La X være en reell verdi tilfeldig variabel, og la 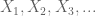
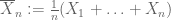
Svak lov av store tall. Anta at det første øyeblikket
Av X er endelig. Så
konvergerer i sannsynlighet til
, dermed
for hver
.
Sterk lov av store tall. Anta at det første øyeblikket
.
(hvis man styrker det første øyeblikkets antagelse til det endelige av det andre øyeblikket 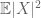
den svake loven er lett å bevise, men den sterke loven (som selvfølgelig innebærer den svake loven, Ved Egoroffs teorem) er mer subtil, og faktisk er beviset på denne loven (forutsatt bare finitet i første øyeblikk) vanligvis bare vises i avanserte graduate tekster. Så jeg tenkte jeg ville presentere et bevis her av begge lover, som fortsetter ved standard teknikker for øyeblikket metode og avkorting. Hovedvekten i denne utstillingen vil være på motivasjon og metoder i stedet for kortfattethet og styrke av resultater; det finnes bevis på den sterke loven i litteraturen som har blitt komprimert ned til størrelsen på en side eller mindre, men dette er ikke mitt mål her.
— moment —metoden –
moment-metoden søker å kontrollere halesannsynlighetene for en tilfeldig variabel (dvs. sannsynligheten for at den svinger langt fra gjennomsnittet) ved hjelp av øyeblikk, og spesielt null, første eller andre øyeblikk. Grunnen til at denne metoden er så effektiv er fordi de første øyeblikkene ofte kan beregnes ganske nøyaktig. Første øyeblikksmetoden bruker Vanligvis markovs ulikhet
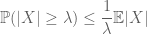
(som følger ved å ta forventninger til punktvis ulikhet 

(merk at (2) bare er (1) brukt på den tilfeldige variabelen 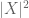

Generelt sett, for å beregne det første øyeblikket bruker man vanligvis linearitet av forventning

mens for å beregne det andre øyeblikket må man også forstå kovarianser (som er spesielt enkle hvis man antar parvis uavhengighet), takket være identiteter som
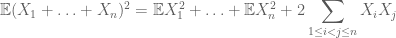
eller den normaliserte varianten
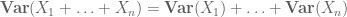

Høyere momenter kan i prinsippet gi mer presis informasjon, men krever ofte sterkere forutsetninger om objektene som studeres, for eksempel felles uavhengighet.
her er en grunnleggende anvendelse av first moment-metoden:
Borel-Cantelli lemma. La
være en sekvens av hendelser slik at
er endelig. Så nesten sikkert, bare endelig mange av hendelsene
er sanne.
Bevis. La 


La 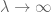

Tilbake til loven om store tall, gir første øyeblikk metoden følgende hale bundet:
Lemma 1. (Første øyeblikk hale bundet) Hvis
er endelig, da
.
Bevis. Ved trekanten ulikhet, 

Lemma 1 er ikke sterk nok i seg selv til å bevise loven om store tall i enten svak eller sterk form – spesielt viser den ingen forbedring ettersom n blir stor-men det vil være nyttig å håndtere en av feilbetingelsene i disse bevisene.
vi kan få sterkere grenser enn Lemma 1-spesielt grenser som forbedrer med n-på bekostning av sterkere forutsetninger På X.
Lemma 2. (Andre øyeblikk hale bundet) Hvis
.
Bevis. En standardberegning, som utnytter (3) og parvis uavhengighet av 



i motsatt retning er det zeroth moment-metoden, mer kjent som union bound

eller tilsvarende (for å forklare terminologien «zeroth moment»)

for ikke-negative tilfeldige variabler 
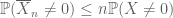
Akkurat som det andre øyeblikket bundet (Lemma 2) er bare nyttig når man har god kontroll på Det Andre øyeblikket (eller variansen) Av X, er zeroth moment tail estimate (3) bare nyttig når Vi har god kontroll på zeroth moment 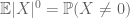
det andre moment tail bound (Lemma 2) gir allerede den svake loven om store tall i tilfelle Når X har endelig sekundmoment (eller ekvivalent, endelig varians). Generelt, hvis Alt man vet Om X er At Det har endelig første øyeblikk, så kan Vi ikke konkludere Med At X har endelig andre øyeblikk. Vi kan imidlertid utføre en avkorting
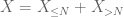
av X ved ønsket terskel N, hvor 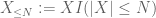

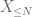
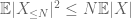
og derfor har vi også endelig varians
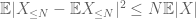
den andre termen 
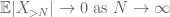
ved triangle inequality konkluderer vi at den første termen
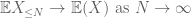
Dette er alle verktøyene vi trenger for å bevise den svake loven av store tall:
Bevis på svak lov. La 

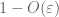
fra (7), (8) kan vi finne en terskel N (avhengig av 
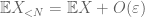

fra første øyeblikk hale bundet (Lemma 1), vet vi at 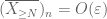
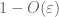
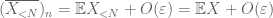
— den sterke loven –
den sterke loven kan bevises ved å skyve metodene ovenfor litt lenger, og bruke noen flere triks.
det første trikset er å observere at for å bevise den sterke loven, er det nok å gjøre det for ikke-negative tilfeldige variabler 

Når X Ikke er negativ, ser Vi at det empiriske gjennomsnittet

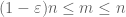
på grunn av denne kvasimonotoniciteten kan vi sparsify settet av n som vi trenger for å bevise den sterke loven. Mer presist er det nok å vise
Sterk lov med store tall, redusert versjon. La
være en ikke-negativ tilfeldig variabel med
, og la
være en sekvens av heltall som er lakunære i den forstand at
for noen
og alle tilstrekkelig store j. deretter
konvergerer nesten sikkert til
Faktisk, Hvis vi kunne bevise den reduserte versjonen, så på å bruke den versjonen til lacunary sekvensen 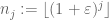


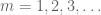
Nå som vi har sparsified sekvensen, blir det økonomisk å bruke Borel-Cantelli lemma. Faktisk, ved mange applikasjoner av det lemma ser vi at det er nok å vise det

for ikke-negativ X av endelig første øyeblikk, noen lacunary sekvens 
På dette punktet går vi tilbake og bruker metodene som allerede jobbet for å gi den svake loven. Nemlig, for å estimere hver av halesannsynlighetene 
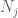
Vi bør i det minste velge 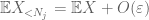


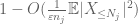

nå ser Vi på bidraget til 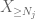
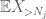
Men det er ett siste kort å spille, som er zeroth moment method tail estimate (4). Som nevnt tidligere er denne bundet elendig generelt – men er veldig bra Når X er stort sett null, noe som nettopp er situasjonen med 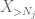


å Sette alt dette sammen, ser vi at

Oppsummering av dette i j, ser vi at vi vil bli gjort så snart vi finner ut hvordan vi velger
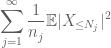
og
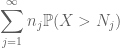
begge er endelige. (Som vanlig har vi en bytte: å gjøre
basert på tidligere diskusjon er det naturlig å prøve å sette 

og
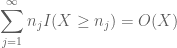
(hvor den underforståtte konstanten her avhenger av sekvensen 
Bemerkning 1. Ovennevnte bevis viser faktisk at den sterke loven om store tall holder selv om man bare antar parvis uavhengighet av 

Bemerkning 2. Det er viktig at de tilfeldige variablene 

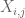
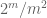
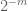



Bemerkning 3. Fra interpolasjonsteoriens perspektiv kan man se argumentet ovenfor som et interpoleringsargument, og etablere et 


Bemerkning 4. Ved å se sekvensen