az adattárház olyan elektronikus rendszer, amely a vállalaton belül számos forrásból gyűjt adatokat, és az adatokat a vezetői döntéshozatal támogatására használja fel.
a vállalatok egyre inkább a felhőalapú adattárházak felé haladnak a hagyományos helyszíni rendszerek helyett. A felhőalapú adattárházak a következő módon különböznek a hagyományos raktáraktól:
- nincs szükség fizikai hardver vásárlására.
- gyorsabb és olcsóbb a felhőalapú adattárházak beállítása és méretezése.
- a felhőalapú adattárház-architektúrák általában sokkal gyorsabban képesek komplex analitikai lekérdezéseket végrehajtani, mivel tömegesen párhuzamos feldolgozást (MPP) használnak.
a cikk további része a hagyományos adattárház-architektúrával foglalkozik, és bemutatja a legnépszerűbb felhőalapú adattárház-szolgáltatások által használt építészeti ötleteket és koncepciókat.
további részletekért tekintse meg az adattárház koncepcióiról szóló oldalunkat ebben az útmutatóban.
hagyományos adattárház architektúra
az alábbi fogalmak kiemelik a hagyományos adattárházak építéséhez használt ötleteket és tervezési elveket.
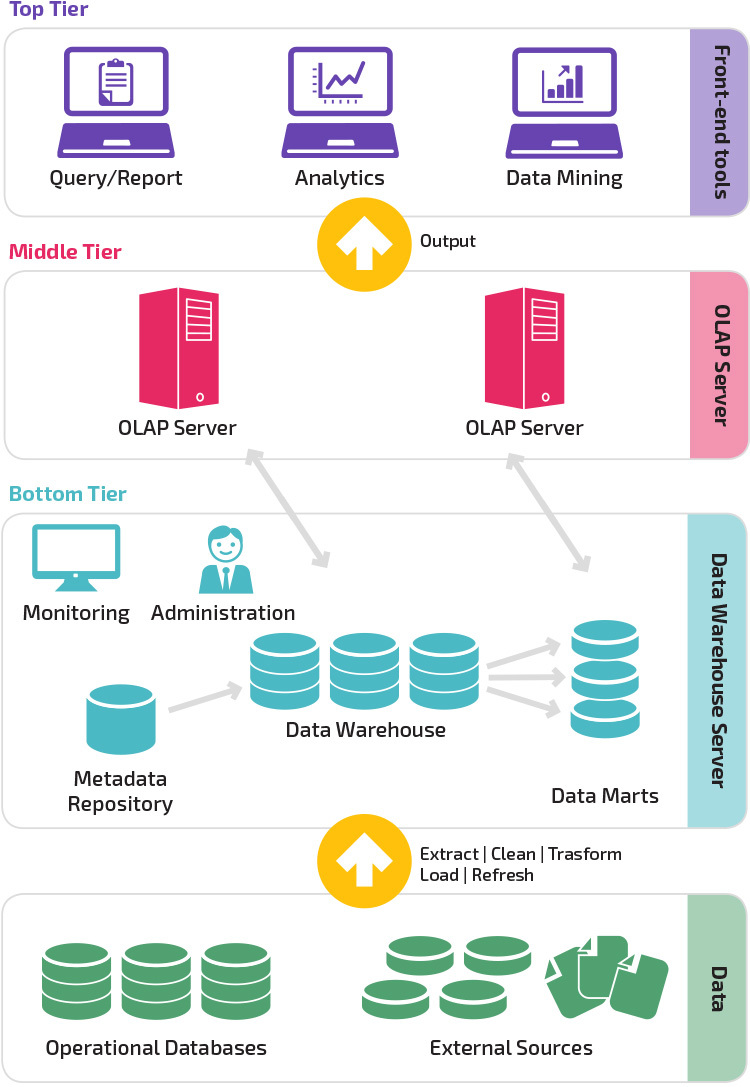
háromszintű architektúra
a hagyományos adattárház-architektúra háromszintű struktúrát alkalmaz, amely a következő szintekből áll.
