et datalager er et elektronisk system som samler data fra et bredt spekter av kilder i et selskap og bruker dataene til å støtte ledelsesbeslutninger.
Bedrifter beveger seg i økende grad mot skybaserte datalagre i stedet for tradisjonelle on-premise systemer. Skybaserte datalager skiller seg fra tradisjonelle varehus på følgende måter:
- det er ikke nødvendig å kjøpe fysisk maskinvare.
- det er raskere og billigere å sette opp og skalere skylagre.
- Skybaserte datalagerarkitekturer kan vanligvis utføre komplekse analytiske spørringer mye raskere fordi de bruker mpp (massively parallel processing).
resten av denne artikkelen dekker tradisjonell datalagerarkitektur og introduserer noen arkitektoniske ideer og konsepter som brukes av de mest populære skybaserte datalagertjenestene.
for mer informasjon, se vår side om datavarehuskonsepter i denne veiledningen.
Tradisjonell Datalagerarkitektur
følgende konsepter fremhever noen av de etablerte ideene og designprinsippene som brukes til å bygge tradisjonelle datalagre.
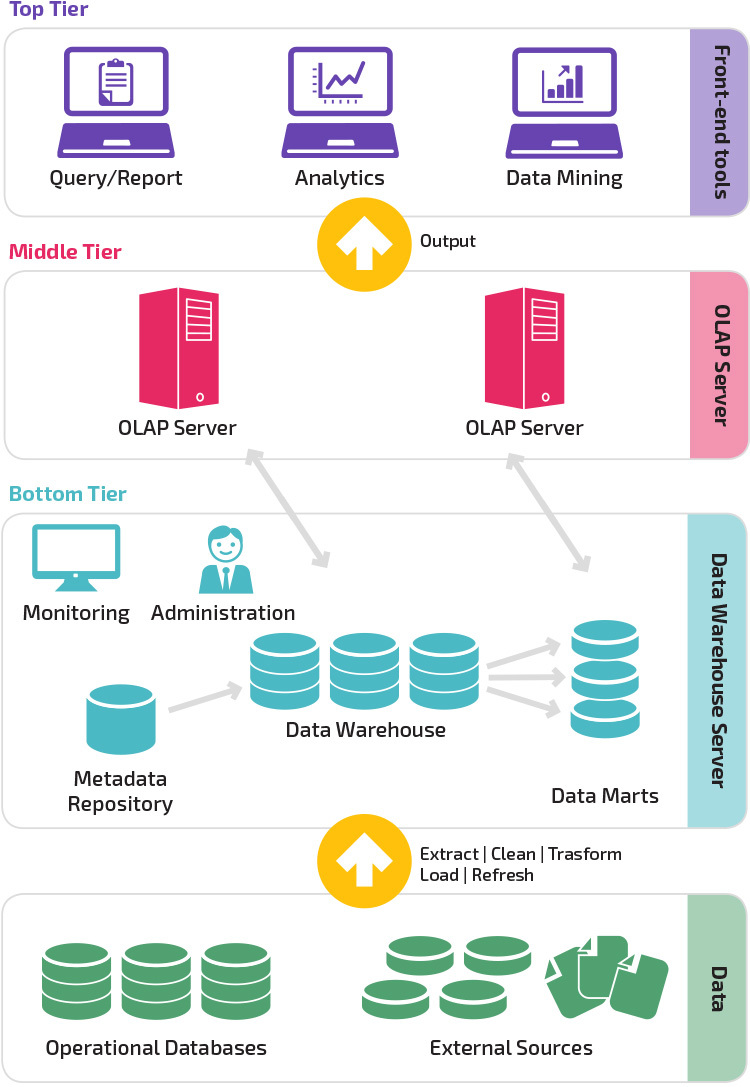
Tre-Lags Arkitektur
Tradisjonell datalagerarkitektur benytter en tre-lags struktur bestående av følgende nivåer.
