fie X o variabilă aleatoare reală și fie 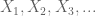
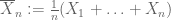
Legea slabă a numărului mare. Să presupunem că primul moment
al lui X este finit. Apoi
converge în probabilitate la
, astfel
pentru fiecare
.
Legea puternică a numărului mare. Să presupunem că primul moment
.
(dacă cineva întărește ipoteza primului moment cu cea a finitudinii celui de-al doilea moment 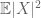
legea slabă este ușor de dovedit, dar legea puternică (care, desigur, implică legea slabă, prin teorema lui Egoroff) este mai subtilă și, de fapt, dovada acestei legi (presupunând doar finitudinea primului moment) apare de obicei doar în textele avansate ale absolvenților. Așa că m-am gândit să prezint aici o dovadă a ambelor legi, care se desfășoară prin tehnicile standard ale metodei momentului și trunchierii. Accentul în această expunere va fi pe motivația și metodele, mai degrabă decât concizie și puterea de rezultate; există dovezi ale legii puternice din literatură care au fost comprimate până la dimensiunea unei pagini sau mai puțin, dar acesta nu este scopul meu aici.
— metoda momentului —
metoda momentului urmărește să controleze probabilitățile cozii unei variabile aleatorii (adică probabilitatea ca aceasta să fluctueze departe de media sa) prin intermediul momentelor și, în special, al zerotului, primul sau al doilea moment. Motivul pentru care această metodă este atât de eficientă este că primele câteva momente pot fi adesea calculate destul de precis. Metoda primului moment folosește de obicei inegalitatea lui Markov
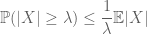
(care urmează luând așteptările inegalității punctuale 

(rețineți că (2) este doar (1) aplicat variabilei aleatoare 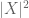

în general vorbind, pentru a calcula primul moment se folosește de obicei liniaritatea așteptărilor

întrucât, pentru a calcula al doilea moment, trebuie să înțelegem și covarianțele( care sunt deosebit de simple dacă se presupune independența perechilor), datorită identităților precum
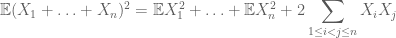
sau varianta normalizată
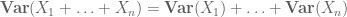

momentele superioare pot oferi, în principiu, informații mai precise, dar necesită adesea ipoteze mai puternice asupra obiectelor studiate, cum ar fi independența comună.
Iată o aplicație de bază a metodei primului moment:
Borel-Cantelli lema. Fie
o secvență de evenimente astfel încât
este finit. Apoi, aproape sigur, doar finit multe dintre evenimentele
sunt adevărate.
dovadă. Fie


închirierea 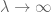

revenind la Legea numerelor mari, prima metodă moment dă următoarea coada legat:
Lema 1. Dacă
este finit, atunci
.
dovadă. Prin inegalitatea triunghiului, 

Lema 1 nu este suficient de puternică de la sine pentru a dovedi legea numerelor mari în formă slabă sau puternică – în special, nu arată nicio îmbunătățire pe măsură ce n devine mare – dar va fi util să se ocupe de unul dintre termenii de eroare din aceste dovezi.
putem obține limite mai puternice decât Lema 1 – în special, limite care se îmbunătățesc cu n – în detrimentul ipotezelor mai puternice asupra X.
Lema 2. Dacă
.
dovadă. Un calcul standard, exploatând (3) și independența perechilor 



în direcția opusă, există metoda momentului zero, mai cunoscută sub numele de legătura Uniunii

sau echivalent (pentru a explica terminologia „moment zero”)

pentru orice variabile aleatoare non-negative 
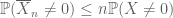
la fel cum al doilea moment legat (Lema 2) este util doar atunci când cineva are un control bun asupra celui de-al doilea moment (sau varianța) lui X, estimarea cozii momentului Zero (3) este utilă numai atunci când avem un control bun asupra momentului zero 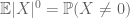
— trunchiere —
al doilea moment legat de coadă (Lema 2) dă deja legea slabă a numerelor mari în cazul în care X are al doilea moment finit (sau echivalent, varianță finită). În general, dacă tot ce știm despre X este că are primul moment finit, atunci nu putem concluziona că X are al doilea moment finit. Cu toate acestea, putem efectua o trunchiere
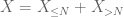
de X la orice prag dorit N, unde 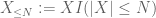

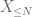
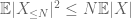
și, prin urmare, avem și varianță finită
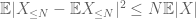
al doilea termen 
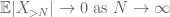
prin inegalitatea triunghiului, concluzionăm că primul termen
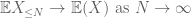
acestea sunt toate instrumentele de care avem nevoie pentru a dovedi legea slabă a numărului mare:
dovada legii slabe. Fie 

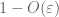
din (7), (8), putem găsi un prag N (în funcție de 
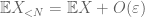

din primul moment legat de coadă (Lema 1), știm că 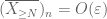
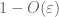
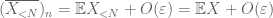
— the strong law –
legea puternică poate fi dovedită prin împingerea metodelor de mai sus un pic mai departe și folosind câteva trucuri.
primul truc este să observăm că pentru a dovedi legea puternică, este suficient să facem acest lucru pentru variabilele aleatorii non-negative 

odată ce X este non-negativ, vedem că mediile empirice

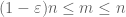
datorită acestei quasimonotonicități, putem sparsifica mulțimea de n pentru care trebuie să dovedim legea puternică. Mai precis, este suficient să arătăm
legea puternică a numărului mare, versiunea redusă. Fie
o variabilă aleatorie non-negativă cu
și fie
o secvență de numere întregi care este lacunară în sensul că
pentru unele
și toate suficient de mari j. apoi
converge aproape sigur la
într-adevăr, dacă am putea dovedi versiunea redusă, apoi pe aplicarea acelei versiuni la secvența lacunară 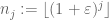


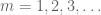
acum că am redus secvența, devine economic să aplicăm lema Borel-Cantelli. Într-adevăr, prin multe aplicații ale acelei Leme vedem că este suficient să arătăm că

pentru X non-negativ al primului moment finit, orice secvență lacunară 
în acest moment ne întoarcem și aplicăm metodele care au funcționat deja pentru a da legea slabă. Și anume, pentru a estima fiecare dintre probabilitățile cozii 
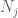
ar trebui cel puțin să alegem 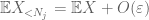


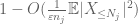

acum ne uităm la contribuția 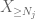
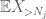
dar există o ultimă carte de jucat, care este metoda momentului zero estimarea cozii (4). Așa cum am menționat mai devreme, această legătură este proastă în general – dar este foarte bună atunci când X este în mare parte zero, ceea ce este tocmai situația cu 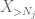


punând toate acestea împreună, vedem că

rezumând acest lucru în j, vedem că vom fi făcuți de îndată ce ne vom da seama cum să alegem
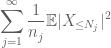
și
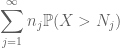
ambele sunt finite. (Ca de obicei, avem un compromis: a face
pe baza discuției anterioare, este firesc să încercați setarea

și
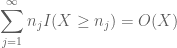
(unde Constanta implicită aici depinde de secvența 
observație 1. Dovada de mai sus arată, de fapt, că legea puternică a numărului mare este valabilă chiar dacă se presupune doar independența pereche a 
remarca 2. Este esențial ca variabilele aleatoare 

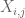
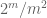
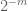



remarca 3. Din perspectiva teoriei interpolării, se poate vedea argumentul de mai sus ca un argument de interpolare, stabilind o estimare 


observație 4. Prin vizualizarea secvenței