hurtownia danych to elektroniczny system, który gromadzi dane z wielu różnych źródeł w firmie i wykorzystuje je do wspomagania podejmowania decyzji zarządczych.
firmy coraz częściej wybierają hurtownie danych oparte na chmurze zamiast tradycyjnych systemów lokalnych. Hurtownie danych oparte na chmurze różnią się od tradycyjnych magazynów w następujący sposób:
- nie ma potrzeby zakupu fizycznego sprzętu.
- konfigurowanie i skalowanie hurtowni danych w chmurze jest szybsze i tańsze.
- oparte na chmurze architektury hurtowni danych mogą zazwyczaj znacznie szybciej wykonywać złożone zapytania analityczne, ponieważ wykorzystują massively parallel processing (MPP).
w dalszej części artykułu omówiono tradycyjną architekturę hurtowni danych i przedstawiono kilka pomysłów i koncepcji architektonicznych wykorzystywanych przez najpopularniejsze usługi hurtowni danych w chmurze.
aby uzyskać więcej informacji, zobacz naszą stronę o koncepcjach hurtowni danych w tym przewodniku.
- tradycyjna architektura hurtowni danych
- Architektura trójwarstwowa
- Kimball vs. Inmon
- modele hurtowni danych
- schemat Gwiazdy vs.schemat Płatka Śniegu
- ETL vs. ELT
- dojrzałość organizacyjna
- nowe architektury hurtowni danych
- Amazon Redshift
- Google BigQuery
- Panoply
- poza hurtowniami danych w chmurze
- dowiedz się więcej o hurtowniach danych
tradycyjna architektura hurtowni danych
poniższe koncepcje podkreślają niektóre z ustalonych idei i zasad projektowania stosowanych do budowy tradycyjnych hurtowni danych.
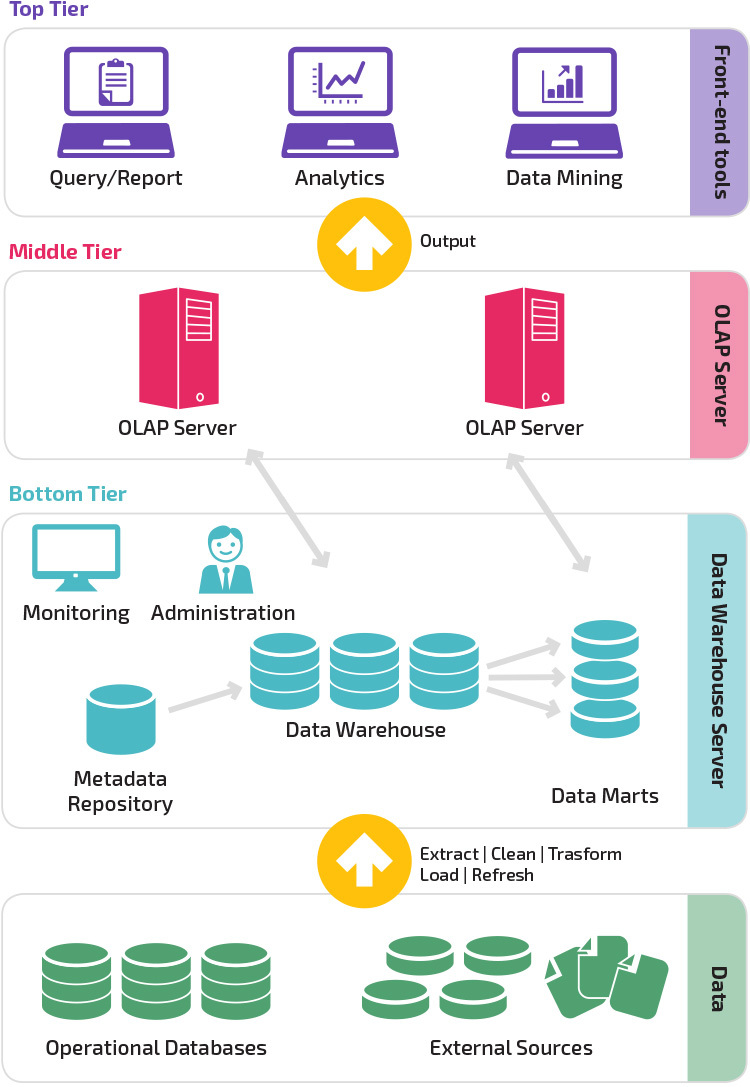
Architektura trójwarstwowa
tradycyjna architektura hurtowni danych wykorzystuje trójwarstwową strukturę złożoną z następujących warstw.
- dolna warstwa: ta warstwa zawiera serwer bazy danych używany do wyodrębniania danych z wielu różnych źródeł, na przykład z transakcyjnych baz danych używanych w aplikacjach front-end.