- Nederste nivå: dette nivået inneholder databaseserveren som brukes til å trekke ut data fra mange forskjellige kilder, for eksempel fra transaksjonsdatabaser som brukes til frontprogrammer.
- Mellomnivå: Den midterste tier huser EN OLAP-server, som forvandler dataene til en struktur bedre egnet for analyse og komplekse spørring. OLAP-serveren kan fungere på to måter: enten som et utvidet relasjonsdatabasebehandlingssystem som kartlegger operasjonene på flerdimensjonale data til Standard relasjonelle OPERASJONER (Relasjonelle OLAP), eller ved hjelp av en flerdimensjonal OLAP-modell som direkte implementerer flerdimensjonale data og operasjoner.
- Øverste nivå: det øverste nivået er klientlaget. Dette nivået inneholder verktøyene som brukes til dataanalyse på høyt nivå, spørringsrapportering og datautvinning.
Kimball vs. Inmon
To pionerer innen datalagring Kalt Bill Inmon og Ralph Kimball hadde forskjellige tilnærminger til datalagerdesign.
Ralph Kimballs tilnærming understreket betydningen av data marts, som er lagre av data som tilhører bestemte bransjer. Datalageret er ganske enkelt en kombinasjon av ulike datamarter som forenkler rapportering og analyse. Kimball data warehouse design bruker en» bottom-up » tilnærming.
Bill Inmon betraktet datalageret som det sentraliserte depotet for alle bedriftsdata. I denne tilnærmingen oppretter en organisasjon først en normalisert datavarehus modell. Dimensjonsdata marts blir deretter opprettet basert på lagermodellen. Dette er kjent som en top-down tilnærming til datavarehus.
Datalagermodeller
i en tradisjonell arkitektur finnes det tre vanlige datalagermodeller: virtuelt lager, data mart og enterprise data warehouse:
- et virtuelt datalager er et sett med separate databaser, som kan spørres sammen, slik at en bruker effektivt kan få tilgang til alle dataene som om de var lagret i ett datalager.
- en data mart-modell brukes til forretningslinjespesifikk rapportering og analyse. I denne datavarehusmodellen samles data fra en rekke kildesystemer som er relevante for et bestemt forretningsområde, for eksempel salg eller økonomi.
- en enterprise data warehouse-modell foreskriver at datalageret inneholder aggregerte data som spenner over hele organisasjonen. Denne modellen ser datavarehuset som hjertet i foretakets informasjonssystem, med integrerte data fra alle forretningsenheter.
Stjerneskjema vs. Snowflake-Skjema
stjerneskjemaet og snowflake-skjemaet er to måter å strukturere et datalager på.
stjerneskjemaet har et sentralisert datalager, lagret i en faktatabell. Skjemaet deler faktatabellen i en serie av denormaliserte dimensjonstabeller. Faktatabellen inneholder aggregerte data som skal brukes til rapporteringsformål, mens dimensjonstabellen beskriver de lagrede dataene.
Denormaliserte design er mindre komplekse fordi dataene er gruppert. Faktatabellen bruker bare en kobling for å bli med i hver dimensjonstabell. Stjerneskjemaets enklere design gjør det mye enklere å skrive komplekse spørringer.