- alsó szint: ez a szint tartalmazza azt az adatbázis-kiszolgálót, amelyet számos különböző forrásból, például a front-end alkalmazásokhoz használt tranzakciós adatbázisokból származó adatok kinyerésére használnak.
- középső szint: A középső szint egy OLAP szervert tartalmaz, amely az adatokat elemzésre és komplex lekérdezésre jobban alkalmas struktúrává alakítja. Az OLAP szerver kétféleképpen működhet: vagy kiterjesztett relációs adatbázis-kezelő rendszerként, amely a többdimenziós adatok műveleteit szabványos relációs műveletekre (relációs OLAP) térképezi fel, vagy egy többdimenziós OLAP modellt használ, amely közvetlenül végrehajtja a többdimenziós adatokat és műveleteket.
- Felső szint: a felső szint az ügyfélréteg. Ez a szint tartalmazza a magas szintű adatelemzéshez, lekérdezési jelentésekhez és adatbányászathoz használt eszközöket.
Kimball vs. Inmon
az adattárház két úttörője, Bill Inmon és Ralph Kimball eltérő megközelítést alkalmazott az adattárház tervezésében.
Ralph Kimball megközelítése hangsúlyozta az adatpiacok fontosságát, amelyek bizonyos üzletágakhoz tartozó adatok tárolói. Az adattárház egyszerűen különböző adatpiacok kombinációja, amely megkönnyíti a jelentést és az elemzést. A Kimball adattárház tervezése “alulról felfelé” megközelítést alkalmaz.
Bill Inmon az adattárházat tekintette az összes vállalati adat központi tárolójának. Ebben a megközelítésben a szervezet először létrehoz egy normalizált adattárház modellt. Ezután a raktármodell alapján létrejönnek a dimenziós adatpiacok. Ezt az adattárház felülről lefelé történő megközelítésének nevezik.
adattárház modellek
a hagyományos architektúrában három általános adattárház modell létezik: virtuális raktár, data mart és enterprise data warehouse:
- a virtuális adattárház különálló adatbázisok halmaza, amelyek együtt lekérdezhetők, így a felhasználó hatékonyan hozzáférhet az összes adathoz, mintha egy adattárházban tárolták volna.
- a data mart modellt az üzletág-specifikus jelentésekhez és elemzésekhez használják. Ebben az adattárház modellben az adatokat egy adott üzleti területhez kapcsolódó forrásrendszerek, például értékesítés vagy pénzügyek köréből összesítik.
- egy vállalati adattárház modell előírja, hogy az adattárház az egész szervezetre kiterjedő összesített adatokat tartalmazzon. Ez a modell az adattárházat a vállalati információs rendszer középpontjának tekinti, az összes üzleti egység integrált adataival.
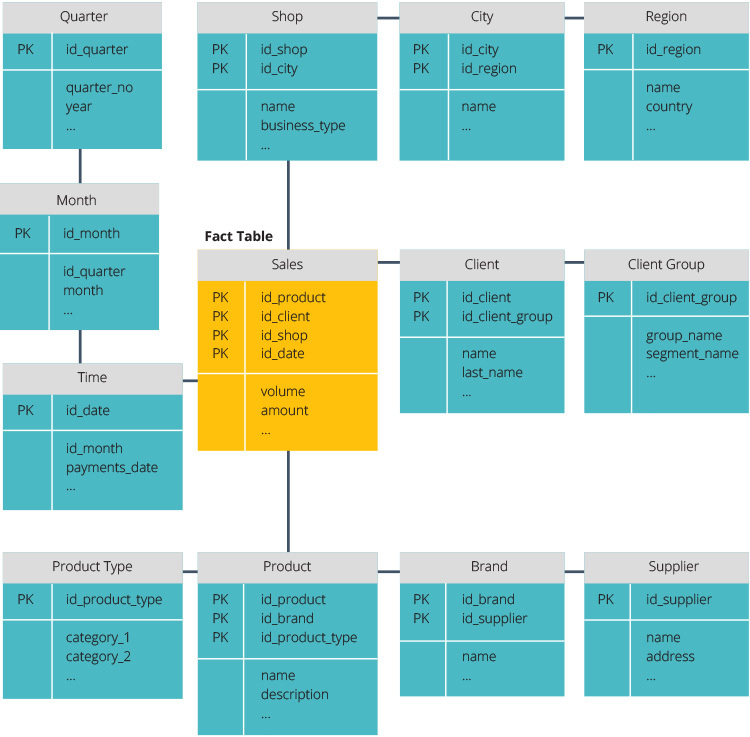
Csillagséma vs.hópehely séma
a csillagséma és a hópehely séma az adattárház felépítésének két módja.
