et dybtgående kig på disse farlige udnyttelser af mikroprocessorens sårbarheder, og hvorfor der måske er flere af dem derude

vi er vant til at tænke på computerprocessorer som ordnede maskiner, der går fra en simpel instruktion til den næste med fuldstændig regelmæssighed. Men sandheden er, at de i årtier nu har gjort deres opgaver ude af drift og bare gætter på, hvad der skal komme næste gang. De er selvfølgelig meget gode til det. Så godt faktisk, at denne evne, kaldet spekulativ udførelse, har understøttet meget af forbedringen i computerkraft i løbet af de sidste 25 år eller deromkring. Men den 3. januar 2018 lærte verden, at dette trick, der havde gjort så meget for moderne computing, nu var en af dens største sårbarheder.
i løbet af 2017 udarbejdede forskere ved Cyberus Technology, Google Project nul, Grass University of Technology, Rambus, University of Adelaide og University of Pennsylvania samt uafhængige forskere som kryptograf Paul Kocher separat angreb, der udnyttede spekulativ udførelse. Vores egen gruppe havde opdaget den oprindelige sårbarhed bag et af disse angreb tilbage i 2016, men vi lagde ikke alle brikkerne sammen.
disse typer angreb, kaldet nedsmeltning og Spectre, var ingen almindelige bugs. På det tidspunkt, hvor det blev opdaget, kunne nedsmeltning hacke alle Intel 86-mikroprocessorer og IBM-Strømprocessorer samt nogle ARM-baserede processorer. Spectre og dens mange variationer tilføjede avancerede mikroenheder (AMD) processorer til denne liste. Med andre ord var næsten hele computerverdenen sårbar.
og fordi spekulativ udførelse stort set er bagt i processorudstyr, har det ikke været let at løse disse sårbarheder. At gøre det uden at få computerhastighederne til at male til lavt gear har gjort det endnu sværere. Faktisk, et år efter, jobbet er langt fra forbi. Sikkerhedsrettelser var nødvendige ikke kun fra processorproducenterne, men fra dem længere nede i forsyningskæden, som f.eks. De første computere, der drives af chips, der med vilje er designet til at være modstandsdygtige over for selv nogle af disse sårbarheder, ankom først for nylig.
Spectre og nedsmeltning er resultatet af forskellen mellem, hvad programmel skal gøre, og processorens mikroarkitektur—detaljerne om, hvordan det rent faktisk gør disse ting. Disse to klasser af hacks har afdækket en måde for information at lække ud gennem denne forskel. Og der er al mulig grund til at tro, at flere måder vil blive afdækket. Vi hjalp med at finde to, Branchscope og SpectreRSB , sidste år.
hvis vi skal holde tempoet i computerforbedringer i gang uden at ofre sikkerheden, bliver vi nødt til at forstå, hvordan disse sårbarheder sker. Og det starter med at forstå spøgelse og nedsmeltning.
i moderne computersystemer er programmer skrevet på menneskelige forståelige sprog som C++ samlet i monteringssprogsinstruktioner-grundlæggende operationer, som computerprocessoren kan udføre. For at fremskynde udførelsen bruger moderne processorer en tilgang kaldet pipelining. Ligesom en samlebånd er rørledningen en række trin, som hver er et trin, der er nødvendigt for at gennemføre en instruktion. Nogle typiske trin for en Intel H86-processor inkluderer dem, der bringer instruktionen fra hukommelsen og afkoder den for at forstå, hvad instruktionen betyder. Pipelining bringer dybest set parallelisme ned til niveauet for instruktionsudførelse: når en instruktion udføres ved hjælp af et trin, er den næste instruktion gratis at bruge den.
siden 1990 ‘ erne har mikroprocessorer påberåbt sig to tricks for at fremskynde rørledningsprocessen: udførelse og spekulation uden ordre. Hvis to instruktioner er uafhængige af hinanden—det vil sige, at output fra en ikke påvirker input fra en anden-kan de omarrangeres, og deres resultat vil stadig være korrekt. Det er nyttigt, fordi det giver processoren mulighed for at fortsætte med at arbejde, hvis en instruktion går i stå i rørledningen. For eksempel, hvis en instruktion kræver data, der er ude i DRAM-hovedhukommelsen snarere end i cachehukommelsen i selve CPU ‘ en, kan det tage et par hundrede urcyklusser at få disse data. I stedet for at vente kan processoren flytte en anden instruktion gennem rørledningen.