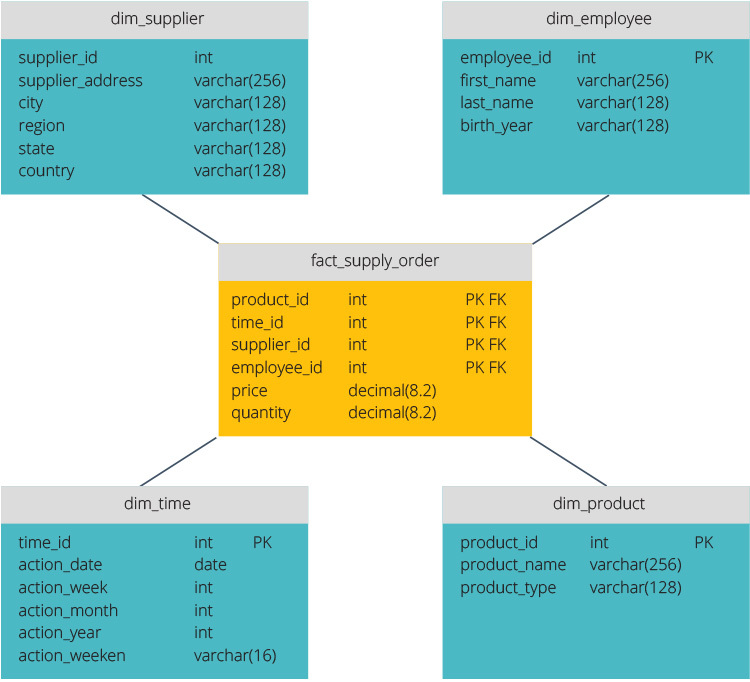
snowflake-skjemaet er annerledes fordi det normaliserer dataene. Normalisering betyr effektiv organisering av dataene slik at alle dataavhengigheter er definert, og hver tabell inneholder minimal redundans. Enkeltdimensjonstabeller forgrener seg dermed til separate dimensjonstabeller.
snowflake-skjemaet bruker mindre diskplass og bevarer dataintegriteten bedre. Den største ulempen er kompleksiteten til spørringer som kreves for å få tilgang til data – hver spørring må grave dypt for å komme til de relevante dataene fordi det er flere koblinger.
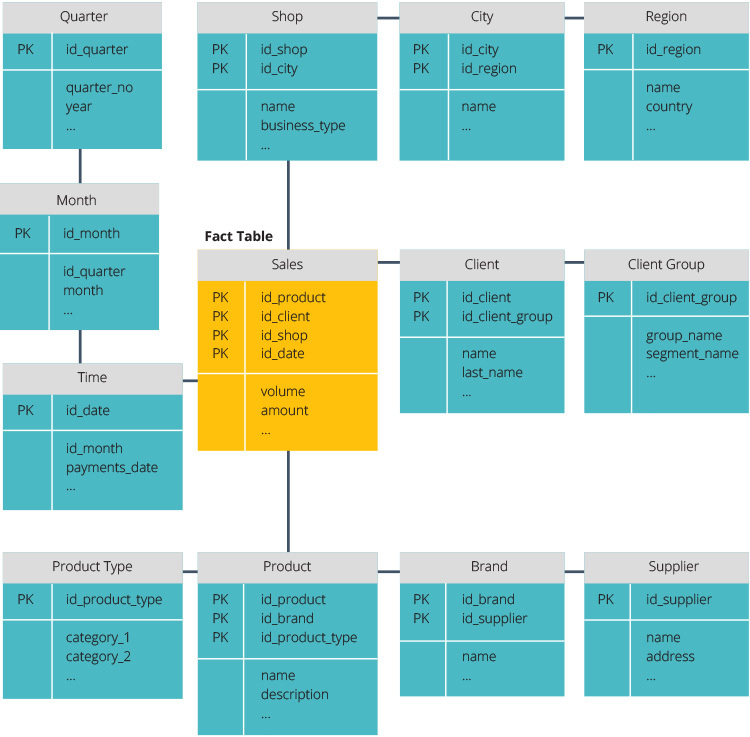
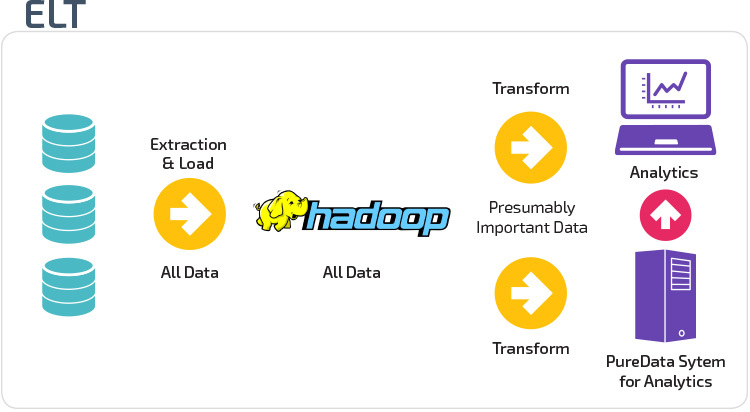
ETL vs ELT
ETL og ELT er to forskjellige metoder for å laste data inn i et lager.
