Sei X eine reellwertige Zufallsvariable und sei 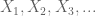
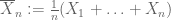
Schwaches Gesetz der großen Zahlen. Angenommen, das erste Moment
von X ist endlich. Dann konvergiert
in der Wahrscheinlichkeit zu
, also
für jeden
.
Starkes Gesetz der großen Zahlen. Angenommen, das erste Moment
.
( Wenn man die Annahme des ersten Moments auf die der Endlichkeit des zweiten Moments 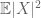
Das schwache Gesetz ist leicht zu beweisen, aber das starke Gesetz (was natürlich das schwache Gesetz nach Egoroffs Theorem impliziert) ist subtiler, und tatsächlich erscheint der Beweis dieses Gesetzes (unter der Annahme der Endlichkeit des ersten Moments) normalerweise nur in fortgeschrittenen Graduiertentexten. Also dachte ich, ich würde hier einen Beweis für beide Gesetze vorlegen, der mit den Standardtechniken der Moment-Methode und der Trunkierung vorgeht. Der Schwerpunkt dieser Ausstellung liegt eher auf Motivation und Methoden als auf Kürze und Stärke der Ergebnisse; es gibt Beweise für das starke Gesetz in der Literatur, die auf die Größe einer Seite oder weniger komprimiert wurden, aber das ist hier nicht mein Ziel.
– Die Momentmethode –
Die Momentmethode versucht, die Schwanzwahrscheinlichkeiten einer Zufallsvariablen (d. H. Die Wahrscheinlichkeit, dass sie weit von ihrem Mittelwert abweicht) durch Momente und insbesondere das nullte, erste oder zweite Moment zu steuern. Der Grund, warum diese Methode so effektiv ist, liegt darin, dass die ersten Momente oft ziemlich genau berechnet werden können. Die Methode des ersten Moments verwendet normalerweise die Markovsche Ungleichung
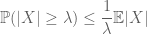
( was folgt, indem die Erwartungen der punktweisen Ungleichung 

( beachten Sie, dass (2) nur (1) auf die Zufallsvariable 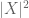

Im Allgemeinen verwendet man zur Berechnung des ersten Moments normalerweise die Linearität der Erwartung

während man zur Berechnung des zweiten Moments auch Kovarianzen verstehen muss (die besonders einfach sind, wenn man paarweise Unabhängigkeit annimmt), dank Identitäten wie
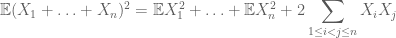
oder die normalisierte Variante
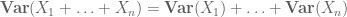

Höhere Momente können im Prinzip genauere Informationen liefern, erfordern jedoch häufig stärkere Annahmen über die untersuchten Objekte, wie z. B. gemeinsame Unabhängigkeit.
Hier ist eine grundlegende Anwendung der First Moment-Methode:
Borel-Cantelli-Lemma. Sei
eine Folge von Ereignissen, so dass
endlich ist. Dann sind fast sicher nur endlich viele der Ereignisse
wahr.
Beweis. Sei 


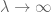

Zurück zum Gesetz der großen Zahlen ergibt die Methode des ersten Moments die folgende Schwanzgrenze:
Lemma 1. (Erster Moment schwanzgebunden) Wenn
endlich ist, dann
.
Beweis. Durch die Dreiecksungleichung 

Lemma 1 ist an sich nicht stark genug, um das Gesetz der großen Zahlen entweder in schwacher oder starker Form zu beweisen – insbesondere zeigt es keine Verbesserung, wenn n groß wird – aber es wird nützlich sein, einen der Fehlerterme in diesen Beweisen zu behandeln.
Wir können stärkere Grenzen als Lemma 1 erhalten – insbesondere Grenzen, die sich mit n verbessern – auf Kosten stärkerer Annahmen über X.
Lemma 2. (Zweiter Moment schwanzgebunden) Wenn
.
Beweis. Eine Standardberechnung unter Verwendung von (3) und der paarweisen Unabhängigkeit von 