det andet trick er spekulation. For at forstå det, start med det faktum, at nogle instruktioner nødvendigvis fører til en ændring, hvor instruktionerne kommer næste gang. Overvej et program, der indeholder en “IF” – erklæring: den kontrollerer for en tilstand, og hvis betingelsen er sand, springer processoren til et andet sted i programmet. Dette er et eksempel på en betinget greninstruktion, men der er andre instruktioner, der også fører til ændringer i instruktionsstrømmen.
overvej nu, hvad der sker, når en sådan greninstruktion kommer ind i en rørledning. Det er en situation, der fører til en gåde. Når instruktionen ankommer i begyndelsen af rørledningen, kender vi ikke dens resultat, før den er kommet ret dybt ind i rørledningen. Og uden at vide dette resultat, kan vi ikke hente den næste instruktion. En simpel, men naiv løsning er at forhindre nye instruktioner i at komme ind i rørledningen, indtil greninstruktionen når et punkt, hvor vi ved, hvor den næste instruktion kommer fra. Mange urcyklusser spildes i denne proces, fordi rørledninger typisk har 15 til 25 trin. Endnu værre kommer filialinstruktioner ganske ofte op og tegner sig for op mod 20 procent af alle instruktionerne i mange programmer.
for at undgå de høje ydelsesomkostninger ved at stoppe rørledningen bruger moderne processorer en arkitektonisk enhed kaldet en filialprædiktor til at gætte, hvor den næste instruktion efter en filial kommer fra. Formålet med denne forudsigelse er at spekulere om et par nøglepunkter. For det første vil der blive taget en betinget gren, der får programmet til at svinge til en anden del af programmet, eller vil det fortsætte på den eksisterende vej? Og for det andet, hvis filialen er taget, hvor vil programmet gå—hvad bliver den næste instruktion? Bevæbnet med disse forudsigelser kan processorrørledningen holdes fuld.
fordi instruktionsudførelsen er baseret på en forudsigelse, udføres den “spekulativt”: hvis forudsigelsen er korrekt, forbedres ydeevnen væsentligt. Men hvis forudsigelsen viser sig forkert, skal processoren være i stand til at fortryde virkningerne af spekulativt udførte instruktioner relativt hurtigt.
udformningen af filialprædiktoren er blevet grundigt undersøgt i computerarkitektursamfundet i mange år. Moderne forudsigere bruger eksekveringshistorien inden for et program som grundlag for deres resultater. Denne ordning opnår nøjagtigheder på over 95 procent på mange forskellige slags programmer, hvilket fører til dramatiske ydelsesforbedringer sammenlignet med en mikroprocessor, der ikke spekulerer. Misspekulation er dog mulig. Og desværre er det misspekulation, som Spectre-angrebene udnytter.
en anden form for spekulation, der har ført til problemer, er spekulation inden for en enkelt instruktion i pipeline. Det er et ret voldsomt koncept, så lad os pakke det ud. Antag, at en instruktion kræver tilladelse til at udføre. For eksempel kan en instruktion lede computeren til at skrive en del af data til den del af hukommelsen, der er forbeholdt kernen i operativsystemet. Du ønsker ikke, at det skal ske, medmindre det blev sanktioneret af selve operativsystemet, eller du risikerer at gå ned på computeren. Før opdagelsen af nedsmeltning og Spectre var den konventionelle visdom, at det er okay at begynde at udføre instruktionen spekulativt, selv før processoren har nået det punkt at kontrollere, om instruktionen har tilladelse til at udføre sit arbejde eller ej.
i sidste ende, hvis tilladelsen ikke er opfyldt—i vores eksempel har operativsystemet ikke sanktioneret dette forsøg på at fikle med sin hukommelse—resultaterne smides ud, og programmet angiver en fejl. Generelt kan processoren spekulere omkring enhver del af en instruktion, der kan få den til at vente, forudsat at tilstanden til sidst løses, og eventuelle resultater fra dårlige gæt er, effektivt, fortrydes. Det er denne type intra-instruktion spekulation, der ligger bag alle varianter af Nedsmeltningsfejlen, herunder dens uden tvivl farligere version, foreskygge.
den indsigt, der muliggør spekulationsangreb, er dette: under forkert spekulation sker der ingen ændring, som et program direkte kan observere. Med andre ord er der ikke noget program, du kunne skrive, der blot ville vise data genereret under spekulativ udførelse. Det faktum, at spekulation forekommer, efterlader imidlertid spor ved at påvirke, hvor lang tid det tager instruktioner at udføre. Og desværre er det nu klart, at vi kan registrere disse timing signaler og udtrække hemmelige data fra dem.
