Un entrepôt de données est un système électronique qui recueille des données provenant d’un large éventail de sources au sein d’une entreprise et les utilise pour prendre des décisions de gestion.
Les entreprises se tournent de plus en plus vers des entrepôts de données basés sur le cloud au lieu des systèmes traditionnels sur site. Les entrepôts de données basés sur le cloud diffèrent des entrepôts traditionnels des manières suivantes:
- Il n’est pas nécessaire d’acheter du matériel physique.
- Il est plus rapide et moins coûteux de configurer et de faire évoluer des entrepôts de données dans le cloud.
- Les architectures d’entrepôt de données basées sur le Cloud peuvent généralement effectuer des requêtes analytiques complexes beaucoup plus rapidement car elles utilisent le traitement massivement parallèle (MPP).
Le reste de cet article couvre l’architecture traditionnelle des entrepôts de données et présente quelques idées et concepts architecturaux utilisés par les services d’entrepôts de données basés sur le cloud les plus populaires.
Pour plus de détails, consultez notre page sur les concepts d’entrepôt de données dans ce guide.
- Architecture d’entrepôt de données traditionnel
- Architecture à trois niveaux
- Kimball vs. Inmon
- Modèles d’entrepôt de données
- Schéma Étoile par rapport au schéma Flocon de neige
- ETL vs ELT
- Maturité organisationnelle
- Nouvelles architectures d’entrepôts de données
- Amazon Redshift
- Google BigQuery
- Panoply
- Au-delà des entrepôts de données Cloud
- En savoir plus sur les entrepôts de données
Architecture d’entrepôt de données traditionnel
Les concepts suivants mettent en évidence certaines des idées et principes de conception établis utilisés pour la construction d’entrepôts de données traditionnels.
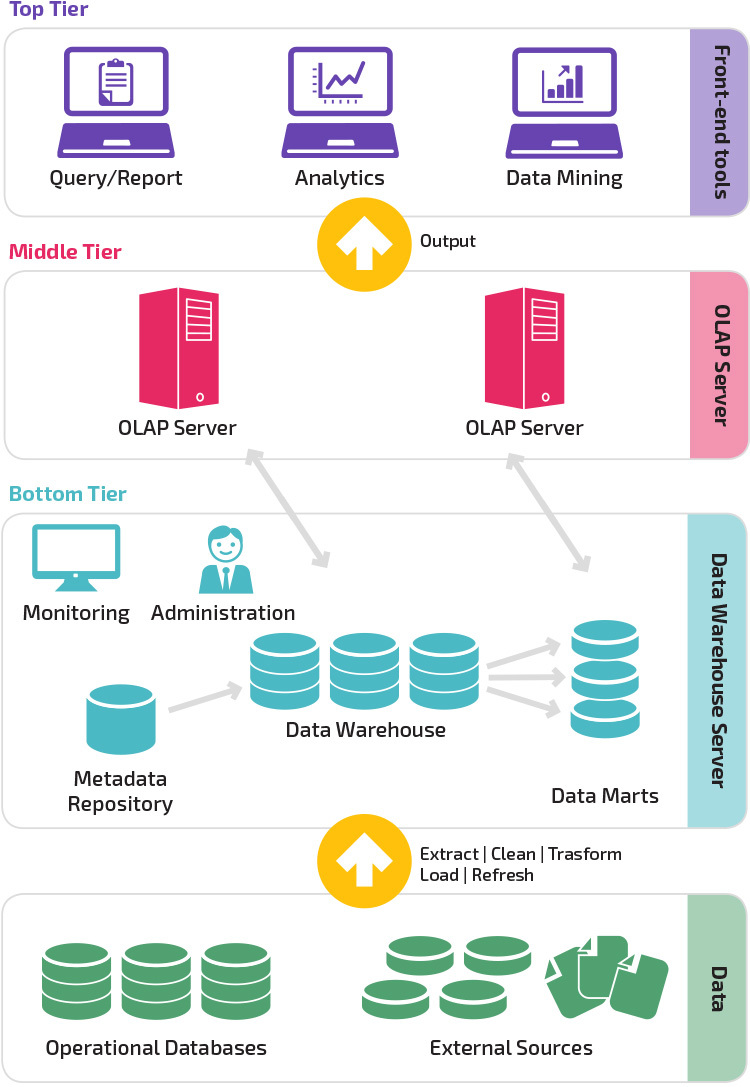
Architecture à trois niveaux
L’architecture d’entrepôt de données traditionnelle utilise une structure à trois niveaux composée des niveaux suivants.