a csillagséma központi adattárral rendelkezik, amelyet egy ténytáblában tárolnak. A séma a ténytáblát denormalizált dimenziótáblák sorozatára osztja. A ténytábla összesített adatokat tartalmaz, amelyeket jelentési célokra kell felhasználni, míg a dimenziótábla a tárolt adatokat írja le.
a denormalizált tervek kevésbé összetettek, mert az adatok csoportosítva vannak. A ténytábla csak egy linket használ az egyes dimenziótáblákhoz való csatlakozáshoz. A csillagséma egyszerűbb kialakítása sokkal könnyebbé teszi az összetett lekérdezések írását.
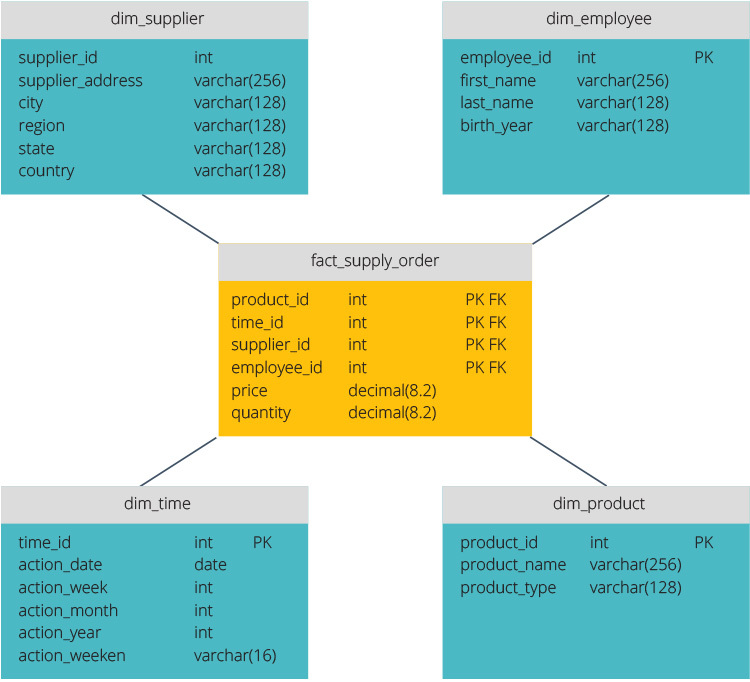
a hópehely séma más, mert normalizálja az adatokat. A normalizálás azt jelenti, hogy hatékonyan rendszerezzük az adatokat úgy, hogy minden adatfüggőség definiálva legyen, és minden táblázat minimális redundanciákat tartalmaz. Az egydimenziós táblázatok így külön dimenziótáblákká válnak.
a hópehely séma kevesebb lemezterületet használ, és jobban megőrzi az adatok integritását. A fő hátrány az adatok eléréséhez szükséges lekérdezések összetettsége—minden lekérdezésnek mélyre kell ásnia, hogy elérje a releváns adatokat, mert több illesztés van.