Hvad er denne timing information, og hvordan får en hacker fat i det? For at forstå det skal du forstå begrebet sidekanaler. En sidekanal er en utilsigtet vej, der lækker information fra en enhed til en anden (normalt begge er programmer), typisk gennem en delt ressource såsom en harddisk eller hukommelse.
som et eksempel på et sidekanalangreb skal du overveje en enhed, der er programmeret til at lytte til lyden fra en printer og derefter bruger den lyd til at udlede, hvad der udskrives. Lyden er i dette tilfælde en sidekanal.
i mikroprocessorer kan enhver delt udstyrsressource i princippet bruges som en sidekanal, der lækker information fra et offerprogram til et angriberprogram. I et almindeligt anvendt sidekanalangreb er den delte ressource CPU ‘ ens cache. Cachen er en relativt lille, hurtig adgangshukommelse på processorchippen, der bruges til at gemme de data, der oftest kræves af et program. Når ET program får adgang til hukommelse, kontrollerer processoren først cachen; hvis dataene er der (et cache-hit), gendannes de hurtigt. Hvis dataene ikke er i cachen (en miss), skal processoren vente, indtil den hentes fra hovedhukommelsen, hvilket kan tage flere hundrede urcyklusser. Men når dataene kommer fra hovedhukommelsen, tilføjes de til cachen, hvilket kan kræve at smide nogle andre data ud for at gøre plads. Cachen er opdelt i segmenter kaldet cache sæt, og hver placering i hovedhukommelsen har et tilsvarende sæt i cachen. Denne organisation gør det nemt at kontrollere, om der er noget i cachen uden at skulle søge i det hele.
Cache-baserede angreb var blevet grundigt undersøgt, selv før Spectre og nedsmeltning dukkede op på scenen. Selvom angriberen ikke direkte kan læse offerets data—selv når disse data sidder i en delt ressource som cachen-kan angriberen få oplysninger om de hukommelsesadresser, som offeret har adgang til. Disse adresser kan afhænge af følsomme data, så en smart angriber kan gendanne disse hemmelige data.
Hvordan gør angriberen dette? Der er flere mulige måder. En variation, kaldet Flush og Reload, begynder med, at angriberen fjerner delte data fra cachen ved hjælp af “flush” – instruktionen. Angriberen venter derefter på, at offeret får adgang til disse data. Fordi det ikke længere er i cachen, skal alle data, som offeret anmoder om, hentes fra hovedhukommelsen. Senere får angriberen adgang til de delte data, mens timingen tager, hvor lang tid det tager. Et cache-hit-hvilket betyder, at dataene er tilbage i cachen—indikerer, at offeret fik adgang til dataene. En cache miss angiver, at dataene ikke er blevet åbnet. Så ved blot at måle, hvor lang tid det tog at få adgang til data, kan angriberen bestemme, hvilke cache-sæt offeret fik adgang til. Det kræver lidt algoritmisk magi, men denne viden om, hvilke cache-sæt der blev adgang til, og som ikke var, kan føre til opdagelsen af krypteringsnøgler og andre hemmeligheder.
nedsmeltning, Spectre og deres varianter følger alle det samme mønster. For det første udløser de spekulation for at udføre kode, som angriberen ønsker. Denne kode læser hemmelige data uden tilladelse. Derefter kommunikerer angrebene hemmeligheden ved hjælp af Flush og Reload eller en lignende sidekanal. Den sidste del er godt forstået og lignende i alle angrebsvariationerne. Angrebene adskiller sig således kun i den første komponent, som er, hvordan man udløser og udnytter spekulation.
