Let X be a real-valued random variable, and let 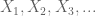
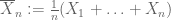
Lei fraca de grandes números. Suponha que o primeiro momento
de X é finito. Em seguida,
converge em probabilidade para
assim
para cada
.
uma lei Forte de grandes números. Suponha que o primeiro momento
.
(Se um fortalece o primeiro momento que a suposição de que da finitude do segundo momento 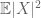
a lei fraca é fácil de provar, mas a lei forte (que, naturalmente, implica a lei fraca, pelo teorema de Egoroff) é mais sutil, e na verdade a prova desta lei (assumindo apenas finitude do primeiro momento) normalmente só aparece em textos avançados de graduação. Então eu pensei que eu iria apresentar uma prova aqui de ambas as leis, que procede pelas técnicas padrão do método do momento e truncamento. A ênfase nesta exposição será na motivação e métodos, em vez de brevidade e força dos resultados; existem provas da lei forte na literatura que foram comprimidas até o tamanho de uma página ou menos, mas este não é o meu objetivo aqui.
o método do momento procura controlar as probabilidades de cauda de uma variável aleatória (ou seja, a probabilidade de que flutua longe da sua média) por meio de momentos, e em particular o zeroth, primeiro ou segundo momento. A razão pela qual este método é tão eficaz é porque os primeiros momentos podem muitas vezes ser computados com bastante precisão. O primeiro momento do método usualmente emprega desigualdade de Markov
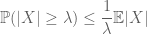
(o que segue tomando expectativas do pointwise desigualdade 

(note que (2) é apenas (1) aplicado à variável aleatória 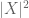

Geral, para calcular o primeiro momento em que usualmente emprega a linearidade da expectativa

considerando que, para calcular o segundo momento, também precisa entender covariâncias (que são particularmente simples, se assume par de independência), graças ao identidades, tais como
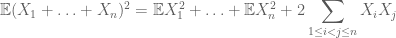
ou normalizado variante
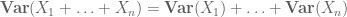

momentos mais altos podem, em princípio, dar informações mais precisas, mas muitas vezes requerem pressupostos mais fortes sobre os objetos em estudo, como a independência conjunta.
aqui está uma aplicação Básica do método do primeiro momento:
Borel-Cantelli lema. Let
be a sequence of events such that
is finite. Então quase certamente, apenas finitamente muitos dos eventos
são verdadeiros.
Proof. Seja 


lema 1. (Primeiro momento cauda dependente) Se
é finito, então
.
Proof. Pela desigualdade triangular, 


Lemma 1 não é suficientemente forte por si só para provar a lei de grandes números em forma fraca ou forte – em particular, não mostra qualquer melhoria à medida que n fica grande – mas será útil para lidar com um dos Termos de erro nessas provas.
we can get stronger bounds than Lemma 1-in particular, bounds which improve with n-at the expense of stronger assumptions on X.
Lemma 2. (Segundo momento cauda dependente) Se
.
Proof. Um padrão de computação, exploração (3) e o par de independência do 



No sentido oposto, há o zeroth momento método, mais comumente conhecida como a união vinculados

ou equivalentemente (para explicar a terminologia “zeroth momento”)

para qualquer não-negativos variáveis aleatórias 
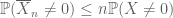
assim como o segundo momento vinculado (Lema 2) só é útil quando se tem um bom controle sobre o segundo momento (ou variância) de X, o zeroth momento cauda estimativa (3) só é útil quando temos um bom controle sobre o zeroth momento 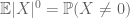
— Truncação —
o segundo momento limite da cauda (lema 2) já dá a lei fraca de números grandes no caso em que X tem segundo momento finito (ou equivalentemente, variância finita). Em geral, se tudo o que se sabe sobre X é que ele tem primeiro momento finito, então não podemos concluir que X tem segundo momento finito. No entanto, podemos realizar um truncamento
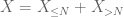
de X em qualquer nível desejado N, onde 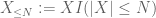

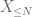
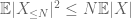
e, portanto, também temos variância finita
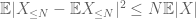
o segundo termo
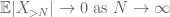
Pelo triângulo desigualdade, podemos concluir que o primeiro termo
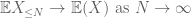
estas são todas as ferramentas que precisamos para provar a lei fraca de grandes números:
prova de lei fraca. Deixe 

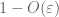
a Partir de (7), (8), podemos encontrar um limite de N (dependendo 
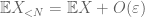

From the first moment tail bound (Lemma 1), we know that 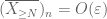
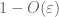
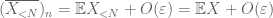
— a lei forte-
a lei forte pode ser provada empurrando os métodos acima um pouco mais, e usando mais alguns truques.
o primeiro truque é observar que para provar a lei forte, basta fazê-lo para variáveis aleatórias não negativas 

uma vez que X não é negativo, vemos que as médias empíricas

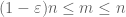
por causa desta quasimonotonicidade, podemos esparsificar o conjunto de n para o qual precisamos provar a lei forte. Mais precisamente, basta mostrar
Lei Forte de grandes números, versão reduzida. Deixe
ser não-negativo variável aleatória com
, e deixe
ser uma sequência de números inteiros, que é lacunary no sentido de que
para alguns
e todos os suficientemente grande j. Em seguida,
converge quase certamente para
de facto, se pudéssemos provar a versão reduzida, então ao aplicar essa versão à sequência lacunar 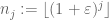


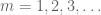

para não negativo X finitos primeiro momento, qualquer lacunary sequência 

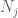
devemos pelo menos escolher 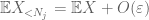


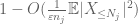

agora olhamos para a contribuição de 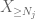
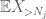
mas há uma última carta a jogar, que é a estimativa de cauda do método do momento zeroth (4). Como mencionado anteriormente, este limite é ruim em geral-mas é muito bom quando X é principalmente zero, que é precisamente a situação com 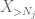


Colocar isso todos juntos, vemos que

Somando isso em j, vemos que vamos ser feito assim que descobrir como escolher
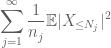
e
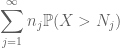
ambos são finitos. (Como de costume, temos um tradeoff: fazer o
Based on the discussion earlier, it is natural to try setting 

e
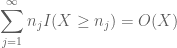
(onde implícita constante aqui depende da sequência n_1, n_2, \ldots, e, em especial, o lacunarity constante c). As reivindicações (10), (11) Em seguida, seguem de uma última aplicação da linearidade da expectativa, dando a lei forte de grandes números.
Observação 1. A prova acima mostra, de fato, que a lei forte de grandes números se mantém mesmo se apenas se assume a independência emparelhada dos 

observação 2. É essencial que as variáveis aleatórias 

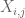
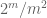
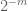



observação 3. Do ponto de vista da teoria da interpolação, pode-se ver o argumento acima como um argumento de interpolação, estabelecendo uma estimativa 


observação 4. Visualizando a sequência