- Niveau inférieur : Ce niveau contient le serveur de base de données utilisé pour extraire des données de nombreuses sources différentes, telles que des bases de données transactionnelles utilisées pour les applications frontales.
- Niveau intermédiaire: Le niveau intermédiaire abrite un serveur OLAP, qui transforme les données en une structure mieux adaptée à l’analyse et aux requêtes complexes. Le serveur OLAP peut fonctionner de deux manières : soit en tant que système de gestion de base de données relationnelle étendue qui mappe les opérations sur des données multidimensionnelles aux opérations relationnelles standard (OLAP relationnel), soit en utilisant un modèle OLAP multidimensionnel qui implémente directement les données et les opérations multidimensionnelles.
- Niveau supérieur : Le niveau supérieur est la couche client. Ce niveau contient les outils utilisés pour l’analyse de données de haut niveau, les rapports d’interrogation et l’exploration de données.
Kimball vs. Inmon
Deux pionniers de l’entreposage de données nommés Bill Inmon et Ralph Kimball avaient des approches différentes de la conception de l’entrepôt de données.
L’approche de Ralph Kimball a souligné l’importance des data marts, qui sont des dépôts de données appartenant à des secteurs d’activité particuliers. L’entrepôt de données est simplement une combinaison de différents marchés de données qui facilite le reporting et l’analyse. La conception de l’entrepôt de données Kimball utilise une approche « ascendante ».
Bill Inmon considérait l’entrepôt de données comme le référentiel centralisé de toutes les données d’entreprise. Dans cette approche, une organisation crée d’abord un modèle d’entrepôt de données normalisé. Les magasins de données dimensionnelles sont ensuite créés sur la base du modèle d’entrepôt. C’est ce qu’on appelle une approche descendante de l’entreposage de données.
Modèles d’entrepôt de données
Dans une architecture traditionnelle, il existe trois modèles d’entrepôt de données courants : entrepôt virtuel, data mart et entrepôt de données d’entreprise:
- Un entrepôt de données virtuel est un ensemble de bases de données distinctes, qui peuvent être interrogées ensemble, de sorte qu’un utilisateur peut accéder efficacement à toutes les données comme si elles étaient stockées dans un entrepôt de données.
- Un modèle de marché de données est utilisé pour les rapports et les analyses propres à chaque secteur d’activité. Dans ce modèle d’entrepôt de données, les données sont agrégées à partir d’une gamme de systèmes sources pertinents pour un domaine d’activité spécifique, tels que les ventes ou les finances.
- Un modèle d’entrepôt de données d’entreprise prescrit que l’entrepôt de données contient des données agrégées couvrant l’ensemble de l’organisation. Ce modèle considère l’entrepôt de données comme le cœur du système d’information de l’entreprise, avec des données intégrées de toutes les unités commerciales.
Schéma Étoile par rapport au schéma Flocon de neige
Le schéma étoile et le schéma flocon de neige sont deux façons de structurer un entrepôt de données.