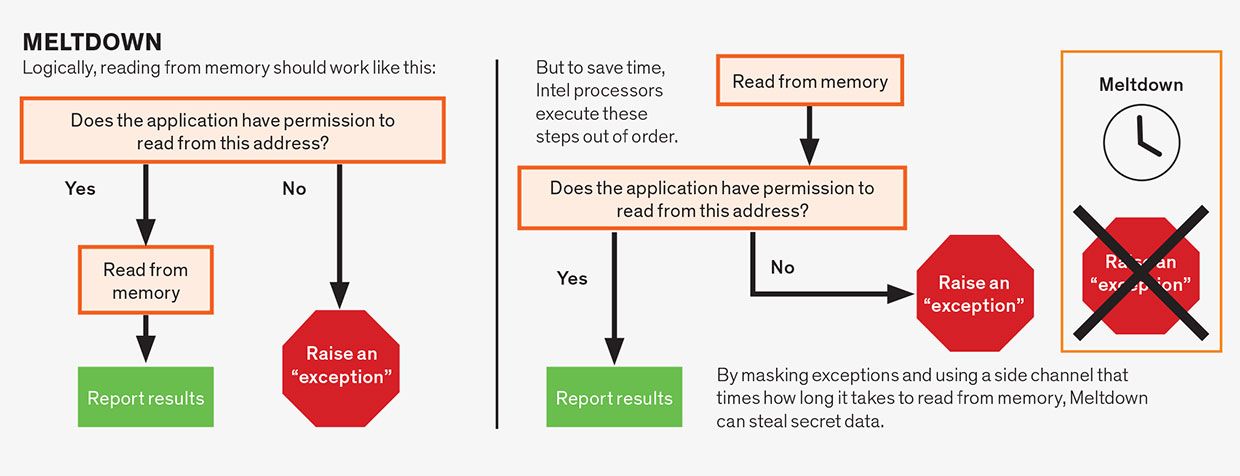
Nedsmeltningsangreb
Nedsmeltningsangreb udnytter spekulation inden for en enkelt instruktion. Selvom monteringssprogsinstruktioner typisk er enkle, består en enkelt instruktion ofte af flere operationer, der kan afhænge af hinanden. For eksempel er hukommelseslæsningsoperationer ofte afhængige af den instruktion, der opfylder de tilladelser, der er knyttet til den hukommelsesadresse, der læses. En applikation har normalt tilladelse til kun at læse fra hukommelse, der er tildelt den, ikke fra hukommelse, der er tildelt f.eks. Logisk set bør vi kontrollere tilladelserne, før vi tillader læsningen at fortsætte, hvilket er, hvad nogle mikroprocessorer gør, især dem fra AMD. Forudsat at det endelige resultat er korrekt, antog CPU-designere imidlertid, at de var fri til spekulativt at udføre disse operationer ude af drift. Derfor læser Intel-mikroprocessorer hukommelsesplaceringen, før de kontrollerer tilladelser, men kun “forpligter” instruktionen—hvilket gør resultaterne synlige for programmet—når tilladelserne er opfyldt. Men fordi de hemmelige data er hentet spekulativt, kan de opdages ved hjælp af en sidekanal, hvilket gør Intel-processorer sårbare over for dette angreb.
varsle angrebet er en variation af nedsmeltning sårbarhed. Dette angreb påvirker Intel mikroprocessorer på grund af en svaghed, som Intel refererer til som L1 Terminal Fault (L1TF). Mens det oprindelige Nedsmeltningsangreb var afhængig af en forsinkelse i kontrollen af tilladelser, varsle afhængig af spekulation, der opstår under et trin i rørledningen kaldet adresseoversættelse.
programmet ser computerens hukommelse og lagringsaktiver som en enkelt sammenhængende strækning af virtuel hukommelse helt sin egen. Men fysisk er disse aktiver opdelt og delt mellem forskellige programmer og processer. Adresseoversættelse forvandler en virtuel hukommelsesadresse til en fysisk hukommelsesadresse.
specialiserede kredsløb på mikroprocessoren hjælper med oversættelse af virtuel til fysisk hukommelse-adresse, men det kan være langsomt, hvilket kræver flere hukommelsesopslag. For at fremskynde tingene tillader Intel-mikroprocessorer spekulation under oversættelsesprocessen, hvilket gør det muligt for et program spekulativt at læse indholdet af en del af cachen kaldet L1, uanset hvem der ejer disse data. Angriberen kan gøre dette og derefter afsløre dataene ved hjælp af den sidekanal-tilgang, vi allerede har beskrevet.
på nogle måder varsle er farligere end nedsmeltning, på andre måder er det mindre. I modsætning til nedsmeltning kan forskygge kun læse indholdet af L1-cachen på grund af specifikationerne for Intels implementering af sin processorarkitektur. Dog kan forskygge læse noget indhold i L1-ikke kun data, der kan adresseres af programmet.