Pakk ut, Transform, Load (ETL) trekker først ut dataene fra et utvalg av datakilder, som vanligvis er transaksjonsdatabaser. Dataene lagres i en midlertidig iscenesettelsesdatabase. Transformasjonsoperasjoner utføres deretter for å strukturere og konvertere dataene til en egnet form for måldatalagersystemet. De strukturerte dataene lastes deretter inn i lageret, klar for analyse.
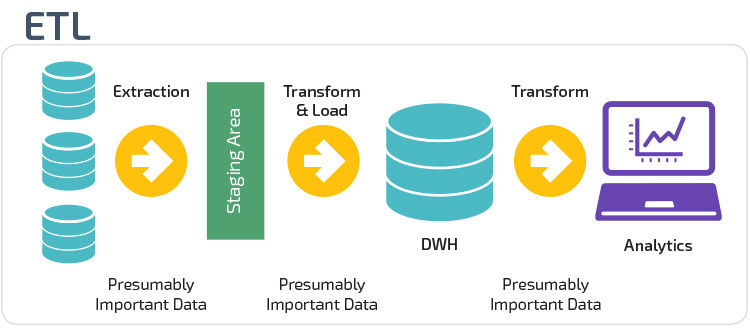
Med EXTRACT Load Transform (ELT) lastes data umiddelbart etter at de er hentet fra kildedatabassenger. Det er ingen staging database, noe som betyr at dataene umiddelbart lastes inn i det enkle, sentraliserte depotet. Dataene transformeres inne i datalagersystemet for bruk med business intelligence-verktøy og analyser.
Organisatorisk Modenhet
strukturen til en organisasjons datalager avhenger også av den nåværende situasjonen og behovene.
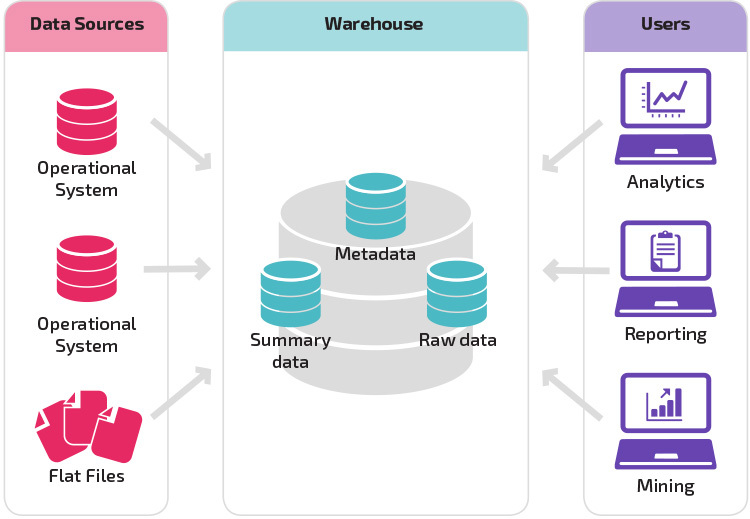
den grunnleggende strukturen lar sluttbrukere av lageret få direkte tilgang til sammendragsdata avledet fra kildesystemer og utføre analyse, rapportering og gruvedrift på disse dataene. Denne strukturen er nyttig når datakilder stammer fra de samme typene databasesystemer.