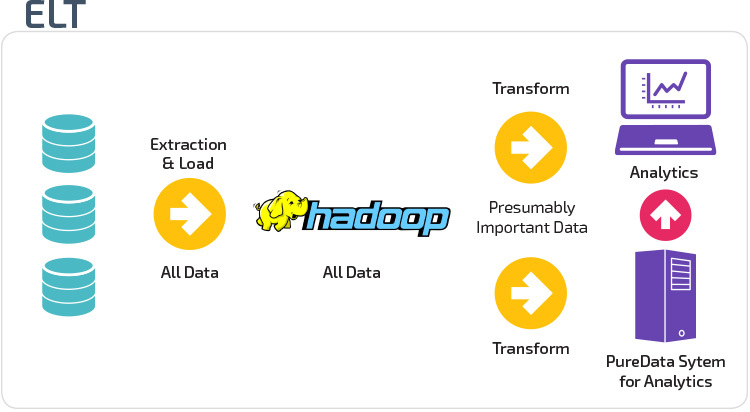
ETL vs. ELT
az ETL és az ELT két különböző módszer az adatok raktárba történő betöltésére.
Extract, Transform, Load (ETL) először kivonja az adatokat egy adatforrásból, amelyek jellemzően tranzakciós adatbázisok. Az adatokat egy ideiglenes átmeneti adatbázisban tárolják. Ezután átalakítási műveleteket hajtanak végre, hogy az adatokat a cél adattárház rendszer számára megfelelő formába strukturálják és átalakítsák. A strukturált adatokat ezután betöltik a raktárba, elemzésre készen.
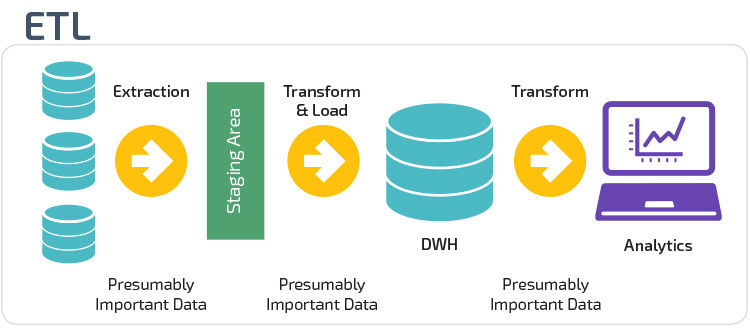
az Extract Load Transform (ELT) segítségével az adatok azonnal betöltődnek, miután kibontották őket a forrásadatkészletekből. Nincs átmeneti adatbázis, ami azt jelenti, hogy az adatok azonnal betöltődnek az egyetlen, központosított adattárba. Az adatokat az adattárház rendszerén belül átalakítják üzleti intelligencia eszközökkel és elemzéssel való használatra.
szervezeti érettség
a szervezet adattárházának felépítése a jelenlegi helyzetétől és igényeitől is függ.
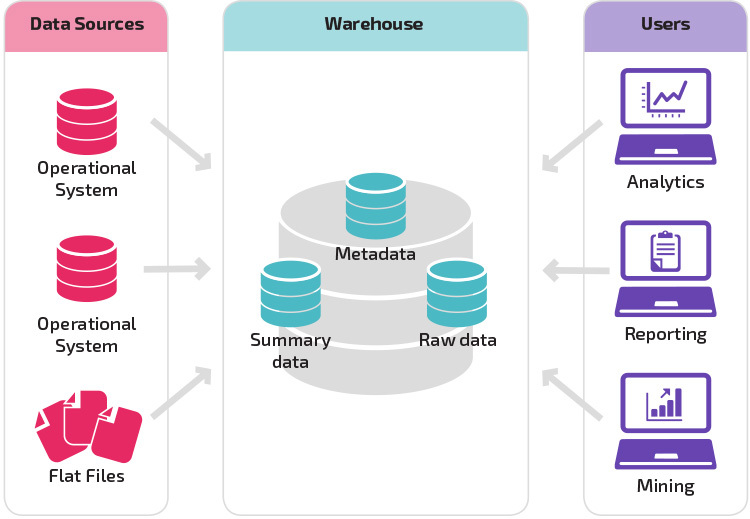
az alapstruktúra lehetővé teszi, hogy a raktár végfelhasználói közvetlenül hozzáférjenek a forrásrendszerekből származó összefoglaló adatokhoz, és elvégezzék az adatok elemzését, jelentését és bányászatát. Ez a struktúra akkor hasznos, ha az adatforrások azonos típusú adatbázis-rendszerekből származnak.