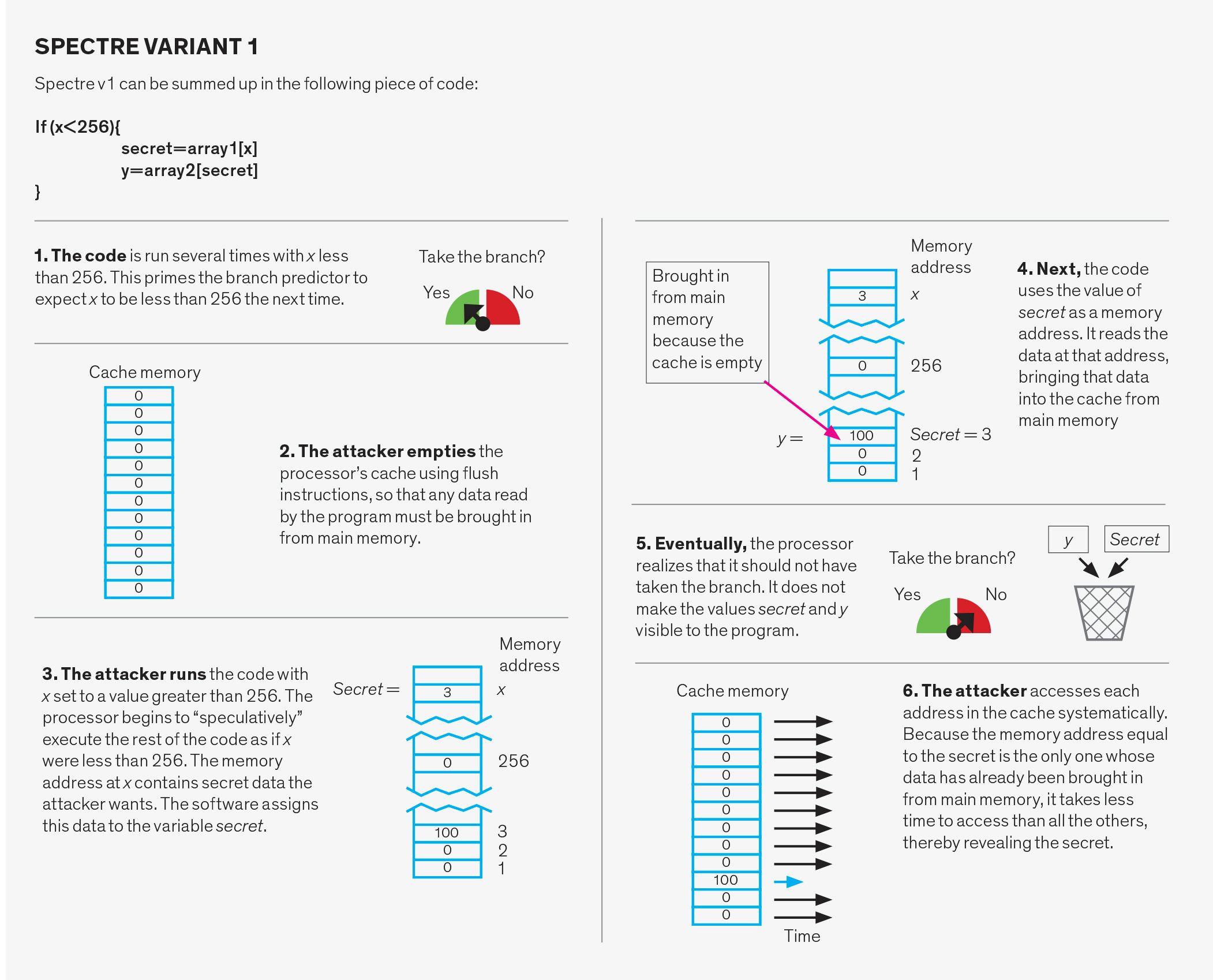
Spectre angreb
Spectre angreb manipulere gren-forudsigelse system. Dette system har tre dele: gren-retning predictor, gren-target predictor, og retur stak buffer.