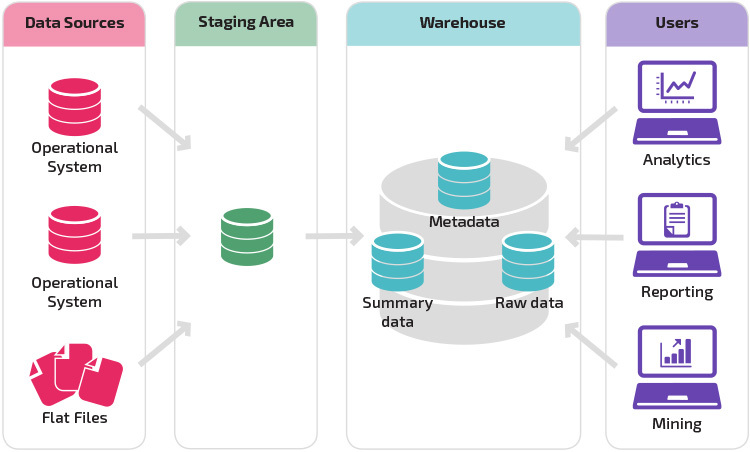
et lager med et oppsamlingsområde er det neste logiske trinnet i en organisasjon med ulike datakilder med mange forskjellige typer og formater av data. Oppsettingsområdet konverterer dataene til et oppsummert strukturert format som er enklere å spørre etter med analyse – og rapporteringsverktøy.
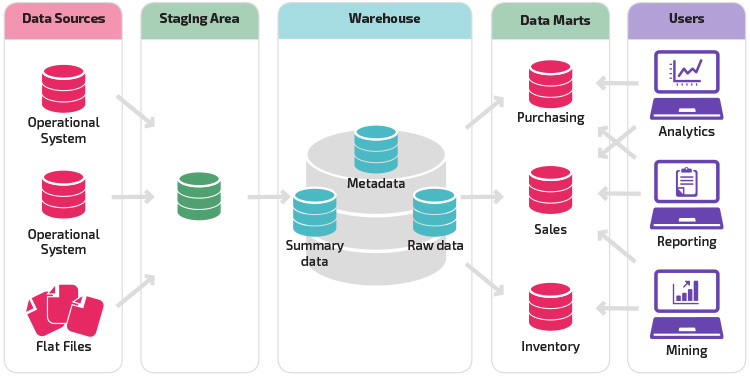
en variasjon på staging strukturen er tillegg av data marts til datalageret. Data marts lagrer oppsummerte data for en bestemt bransje, noe som gjør dataene lett tilgjengelige for bestemte analyseformer. Hvis du for eksempel legger til data marts, kan en finansanalytiker lettere utføre detaljerte spørringer om salgsdata, for å gjøre spådommer om kundeatferd. Data marts gjør analysen enklere ved å skreddersy data spesielt for å møte behovene til sluttbrukeren.
Nye Datavarehusarkitekturer
de siste årene har datavarehusene flyttet til skyen. De nye skybaserte datavarehusene overholder ikke den tradisjonelle arkitekturen; hvert datavarehustilbud har en unik arkitektur.
denne delen oppsummerer arkitekturene som brukes av to av De mest populære skybaserte lagrene: Amazon Redshift og Google BigQuery.
Amazon Redshift
Amazon Redshift Er en skybasert representasjon av et tradisjonelt datalager.
Redshift krever at databehandlingsressurser klargjøres og konfigureres i form av klynger, som inneholder en samling av en eller flere noder. Hver node har SIN EGEN CPU, lagring OG RAM. En leder node kompilerer spørringer og overfører dem til beregne noder, som utfører spørringene.
på hver node lagres data i biter, kalt skiver. Redshift bruker en kolonnelagring, noe som betyr at hver blokk med data inneholder verdier fra en enkelt kolonne over et antall rader, i stedet for en enkelt rad med verdier fra flere kolonner.