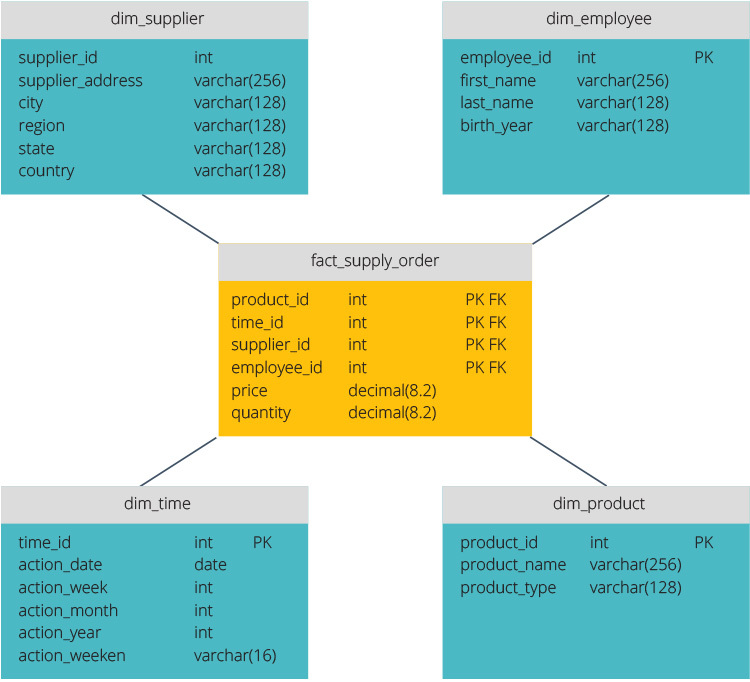
Le schéma en étoile dispose d’un référentiel de données centralisé, stocké dans une table de faits. Le schéma divise la table de faits en une série de tables de dimensions dénormalisées. Le tableau des faits contient des données agrégées à utiliser à des fins de reporting, tandis que le tableau des dimensions décrit les données stockées.
Les conceptions dénormalisées sont moins complexes car les données sont regroupées. La table de faits utilise un seul lien pour se joindre à chaque table de dimensions. La conception plus simple du schéma en étoile facilite grandement l’écriture de requêtes complexes.
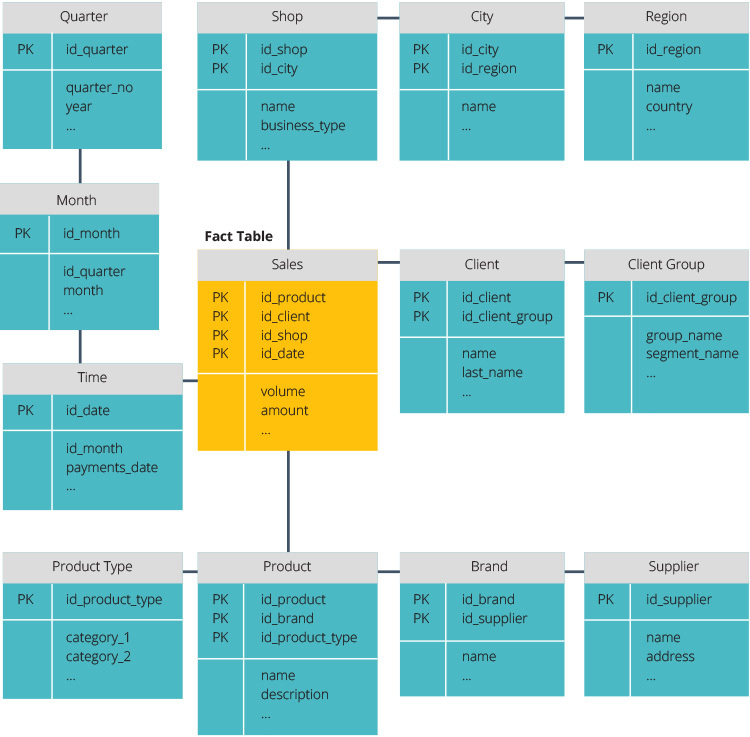
Le schéma snowflake est différent car il normalise les données. La normalisation signifie organiser efficacement les données afin que toutes les dépendances de données soient définies et que chaque table contienne des redondances minimales. Les tables de dimension unique se divisent ainsi en tables de dimension séparées.
Le schéma snowflake utilise moins d’espace disque et préserve mieux l’intégrité des données. Le principal inconvénient est la complexité des requêtes requises pour accéder aux données — chaque requête doit creuser profondément pour accéder aux données pertinentes car il existe plusieurs jointures.
