – identificere den bedste konfiguration for hver brug tilfælde, justere det over tid, og bygning indekser, sortkeys, diskeys, datatyper, Støvsugning, og partitionering.
- identificering af forespørgsler, der ikke følger bedste praksis – såsom dem, der inkluderer indlejrede sløjfer eller implicit casting – og omskriver dem til en tilsvarende forespørgsel, der kræver en brøkdel af runtime eller ressourcer.
- optimering af serverkonfigurationer over tid baseret på forespørgselsmønstre og ved at lære, hvilken serveropsætning der fungerer bedst. Platformen skifter servertyper problemfrit og måler den resulterende ydelse.
Beyond Cloud Data pakhuse
Cloud-baserede datalagre er et stort skridt fremad fra traditionelle arkitekturer. Brugerne står dog stadig over for flere udfordringer, når de konfigureres:
- indlæsning af data til cloud-datalagre er ikke trivielt, og for store datarørledninger kræver det opsætning, test og vedligeholdelse af en ETL-proces. Denne del af processen udføres typisk med tredjepartsværktøjer.
- opdateringer, Opdateringer og sletninger kan være vanskelige og skal gøres omhyggeligt for at forhindre forringelse af forespørgselsydelsen.
- Semi-strukturerede data er vanskelige at håndtere – skal normaliseres til et relationelt databaseformat, som kræver automatisering til store datastrømme.
- indlejrede strukturer understøttes typisk ikke i cloud-datalagre. Du bliver nødt til at flade indlejrede tabeller i et format, som datalageret kan forstå.
- optimering af din klynge—der er forskellige muligheder for at oprette en Redshift-klynge til at køre dine arbejdsbelastninger. Forskellige arbejdsbelastninger, datasæt eller endda forskellige typer forespørgsler kan kræve en anden opsætning. For at forblive optimal skal du løbende revidere og justere din opsætning.
- Forespørgselsoptimering—brugerforespørgsler følger muligvis ikke Bedste praksis, og det vil derfor tage meget længere tid at køre. Du kan finde dig selv i at arbejde med brugere eller automatiserede klientapplikationer for at optimere forespørgsler, så datalageret kan fungere som forventet.
- Sikkerhedskopiering og gendannelse—mens datalagerleverandørerne giver adskillige muligheder for sikkerhedskopiering af dine data, er de ikke trivielle at konfigurere og kræver overvågning og nøje opmærksomhed.
Panoply er et Smart datalager, der tilføjer et lag af automatisering, der tager sig af alle de komplekse opgaver ovenfor, sparer værdifuld tid og hjælper dig med at komme fra data til indsigt på få minutter.
få mere at vide om Panoplys smarte datalagerværktøjer.
Lær mere om datalagre
- Datalagerkoncepter: traditionel vs. Cloud
- Database vs. datalager
- data Mart vs. datalager
-
rødforskydning arkitektur