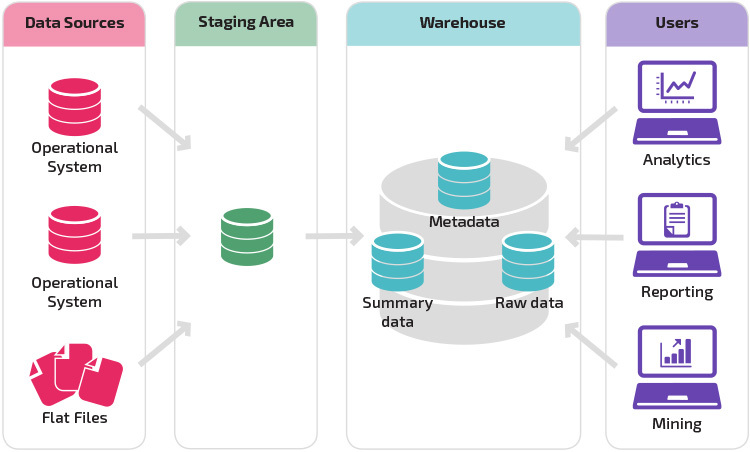
az átmeneti területtel rendelkező raktár a következő logikus lépés egy olyan szervezetben, amely különböző adatforrásokkal rendelkezik, számos különböző típusú és adatformátummal. Az átmeneti terület az adatokat összefoglaló strukturált formátumba konvertálja, amelyet elemzési és jelentéskészítési eszközökkel könnyebb lekérdezni.
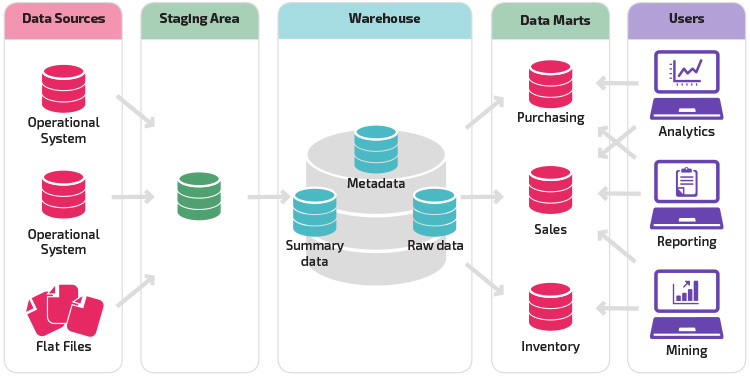
az átmeneti struktúra egyik változata az adattárházba történő adattárház hozzáadása. A data marts egy adott üzletágra vonatkozó összesített adatokat tárol, így ezek az adatok könnyen hozzáférhetők az elemzés meghatározott formáihoz. Például az adatpiacok hozzáadása lehetővé teszi a pénzügyi elemző számára, hogy könnyebben végezzen részletes lekérdezéseket az értékesítési adatokról, hogy előrejelzéseket készítsen az ügyfelek viselkedéséről. A Data marts megkönnyíti az elemzést azáltal, hogy az adatokat kifejezetten a végfelhasználó igényeinek megfelelően szabja meg.
új adattárház architektúrák
az elmúlt években az adattárházak a felhőbe költöznek. Az új felhőalapú adattárházak nem felelnek meg a hagyományos architektúrának; minden adattárház-ajánlat egyedi architektúrával rendelkezik.
ez a rész összefoglalja a két legnépszerűbb felhőalapú raktár architektúráját: az Amazon Redshift és a Google BigQuery.