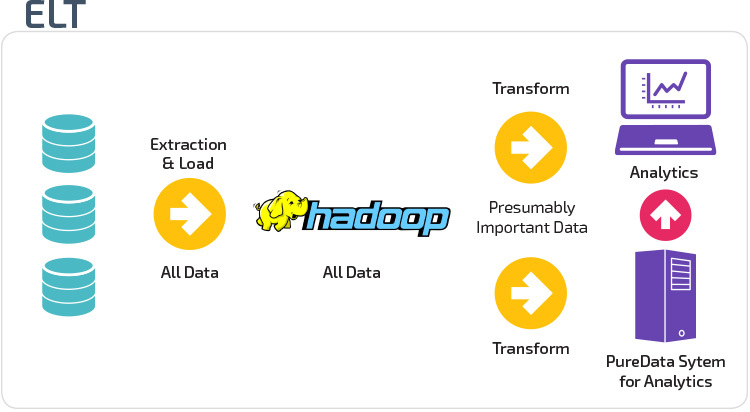
ETL vs ELT
ETL et ELT sont deux méthodes différentes de chargement de données dans un entrepôt.
Extraire, Transformer, Charger (ETL) extrait d’abord les données d’un pool de sources de données, qui sont généralement des bases de données transactionnelles. Les données sont conservées dans une base de données temporaire. Des opérations de transformation sont ensuite effectuées pour structurer et convertir les données sous une forme adaptée au système d’entrepôt de données cible. Les données structurées sont ensuite chargées dans l’entrepôt, prêtes à être analysées.
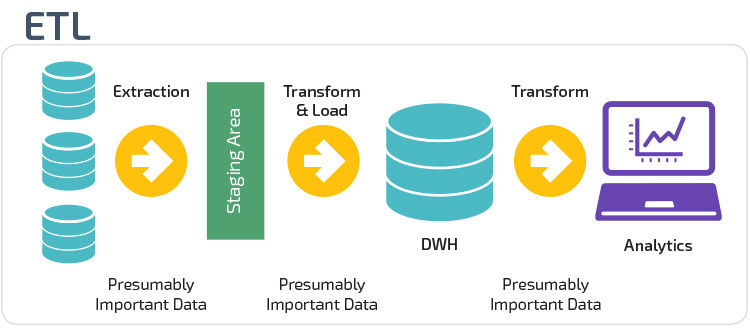
Avec Extract Load Transform (ELT), les données sont immédiatement chargées après avoir été extraites des pools de données source. Il n’y a pas de base de données intermédiaire, ce qui signifie que les données sont immédiatement chargées dans le référentiel unique et centralisé. Les données sont transformées à l’intérieur du système d’entrepôt de données pour être utilisées avec des outils de business intelligence et d’analyse.
Maturité organisationnelle
La structure de l’entrepôt de données d’une organisation dépend également de sa situation actuelle et de ses besoins.
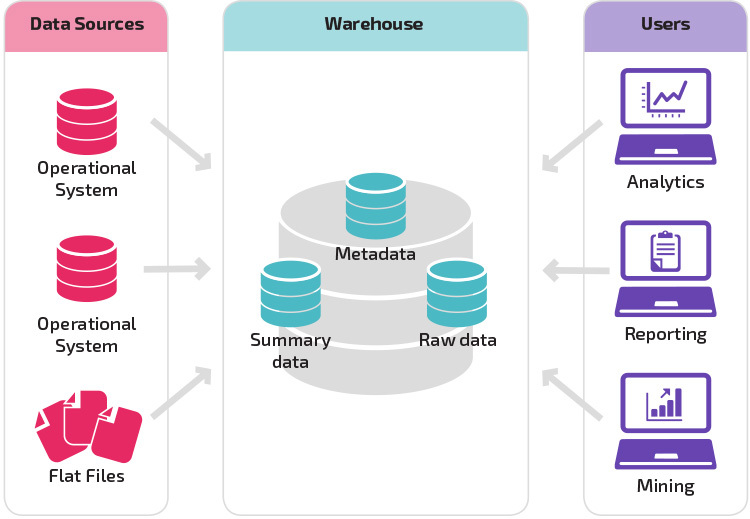
La structure de base permet aux utilisateurs finaux de l’entrepôt d’accéder directement aux données récapitulatives dérivées des systèmes sources et d’effectuer des analyses, des rapports et une exploration de ces données. Cette structure est utile lorsque les sources de données dérivent des mêmes types de systèmes de base de données.