filialretningsprognosen forudsiger, om en betinget gren, såsom en, der bruges til at implementere en “hvis”-erklæring på et programmeringssprog, vil blive taget eller ikke taget. For at gøre dette sporer den tidligere opførsel af lignende grene. For eksempel kan det betyde, at hvis en gren tages to gange i træk, vil fremtidige forudsigelser sige, at den skal tages.
filialmålprædiktoren forudsiger målhukommelsesadressen for det, der kaldes indirekte grene. I en betinget gren er adressen til den næste instruktion stavet ud, men for en indirekte gren skal adressen først beregnes. Systemet, der forudsiger disse resultater, er en cache-struktur kaldet branch-target buffer. I det væsentlige holder den styr på det sidste beregnede mål for de indirekte grene og bruger disse til at forudsige, hvor den næste indirekte gren skal føre til.
returstakbufferen bruges til at forudsige målet for en “return” – instruktion. Når en subrutine “kaldes” under et program, får returinstruktionen programmet til at genoptage arbejdet på det punkt, hvorfra subrutinen blev kaldt. Forsøg på at forudsige det rigtige punkt at vende tilbage til kun baseret på tidligere returadresser fungerer ikke, fordi den samme funktion kan kaldes fra mange forskellige steder i koden. I stedet bruger systemet returstakbufferen, et stykke hukommelse på processoren, der holder returadresserne på funktioner, som de kaldes. Det bruger derefter disse adresser, når der opstår et afkast i underrutinens kode.
hver af disse tre strukturer kan udnyttes på to forskellige måder. For det første kan forudsigeren bevidst mistrænes. I dette tilfælde udfører angriberen tilsyneladende uskyldig kode designet til at befuddle systemet. Senere udfører angriberen bevidst en gren, der vil forkert spekulere, hvilket får programmet til at hoppe til et stykke kode valgt af angriberen, kaldet en gadget. Gadgeten sætter derefter om at stjæle data.
en anden måde af Spectre angreb kaldes direkte injektion. Det viser sig, at de tre forudsigere under nogle forhold deles mellem forskellige programmer. Hvad dette betyder er, at det angribende program kan fylde forudsigelsesstrukturerne med omhyggeligt valgte dårlige data, når det udføres. Når et uvidende offer udfører deres program enten på samme tid som angriberen eller bagefter, vil offeret afvikle ved hjælp af forudsigelsestilstanden, der blev udfyldt af angriberen og uforvarende modregne en gadget. Dette andet angreb er særligt bekymrende, fordi det gør det muligt for et offerprogram at blive angrebet fra et andet program. En sådan trussel er især skadelig for cloud-tjenesteudbydere, fordi de ikke kan garantere, at deres klientdata er beskyttet.
Spectre-og Nedsmeltningssårbarhederne udgjorde en gåde for computerindustrien, fordi sårbarheden stammer fra udstyr. I nogle tilfælde er det bedste, vi kan gøre for eksisterende systemer—som udgør størstedelen af installerede servere og pc ‘ er—at forsøge at omskrive programmer for at forsøge at begrænse skaden. Men disse løsninger er ad hoc, ufuldstændige og resulterer ofte i et stort hit for computerens ydeevne. Samtidig er forskere og CPU-designere begyndt at tænke på, hvordan man designer fremtidige CPU ‘ er, der holder spekulation uden at gå på kompromis med sikkerheden.
et forsvar, kaldet kernel page-table isolation (KPTI) , er nu indbygget i Kpti og andre operativsystemer. Husk, at hver applikation ser computerens hukommelse og lagringsaktiver som en enkelt sammenhængende strækning af virtuel hukommelse helt sin egen. Men fysisk er disse aktiver opdelt og delt mellem forskellige programmer og processer. Sidetabellen er i det væsentlige operativsystemets kort og fortæller det, hvilke dele af en virtuel hukommelsesadresse, der svarer til hvilke fysiske hukommelsesadresser. Kernel – sidetabellen er ansvarlig for at gøre dette for kernen i operativsystemet. KPTI og lignende systemer forsvarer sig mod nedsmeltning ved at gøre hemmelige data i hukommelsen, såsom operativsystemet, utilgængelige, når en brugers program (og potentielt en angribers program) kører. Det gør det ved at fjerne de forbudte dele fra sidetabellen. På den måde kan selv spekulativt udført kode ikke få adgang til dataene. Denne løsning betyder dog ekstra arbejde for operativsystemet til at kortlægge disse sider, når det udføres og afmappe dem bagefter.