Amazon Redshift
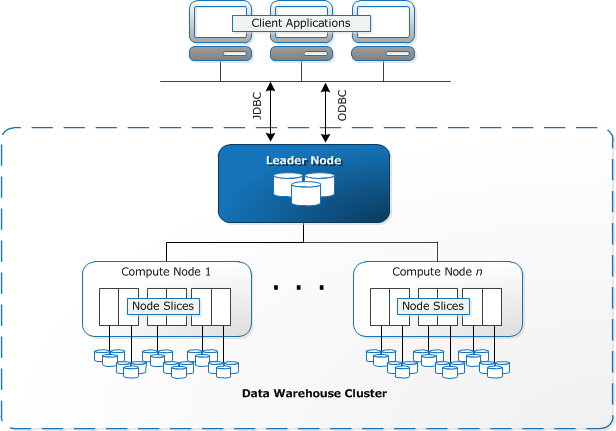
az Amazon Redshift egy hagyományos adattárház felhőalapú ábrázolása.
a Redshift számítási erőforrásokat igényel klaszterek formájában, amelyek egy vagy több csomópont gyűjteményét tartalmazzák. Minden csomópont saját CPU-val, tárolóval és RAM-mal rendelkezik. A leader-csomópont összeállítja a lekérdezéseket, és továbbítja azokat a számítási csomópontoknak, amelyek végrehajtják a lekérdezéseket.
minden csomóponton az adatokat darabokban, szeleteknek nevezik. A Redshift oszlopos tárolót használ, ami azt jelenti, hogy minden adatblokk egyetlen oszlopból származó értékeket tartalmaz számos sorban, egyetlen sor helyett, több oszlop értékeivel.
forrás: AWS dokumentáció
a Redshift MPP architektúrát használ, nagy adathalmazokat bontva darabokra, amelyeket az egyes csomópontokon belüli szeletekhez rendelnek. A lekérdezések gyorsabban teljesítenek, mivel a számítási csomópontok egyszerre dolgozzák fel a lekérdezéseket az egyes szeletekben. A Leader csomópont összesíti az eredményeket, és visszaküldi azokat az ügyfélalkalmazásnak.
az ügyfélalkalmazások, mint például a BI és az elemző eszközök, közvetlenül kapcsolódhatnak a Redshift-hez a nyílt forráskódú PostgreSQL JDBC és ODBC illesztőprogramok segítségével. Az elemzők így közvetlenül a vöröseltolódás adatain végezhetik feladataikat.
a Redshift csak strukturált adatokat képes betölteni. Lehetőség van adatok betöltésére a Redshift-be előre integrált rendszerek segítségével, beleértve az Amazon S3-at és a DynamoDB-t, bármely SSH-kapcsolattal rendelkező helyszíni gazdagépről származó adatok továbbításával, vagy más adatforrások integrálásával a Redshift API segítségével.
Google BigQuery
a BigQuery architektúrája szerver nélküli, vagyis a Google dinamikusan kezeli a gépi erőforrások elosztását. Ezért minden erőforrás-gazdálkodási döntés el van rejtve a felhasználó elől.
a BigQuery lehetővé teszi az ügyfelek számára az adatok betöltését a Google Cloud Storage-ból és más olvasható adatforrásokból. Az alternatív lehetőség az adatfolyam, amely lehetővé teszi a fejlesztők számára, hogy valós időben, soronként adhassanak adatokat az adattárházba, amint elérhetővé válnak.
a BigQuery egy Dremel nevű lekérdezés-végrehajtó motort használ, amely néhány másodperc alatt több milliárd adatsort képes beolvasni. A Dremel masszívan párhuzamos lekérdezést használ az adatok beolvasására az alapul szolgáló Colossus fájlkezelő rendszerben. A Colossus 64 megabájtos darabokra osztja a fájlokat a csomópontok nevű számítási erőforrások között, amelyek fürtökbe vannak csoportosítva.
a Dremel a vöröseltolódáshoz hasonló oszlopos adatstruktúrát használ. A fa architektúra másodpercek alatt több ezer gép között küld lekérdezéseket.
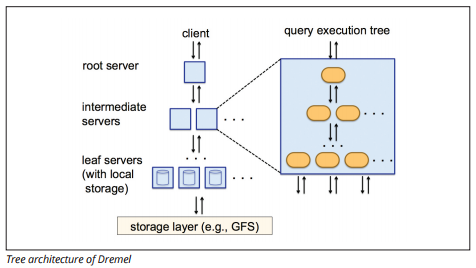
Image source
egyszerű SQL parancsokat használnak az adatok lekérdezésére.