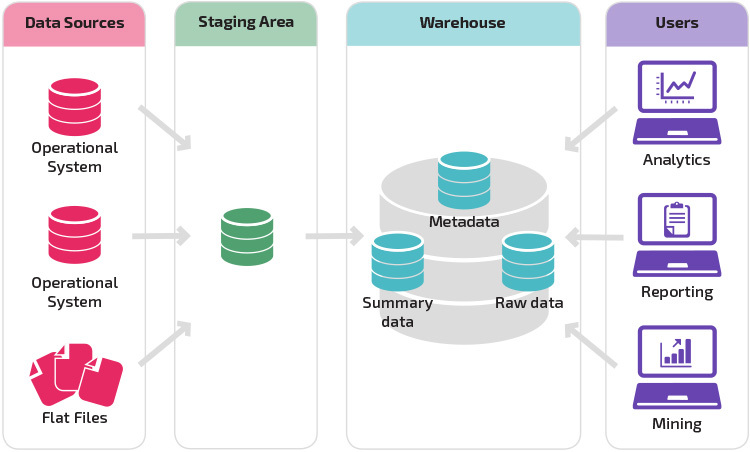
Un entrepôt avec une zone de transit est la prochaine étape logique dans une organisation avec des sources de données disparates avec de nombreux types et formats de données différents. La zone intermédiaire convertit les données en un format structuré résumé qui est plus facile à interroger avec des outils d’analyse et de création de rapports.
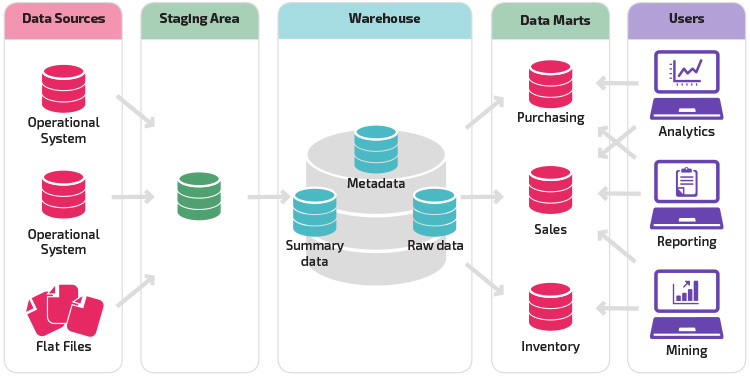
Une variante de la structure de transfert est l’ajout de data marts à l’entrepôt de données. Les data marts stockent des données résumées pour un secteur d’activité particulier, ce qui les rend facilement accessibles pour des formes d’analyse spécifiques. Par exemple, l’ajout de data marts peut permettre à un analyste financier d’effectuer plus facilement des requêtes détaillées sur les données de vente, de faire des prédictions sur le comportement des clients. Les Data marts facilitent l’analyse en adaptant les données spécifiquement aux besoins de l’utilisateur final.
Nouvelles architectures d’entrepôts de données
Ces dernières années, les entrepôts de données se déplacent vers le cloud. Les nouveaux entrepôts de données basés sur le cloud ne respectent pas l’architecture traditionnelle ; chaque offre d’entrepôt de données a une architecture unique.
Cette section résume les architectures utilisées par deux des entrepôts cloud les plus populaires : Amazon Redshift et Google BigQuery.
Amazon Redshift
Amazon Redshift est une représentation basée sur le cloud d’un entrepôt de données traditionnel.
Redshift nécessite que les ressources informatiques soient provisionnées et configurées sous la forme de clusters, qui contiennent une collection d’un ou plusieurs nœuds. Chaque nœud a son propre processeur, stockage et RAM. Un nœud leader compile les requêtes et les transfère aux nœuds de calcul, qui exécutent les requêtes.
Sur chaque nœud, les données sont stockées en morceaux, appelés tranches. Redshift utilise un stockage en colonnes, ce qui signifie que chaque bloc de données contient des valeurs d’une seule colonne sur un certain nombre de lignes, au lieu d’une seule ligne avec des valeurs de plusieurs colonnes.