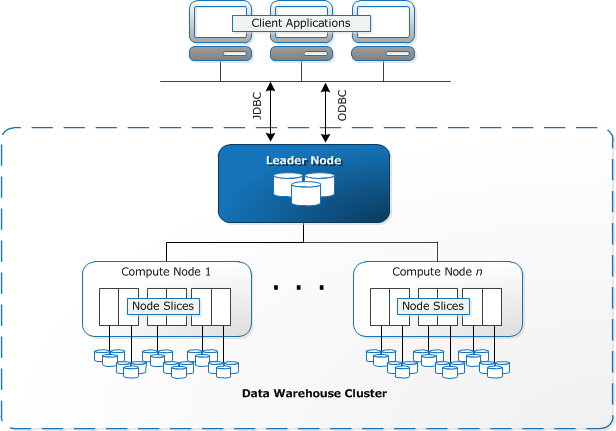
KILDE: AWS Documentation
Redshift bruker EN MPP-arkitektur, som bryter opp store datasett i biter som er tildelt skiver i hver node. Spørringer utføre raskere fordi beregne noder behandle spørringer i hver skive samtidig. Leder-Noden samler resultatene og returnerer dem til klientprogrammet.
Klientprogrammer, FOR EKSEMPEL BI og analyseverktøy, kan koble Direkte til Redshift ved hjelp av open source PostgreSQL jdbc og ODBC-drivere. Analytikere kan dermed utføre sine oppgaver direkte på Redshift data.
Redshift kan bare laste strukturerte data. Det er mulig å laste data Til Redshift ved hjelp av forhåndsintegrerte systemer, inkludert Amazon S3 og DynamoDB, ved å skyve data fra en hvilken som helst lokal vert med SSH-tilkobling, eller ved å integrere andre datakilder ved Hjelp Av Redshift API.
Google BigQuery
Bigquerys arkitektur er serverløs, noe Som betyr At Google administrerer dynamisk allokering av maskinressurser. Alle ressursforvaltningsbeslutninger er derfor skjult for brukeren.
BigQuery lar klienter laste inn data fra Google Cloud Storage og andre lesbare datakilder. Alternativet er å streame data, noe som gjør det mulig for utviklere å legge til data i datalageret i sanntid, rad for rad, etter hvert som det blir tilgjengelig.
BigQuery bruker en søkekjøringsmotor kalt Dremel, som kan skanne milliarder av rader med data på bare noen få sekunder. Dremel bruker massivt parallell spørring for å skanne data i Det underliggende Colossus-filbehandlingssystemet. Colossus distribuerer filer i biter av 64 megabyte blant mange dataressurser kalt noder, som er gruppert i klynger.
Dremel bruker en kolonnedatastruktur som Ligner På Redshift. En trearkitektur sender spørringer blant tusenvis av maskiner i løpet av sekunder.
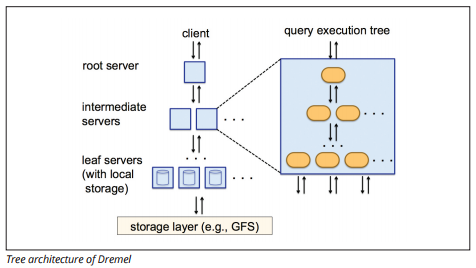
Bildekilde
Enkle SQL-kommandoer brukes til å utføre spørringer på data.
Panoply
Panoply gir ende-til-ende data management-som-en-tjeneste. Dens unike selvoptimaliserende arkitektur benytter maskinlæring og naturlig språkbehandling (nlp) for å modellere og strømlinjeforme datareisen fra kilde til analyse, noe som reduserer tiden fra data til verdi så nært som mulig til ingen.
Panoplys smarte datainfrastruktur inneholder følgende funksjoner:
- Analysere spørringer og data-identifisere den beste konfigurasjonen for hver brukstilfelle, justere den over tid, og bygge indekser, sortnøkler, disknøkler, datatyper, støvsuging og partisjonering.
- Identifiserer spørringer som ikke følger anbefalte fremgangsmåter – for eksempel de som inkluderer nestede looper eller implisitt støping – og omskriver dem til en tilsvarende spørring som krever en brøkdel av kjøretiden eller ressursene.
- Optimalisering av serverkonfigurasjoner over tid basert på spørringsmønstre og ved å lære hvilket serveroppsett som fungerer best. Plattformen bytter servertyper sømløst og måler den resulterende ytelsen.