en anden klasse af forsvar giver programmører et sæt værktøjer til at begrænse farlig spekulation. For eksempel omskriver Googles Retpoline patch den slags grene, der er sårbare over for Spectre Variant 2, så det tvinger spekulation til at målrette mod en godartet, tom gadget. Programmører kan også tilføje en samling-sprog instruktion, der begrænser Spectre v1, ved at begrænse spekulative hukommelse læser, der følger betingede grene. Praktisk er denne instruktion allerede til stede i processorarkitekturen og bruges til at håndhæve den korrekte rækkefølge mellem hukommelsesoperationer, der stammer fra forskellige processorkerner.
da processordesignerne måtte Intel og AMD gå dybere end en almindelig programrettelse. Deres rettelser opdaterer processorens mikrokode. Mikrokode er et lag af instruktioner, der passer mellem samlesproget for almindelige programmer og processorens faktiske kredsløb. Mikrokode tilføjer fleksibilitet til det sæt instruktioner, en processor kan udføre. Det gør det også enklere at designe en CPU, fordi når du bruger mikrokode, oversættes komplekse instruktioner til flere enklere instruktioner, der er lettere at udføre i en pipeline.
grundlæggende justerede Intel og AMD deres mikrokode for at ændre opførslen af nogle monteringssprogsinstruktioner på måder, der begrænser spekulation. For eksempel tilføjede Intel-ingeniører muligheder, der forstyrrer nogle af angrebene ved at lade operativsystemet tømme gren-forudsigelsesstrukturerne under visse omstændigheder.
en anden klasse af løsninger forsøger at forstyrre angriberens evne til at overføre dataene ud ved hjælp af sidekanaler. For eksempel opdeler MIT ‘ s teknologi sikkert processorcachen, så forskellige programmer ikke deler nogen af sine ressourcer. Mest ambitiøst er der forslag til nye processorarkitekturer, der introducerer strukturer på CPU ‘ en, der er dedikeret til spekulation og adskilt fra processorens cache og andet udstyr. På denne måde er alle operationer, der udføres spekulativt, men som ikke til sidst begås, aldrig synlige. Hvis spekulationsresultatet bekræftes, sendes de spekulative data til processorens hovedstrukturer.
Spekulationssårbarheder har ligget i dvale i processorer i over 20 år, og de forblev, så vidt nogen ved, uudnyttet. Deres opdagelse har i væsentlig grad rystet industrien og fremhævet, hvordan cybersikkerhed ikke kun er et problem for programmelsystemer, men også for udstyr. Siden den første opdagelse er omkring et dusin varianter af Spectre og nedsmeltning blevet afsløret, og det er sandsynligt, at der er flere. Spectre og nedsmeltning er trods alt bivirkninger af centrale designprincipper, som vi har påberåbt os for at forbedre computerens ydeevne, hvilket gør det vanskeligt at fjerne sådanne sårbarheder i nuværende systemdesign. Det er sandsynligt, at nye CPU-design vil udvikle sig for at bevare spekulation, samtidig med at man forhindrer den type sidekanallækage, der muliggør disse angreb. Ikke desto mindre skal fremtidige computersystemdesignere, herunder dem, der designer processorchips, være opmærksomme på de sikkerhedsmæssige konsekvenser af deres beslutninger og ikke længere optimere kun for ydeevne, størrelse og strøm.
om forfatteren
Nael Abu-Ghasaleh er formand for computer engineering program ved University of California, Riverside. Dmitry Evtyushkin er adjunkt i datalogi ved Universitetet i Vilhelm og Mary i Vilhelmsburg, Va. Dmitry Ponomarev er professor i datalogi ved Binghamton.
for at undersøge yderligere
Paul Kocher og de andre forskere, der kollektivt afslørede Spectre, forklarede det først her . Morit Lipp forklarede nedsmeltning i denne tale ved Useniks sikkerhed ’18. Forskud blev detaljeret på samme konference.
en gruppe forskere, herunder en af forfatterne, er kommet med en systematisk evaluering af Spectre-og Nedsmeltningsangreb, der afslører yderligere potentielle angreb . IBM-ingeniører gjorde noget lignende, og Google-ingeniører kom for nylig til den konklusion, at sidekanals-og spekulative eksekveringsangreb er kommet for at blive .