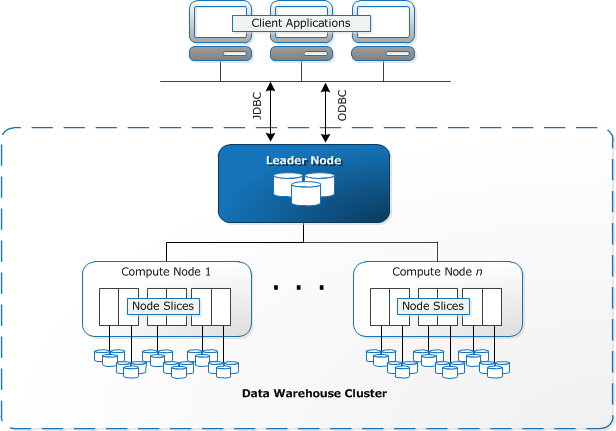
Source : Documentation AWS
Redshift utilise une architecture MPP, divisant les grands ensembles de données en morceaux qui sont affectés à des tranches dans chaque nœud. Les requêtes s’exécutent plus rapidement car les nœuds de calcul traitent les requêtes dans chaque tranche simultanément. Le nœud Leader agrège les résultats et les renvoie à l’application cliente.
Les applications clientes, telles que les outils de BI et d’analyse, peuvent se connecter directement à Redshift à l’aide des pilotes JDBC et ODBC open source PostgreSQL. Les analystes peuvent ainsi effectuer leurs tâches directement sur les données Redshift.
Redshift ne peut charger que des données structurées. Il est possible de charger des données sur Redshift à l’aide de systèmes pré-intégrés, notamment Amazon S3 et DynamoDB, en poussant des données depuis n’importe quel hôte sur site doté d’une connectivité SSH ou en intégrant d’autres sources de données à l’aide de l’API Redshift.
Google BigQuery
L’architecture de BigQuery est sans serveur, ce qui signifie que Google gère dynamiquement l’allocation des ressources de la machine. Toutes les décisions de gestion des ressources sont donc cachées à l’utilisateur.
BigQuery permet aux clients de charger des données à partir de Google Cloud Storage et d’autres sources de données lisibles. L’option alternative consiste à diffuser des données, ce qui permet aux développeurs d’ajouter des données à l’entrepôt de données en temps réel, ligne par ligne, au fur et à mesure qu’elles deviennent disponibles.
BigQuery utilise un moteur d’exécution de requêtes nommé Dremel, qui peut analyser des milliards de lignes de données en quelques secondes seulement. Dremel utilise l’interrogation massivement parallèle pour analyser les données dans le système de gestion de fichiers Colossus sous-jacent. Colossus distribue les fichiers en morceaux de 64 mégaoctets parmi de nombreuses ressources informatiques nommées nœuds, qui sont regroupées en clusters.
Dremel utilise une structure de données en colonnes, similaire à Redshift. Une architecture arborescente envoie des requêtes parmi des milliers de machines en quelques secondes.
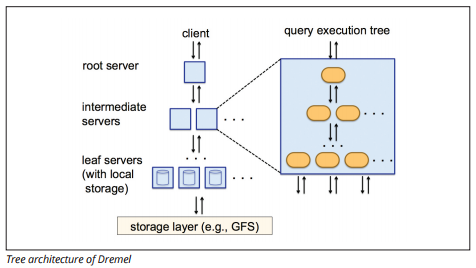
Source d’image
Des commandes SQL simples sont utilisées pour effectuer des requêtes sur des données.
Panoply
Panoply fournit une gestion des données de bout en bout en tant que service. Son architecture d’auto-optimisation unique utilise l’apprentissage automatique et le traitement du langage naturel (PNL) pour modéliser et rationaliser le parcours des données de la source à l’analyse, réduisant ainsi le temps passé des données à la valeur aussi proche que possible de zéro.
L’infrastructure de données intelligentes de Panoply comprend les fonctionnalités suivantes:
- Analyse des requêtes et des données – identification de la meilleure configuration pour chaque cas d’utilisation, ajustement au fil du temps, et construction d’index, de clés de tri, de disquettes, de types de données, d’aspiration et de partitionnement.
- Identifie les requêtes qui ne suivent pas les meilleures pratiques – telles que celles qui incluent des boucles imbriquées ou un casting implicite – et les réécrit en une requête équivalente nécessitant une fraction du temps d’exécution ou des ressources.
- Optimisation des configurations de serveur dans le temps en fonction des modèles de requête et en apprenant quelle configuration de serveur fonctionne le mieux. La plate-forme change de type de serveur de manière transparente et mesure les performances qui en résultent.