Panoply
a Panoply teljes körű Adatkezelési szolgáltatást nyújt. Egyedülálló önoptimalizáló architektúrája a gépi tanulást és a természetes nyelvfeldolgozást (NLP) használja az adatok forrástól az elemzésig tartó útjának modellezésére és egyszerűsítésére, csökkentve az adatoktól az értékig tartó időt a lehető legközelebb a nullához.
a Panoply intelligens adatinfrastruktúrája a következő funkciókat tartalmazza:
- lekérdezések és adatok elemzése – az egyes használati esetek legjobb konfigurációjának azonosítása, idővel történő beállítása és indexek, sortkeys, diskeys, adattípusok, porszívózás és particionálás.
- olyan lekérdezések azonosítása, amelyek nem követik a bevált gyakorlatokat – például azokat, amelyek beágyazott hurkokat vagy implicit castingot tartalmaznak–, és átírják őket egy egyenértékű lekérdezésre, amely a futási idő vagy az erőforrások töredékét igényli.
- a kiszolgálók konfigurációinak optimalizálása A lekérdezési minták alapján és annak megtanulásával, hogy melyik szerverbeállítás működik a legjobban. A platform zökkenőmentesen váltogatja a kiszolgálótípusokat, és méri a kapott teljesítményt.
a felhőalapú Adattárházakon túl
a felhőalapú adattárházak nagy előrelépést jelentenek a hagyományos architektúrákhoz képest. A felhasználók azonban még mindig számos kihívással néznek szembe a beállításuk során:
- az adatok betöltése a felhő adattárházakba nem triviális, és nagyméretű adatfolyamok esetén az ETL folyamat beállítása, tesztelése és fenntartása szükséges. A folyamat ezen része általában harmadik féltől származó eszközökkel történik.
- a frissítések, frissítések és törlések bonyolultak lehetnek, és gondosan kell elvégezni őket, hogy megakadályozzák a lekérdezés teljesítményének romlását.
- a félig strukturált adatok nehezen kezelhetők-relációs adatbázis formátumba kell normalizálni, amely nagy adatfolyamok automatizálását igényli.
- a beágyazott struktúrák általában nem támogatottak a felhő adattárházakban. A beágyazott táblákat olyan formátumba kell simítania, amelyet az adattárház megért.
- a fürt optimalizálása—különböző lehetőségek állnak rendelkezésre a Redshift fürt beállításához a munkaterhelések futtatásához. A különböző munkaterhelések, adatkészletek vagy akár különböző típusú lekérdezések eltérő beállítást igényelhetnek. Ahhoz, hogy optimális maradjon, folyamatosan újra kell látogatnia és módosítania kell a beállítást.
- Lekérdezésoptimalizálás—előfordulhat, hogy a felhasználói lekérdezések nem követik a legjobb gyakorlatokat, ezért sokkal tovább tart a futtatásuk. Előfordulhat, hogy felhasználókkal vagy automatizált ügyfélalkalmazásokkal dolgozik a lekérdezések optimalizálása érdekében, hogy az adattárház a várt módon teljesíthessen.
- biztonsági mentés és helyreállítás—bár az adattárház-gyártók számos lehetőséget kínálnak az adatok biztonsági mentésére, ezek beállítása nem triviális, és figyelemmel kísérést és szoros figyelmet igényelnek.
a Panoply egy intelligens adattárház, amely olyan automatizálási réteget ad hozzá, amely gondoskodik a fenti összetett feladatokról, értékes időt takarít meg, és segít percek alatt eljutni az adatokból az insightba.
Tudjon meg többet a Panoply intelligens adattárház eszközeiről.
További információ az Adattárházakról
- adattárház fogalmak: hagyományos vs. Felhő
- Adatbázis vs. adattárház
- adattárház vs. adattárház
- Amazon vöröseltolódás architektúra