Sea X una variable aleatoria de valor real, y sea 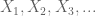
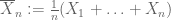
Ley débil de los grandes números. Supongamos que el primer momento
de X es finito. Entonces
converge en probabilidad a
, por lo tanto
para cada
.
Ley fuerte de grandes números. Supongamos que el primer momento
.
(Si uno fortalece la suposición del primer momento a la de finitud del segundo momento 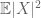
La ley débil es fácil de probar, pero la ley fuerte (que por supuesto implica la ley débil, según el teorema de Egoroff) es más sutil, y de hecho la prueba de esta ley (asumiendo solo la finitud del primer momento) generalmente solo aparece en textos de posgrado avanzados. Así que pensé en presentar aquí una prueba de ambas leyes, que procede por las técnicas estándar del método del momento y el truncamiento. El énfasis en esta exposición estará en la motivación y los métodos en lugar de la brevedad y la fuerza de los resultados; existen pruebas de la ley fuerte en la literatura que han sido comprimidas hasta el tamaño de una página o menos, pero este no es mi objetivo aquí.
– El método del momento –
El método del momento busca controlar las probabilidades de cola de una variable aleatoria (es decir, la probabilidad de que fluctúe lejos de su media) por medio de momentos, y en particular el cero, el primer o segundo momento. La razón por la que este método es tan efectivo es porque los primeros momentos a menudo se pueden calcular con bastante precisión. El método del primer momento suele emplear la desigualdad de Markov
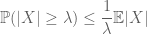
(que sigue tomando las expectativas de la desigualdad puntual 

(tenga en cuenta que (2) es solo (1) aplicado a la variable aleatoria 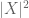

En términos generales, para calcular el primer momento se suele emplear la linealidad de las expectativas

mientras que para calcular el segundo momento uno también necesita entender las covarianzas (que son particularmente simples si uno asume la independencia de pares), gracias a identidades como
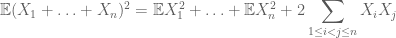
o la variante normalizada
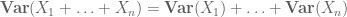

Los momentos más altos pueden, en principio, proporcionar información más precisa, pero a menudo requieren suposiciones más sólidas sobre los objetos que se estudian, como la independencia de las articulaciones.
Aquí hay una aplicación básica del método del primer momento:
Lema Borel-Cantelli. Sea
una secuencia de eventos tales que
es finito. Entonces, casi seguramente, solo muchos de los eventos
son verdaderos.
Prueba. Let 


Dejando 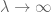

Volviendo a la ley de los números grandes, el método del primer momento da el siguiente límite de cola:
Lema 1. (Primer momento de la cola enlazada) Si
es finito, entonces
.
Prueba. Por la desigualdad de triángulo, 

El Lema 1 no es lo suficientemente fuerte por sí solo para probar la ley de los números grandes en forma débil o fuerte, en particular, no muestra ninguna mejora ya que n se vuelve grande, pero será útil manejar uno de los términos de error en esas pruebas.
Podemos obtener límites más fuertes que el Lema 1, en particular, límites que mejoran con n, a expensas de suposiciones más fuertes en X.
Lema 2. (Segundo momento de la cola enlazada) Si
.
Prueba. Un cálculo estándar, explotando (3) y la independencia de pares de 



En la dirección opuesta, no es el momento cero de método, más comúnmente conocido como la unión vinculados

o, equivalentemente, (para explicar la terminología de «momento cero»)

para cualquier valor no negativo variables aleatorias 
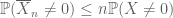
Así como el segundo momento limitado (Lema 2) solo es útil cuando uno tiene un buen control del segundo momento (o varianza) de X, la estimación de cola del momento cero(3) solo es útil cuando tenemos un buen control del momento cero 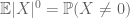
El límite de cola del segundo momento (Lema 2) ya da la ley débil de números grandes en el caso de que X tenga un segundo momento finito (o, de forma equivalente, varianza finita). En general, si todo lo que uno sabe sobre X es que tiene un primer momento finito, entonces no podemos concluir que X tiene un segundo momento finito. Sin embargo, se puede realizar un truncamiento
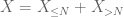
de X en cualquier umbral deseado N, donde 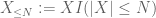

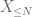
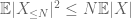
y de ahí también tenemos varianza finita
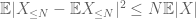
El segundo término 
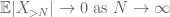
Por la desigualdad triangular, concluimos que el primer término
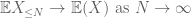
Estas son todas las herramientas que necesitamos para probar la ley débil de los grandes números:
Prueba de la ley débil. Let 

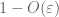
De (7), (8), podemos encontrar un umbral N (dependiendo de 
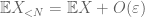

Desde el primer momento del límite de cola (Lema 1), sabemos que 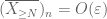
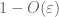
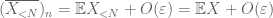
— La ley fuerte –
La ley fuerte se puede probar empujando los métodos anteriores un poco más lejos y usando algunos trucos más.
El primer truco es observar que para probar la ley fuerte, es suficiente hacerlo para variables aleatorias no negativas 

Una vez que X no es negativo, vemos que los promedios empíricos

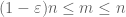
Debido a esta cuasimonotonía, podemos dispersar el conjunto de n para el que necesitamos probar la ley fuerte. Más precisamente, basta con mostrar
Ley fuerte de números grandes, versión reducida. Sea
una variable aleatoria no negativa con
, y sea
una secuencia de enteros que es lacunar en el sentido de que
para algunos
y todo lo suficientemente grande j. Entonces
converge casi seguramente a
De hecho, si pudiéramos probar la versión reducida, al aplicar esa versión a la secuencia lacunaria 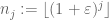


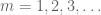
Ahora que hemos reducido la secuencia, resulta económico aplicar el lema Borel-Cantelli. De hecho, por muchas aplicaciones de ese lema vemos que basta con demostrar que

para X no negativo de primer momento finito, cualquier secuencia lacunar 
En este punto volvemos atrás y aplicamos los métodos que ya funcionaron para dar la ley débil. Es decir, para estimar cada una de las probabilidades de cola 
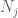
Al menos debemos elegir 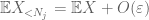


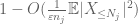

Ahora vemos la contribución de 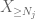
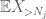
Pero hay una última carta para jugar, que es la estimación de cola del método del momento cero (4). Como se mencionó anteriormente, este límite es pésimo en general, pero es muy bueno cuando X es casi cero, que es precisamente la situación con 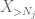


Poniendo todo esto en conjunto, vemos que

Sumar esta en j, vemos que se hará tan pronto como podemos averiguar cómo elegir
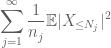
y
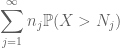
ambos son finitos. (Como de costumbre, tenemos un compromiso: hacer que
Basado en la discusión anterior, es natural intentar establecer 

y
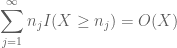
(donde la constante implícita aquí depende de la secuencia 
Observación 1. La prueba anterior, de hecho, muestra que la fuerte ley de los grandes números se mantiene incluso si solo se asume la independencia en parejas de 

Observación 2. Es esencial que las variables aleatorias 

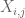
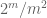
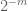



Observación 3. Desde la perspectiva de la teoría de interpolación, se puede ver el argumento anterior como un argumento de interpolación, estableciendo una estimación 


Observación 4. Al ver la secuencia