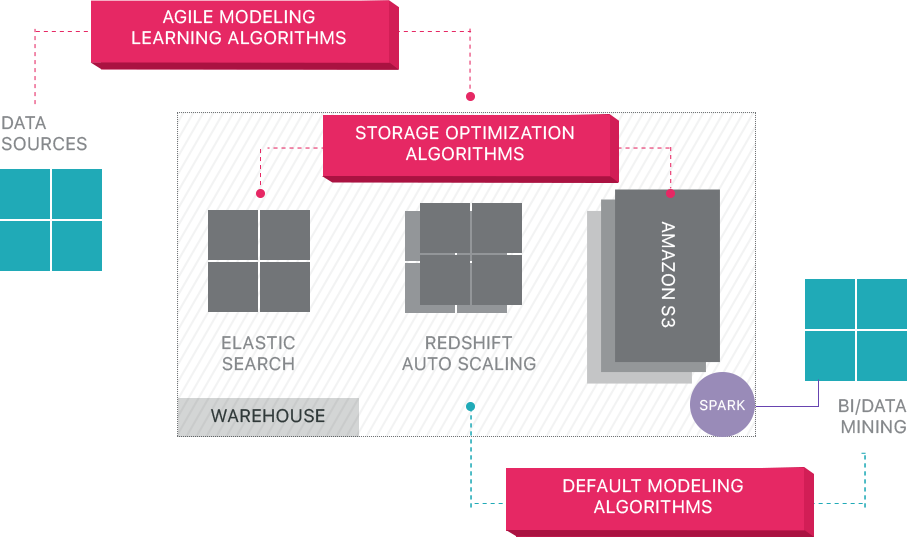
Au-delà des entrepôts de données Cloud
Les entrepôts de données basés sur le Cloud constituent un grand pas en avant par rapport aux architectures traditionnelles. Cependant, les utilisateurs sont toujours confrontés à plusieurs défis lors de leur configuration:
- Le chargement de données dans des entrepôts de données cloud n’est pas trivial et, pour les pipelines de données à grande échelle, il nécessite la configuration, les tests et la maintenance d’un processus ETL. Cette partie du processus est généralement effectuée avec des outils tiers.
- Les mises à jour, les mises à jour et les suppressions peuvent être délicates et doivent être effectuées avec soin pour éviter la dégradation des performances des requêtes.
- Les données semi-structurées sont difficiles à traiter – elles doivent être normalisées dans un format de base de données relationnelle, ce qui nécessite une automatisation pour les flux de données volumineux.
- Les structures imbriquées ne sont généralement pas prises en charge dans les entrepôts de données cloud. Vous devrez aplatir les tables imbriquées dans un format que l’entrepôt de données peut comprendre.
- Optimisation de votre cluster – il existe différentes options pour configurer un cluster Redshift pour exécuter vos charges de travail. Différentes charges de travail, ensembles de données ou même différents types de requêtes peuvent nécessiter une configuration différente. Pour rester optimal, vous devrez continuellement revoir et modifier votre configuration.
- Optimisation des requêtes – les requêtes des utilisateurs peuvent ne pas suivre les meilleures pratiques et, par conséquent, leur exécution prendra beaucoup plus de temps. Vous pouvez vous retrouver à travailler avec des utilisateurs ou des applications clientes automatisées pour optimiser les requêtes afin que l’entrepôt de données puisse fonctionner comme prévu.
- Sauvegarde et restauration – bien que les fournisseurs d’entrepôts de données offrent de nombreuses options pour sauvegarder vos données, elles ne sont pas anodines à configurer et nécessitent une surveillance et une attention particulière.
Panoply est un entrepôt de données intelligent qui ajoute une couche d’automatisation qui prend en charge toutes les tâches complexes ci-dessus, ce qui vous fait gagner un temps précieux et vous aide à passer des données aux informations en quelques minutes.
En savoir plus sur les outils d’entrepôt de données intelligent de Panoply.
En savoir plus sur les entrepôts de données
- Concepts d’entrepôts de données : Traditionnels vs. Cloud
- Base de données vs Entrepôt de données
- Marché de données vs Entrepôt de données
- Architecture Amazon Redshift