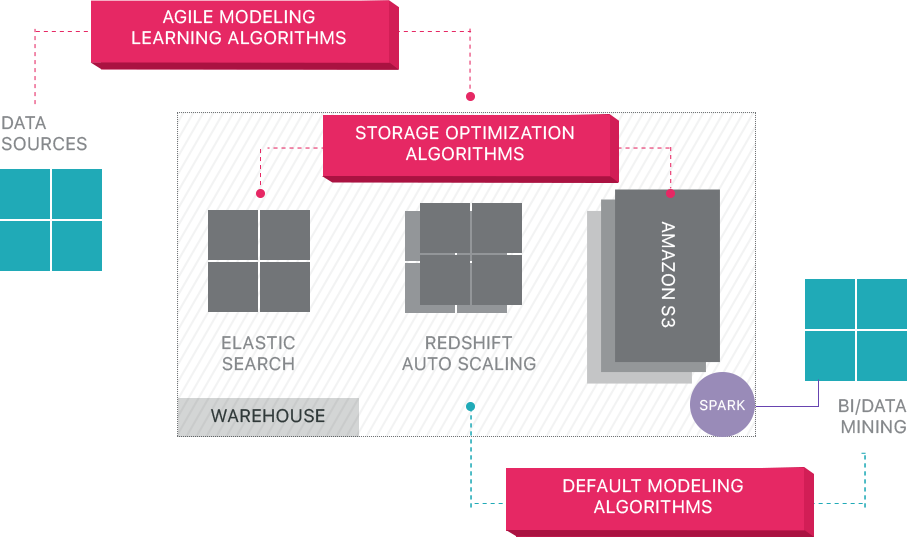
Utover Cloud Data Warehouses
Skybaserte datavarehus er et stort skritt fremover fra tradisjonelle arkitekturer. Men brukerne fortsatt står overfor flere utfordringer når du setter dem opp:
- Lasting av data til datalagre i skyen er ikke trivielt, og for store datasamlebånd krever det å sette opp, teste og vedlikeholde en ETL-prosess. Denne delen av prosessen gjøres vanligvis med tredjepartsverktøy.
- Oppdateringer, upserts og slettinger kan være vanskelig og må gjøres nøye for å hindre forringelse i spørringsytelsen.
- Halvstrukturerte data er vanskelig å håndtere-Må normaliseres til et relasjonsdatabaseformat, som krever automatisering for store datastrømmer.
- Nestede strukturer støttes vanligvis ikke i datalagre i skyen. Du må slå sammen nestede tabeller i et format datavarehuset kan forstå.
- Optimalisere klyngen – det finnes ulike alternativer for å sette Opp En Redshift-klynge for å kjøre arbeidsbelastningene. Ulike arbeidsbelastninger, datasett eller til og med forskjellige typer spørringer kan kreve et annet oppsett. For å være optimal må du kontinuerlig revidere og justere oppsettet ditt.
- Spørringsoptimalisering—brukerspørringer følger kanskje ikke beste praksis, og vil derfor ta mye lengre tid å kjøre. Du kan finne deg selv å jobbe med brukere eller automatiserte klientapplikasjoner for å optimalisere spørringer slik at datalageret kan utføre som forventet.
- Sikkerhetskopiering og gjenoppretting-mens datalagerleverandørene gir mange alternativer for sikkerhetskopiering av dataene dine, er de ikke trivielle å sette opp og krever overvåking og nøye oppmerksomhet.
Panoply Er Et Smart Datalager som legger til et lag med automatisering som tar seg av alle de komplekse oppgavene ovenfor, sparer verdifull tid og hjelper deg med å få fra data til innsikt i løpet av minutter.
Lær mer Om Panoplys smarte datalagerverktøy.
Lær Mer Om Datalager
- Datavarehus Konsepter: Tradisjonell vs. Cloud
- Database vs Datalager
- Data Mart vs Datalager
- Amazon Redshift Arkitektur