In der entgegengesetzten Richtung gibt es die Nullpunktmethode, besser bekannt als Union Bound

oder äquivalent (um die Terminologie „nulliger Moment“ zu erklären“)

für alle nicht negativen Zufallsvariablen 
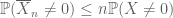
So wie die zweite Momentgrenze (Lemma 2) nur dann nützlich ist, wenn man das zweite Moment (oder die Varianz) von X gut kontrollieren kann, ist die nullte Momentschwanzschätzung (3) nur dann nützlich, wenn wir eine gute Kontrolle über das nullte Moment haben 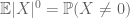
– Trunkierung –
Das zweite Moment schwanzgebunden (Lemma 2) gibt bereits das schwache Gesetz der großen Zahlen in dem Fall, wenn X endliches zweites Moment hat (oder äquivalent endliche Varianz). Im Allgemeinen, wenn alles, was man über X weiß, ist, dass es ein endliches erstes Moment hat, dann können wir nicht schließen, dass X ein endliches zweites Moment hat. Wir können jedoch eine Kürzung durchführen
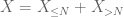
von X an einer beliebigen Schwelle N, wobei 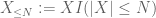

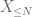
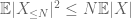
und daher haben wir auch endliche Varianz
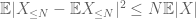
Der zweite Term 
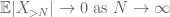
Durch die Dreiecksungleichung schließen wir, dass der erste Term
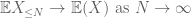
Dies sind alle Werkzeuge, die wir brauchen, um das schwache Gesetz der großen Zahlen zu beweisen:
Beweis des schwachen Gesetzes. Sei 

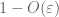
Aus (7), (8)können wir einen Schwellenwert N (abhängig von 
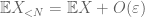

Vom ersten Moment an schwanzgebunden (Lemma 1) wissen wir, dass 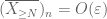
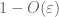
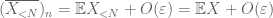
— Das starke Gesetz –
Das starke Gesetz kann bewiesen werden, indem die obigen Methoden ein wenig weiter vorangetrieben und ein paar weitere Tricks angewendet werden.
Der erste Trick besteht darin, zu beachten, dass es zum Beweis des starken Gesetzes ausreicht, dies für nicht negative Zufallsvariablen 

Sobald X nicht negativ ist, sehen wir, dass die empirischen Mittelwerte

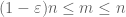
Aufgrund dieser Quasimonotonizität können wir die Menge von n, für die wir das starke Gesetz beweisen müssen, sparsifizieren. Genauer gesagt genügt es,
Starkes Gesetz der großen Zahlen, reduzierte Version zu zeigen. Sei
eine nicht negative Zufallsvariable mit
, und sei
eine Folge von ganzen Zahlen, die in dem Sinne lakunar ist, dass
für einige
und alle ausreichend großen j. Dann konvergiert
fast sicher zu
In der Tat, wenn wir die reduzierte Version beweisen könnten, dann bei der Anwendung dieser Version auf die lakunare Sequenz 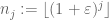


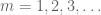
Nun, da wir die Sequenz sparsifiziert haben, wird es wirtschaftlich, das Borel-Cantelli-Lemma anzuwenden. In der Tat sehen wir durch viele Anwendungen dieses Lemmas, dass es ausreicht, dies zu zeigen

für nicht negatives X des endlichen ersten Moments jede lakunare Sequenz 
An dieser Stelle gehen wir zurück und wenden die Methoden an, die bereits funktionierten, um das schwache Gesetz zu geben. Um nämlich jede der Schwanzwahrscheinlichkeiten 
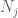
Wir sollten mindestens 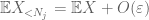


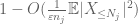

Nun betrachten wir den Beitrag von 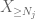
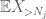
Aber es gibt noch eine letzte Karte zu spielen, nämlich die Nullpunktmethode tail estimate (4). Wie bereits erwähnt, ist diese Grenze im Allgemeinen lausig – aber sehr gut, wenn X größtenteils Null ist, was genau die Situation mit 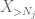


Wenn wir das alles zusammenfassen, sehen wir, dass

Wenn wir dies in j zusammenfassen, sehen wir, dass wir fertig sind, sobald wir herausfinden, wie man
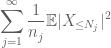
und
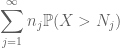
beide sind endlich. (Wie üblich haben wir einen Kompromiss: Wenn wir
Basierend auf der vorherigen Diskussion ist es natürlich zu versuchen, 

und
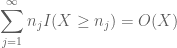
( wobei die implizite Konstante hier von der Folge 
Bemerkung 1. Der obige Beweis zeigt in der Tat, dass das starke Gesetz der großen Zahlen gilt, auch wenn man nur paarweise Unabhängigkeit der 

Bemerkung 2. Es ist wichtig, dass die Zufallsvariablen 

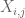
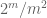
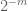



Bemerkung 3. Aus der Perspektive der Interpolationstheorie kann man das obige Argument als Interpolationsargument betrachten, das eine 


Bemerkung 4. Betrachtet man die Folge