- poziom średni: W środkowej warstwie znajduje się serwer OLAP, który przekształca dane w strukturę lepiej dostosowaną do analizy i złożonych zapytań. Serwer OLAP może pracować na dwa sposoby: jako rozszerzony system zarządzania relacyjnymi bazami danych, który mapuje operacje na danych wielowymiarowych do standardowych operacji relacyjnych (Relational OLAP) lub przy użyciu wielowymiarowego modelu OLAP, który bezpośrednio implementuje wielowymiarowe Dane i operacje.
- najwyższy poziom: najwyższy poziom to warstwa kliencka. Ta warstwa zawiera narzędzia używane do analizy danych wysokiego poziomu, raportowania zapytań i eksploracji danych.
Kimball vs. Inmon
dwaj pionierzy hurtowni danych, Bill Inmon i Ralph Kimball, mieli różne podejścia do projektowania hurtowni danych.
podejście Ralpha Kimballa podkreślało znaczenie data marts, czyli repozytoriów danych należących do poszczególnych rodzajów działalności. Hurtownia danych to po prostu połączenie różnych centrów danych, które ułatwia raportowanie i analizę. Projekt hurtowni danych Kimball wykorzystuje podejście „oddolne”.
Bill Inmon uznał hurtownię danych za scentralizowane repozytorium wszystkich danych przedsiębiorstwa. W tym podejściu organizacja najpierw tworzy znormalizowany model hurtowni danych. Wymiarowe Marty danych są następnie tworzone w oparciu o model magazynu. Jest to znane jako odgórne podejście do hurtowni danych.
modele hurtowni danych
w tradycyjnej architekturze istnieją trzy wspólne modele hurtowni danych: virtual warehouse, data mart i enterprise data warehouse:
- wirtualna hurtownia danych to zestaw oddzielnych baz danych, które mogą być wyszukiwane razem, dzięki czemu użytkownik może efektywnie uzyskać dostęp do wszystkich danych tak, jakby były przechowywane w jednej hurtowni danych.
- Model Data mart jest używany do raportowania i analizy specyficznych linii biznesowych. W tym modelu hurtowni danych dane są agregowane z szeregu systemów źródłowych istotnych dla określonego obszaru działalności, takich jak sprzedaż lub Finanse.
- model hurtowni danych przedsiębiorstwa przewiduje, że hurtownia danych zawiera zagregowane dane obejmujące całą organizację. Model ten postrzega hurtownię danych jako serce systemu informacyjnego przedsiębiorstwa, ze zintegrowanymi danymi ze wszystkich jednostek biznesowych.
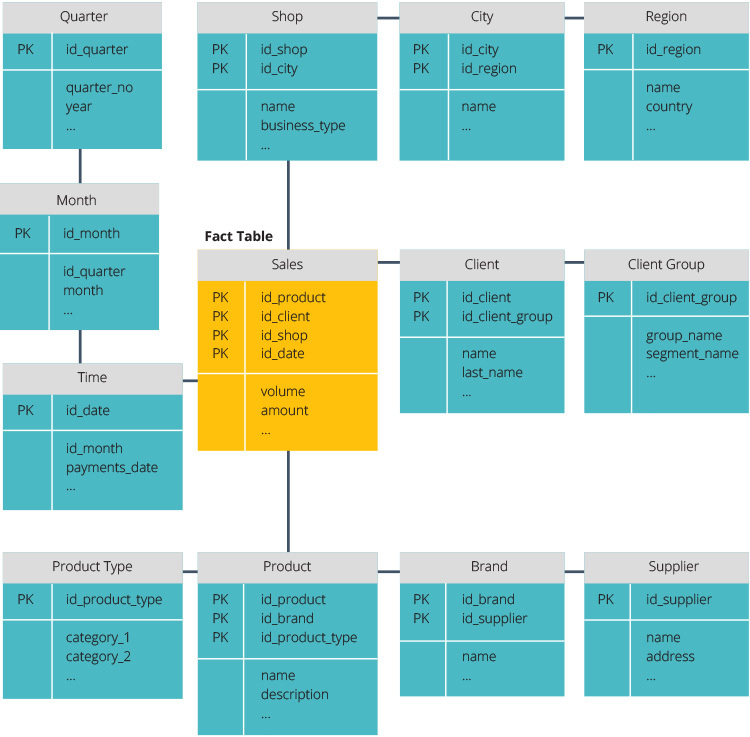
schemat Gwiazdy vs.schemat Płatka Śniegu
schemat gwiazdy i schemat płatka śniegu to dwa sposoby na uporządkowanie hurtowni danych.
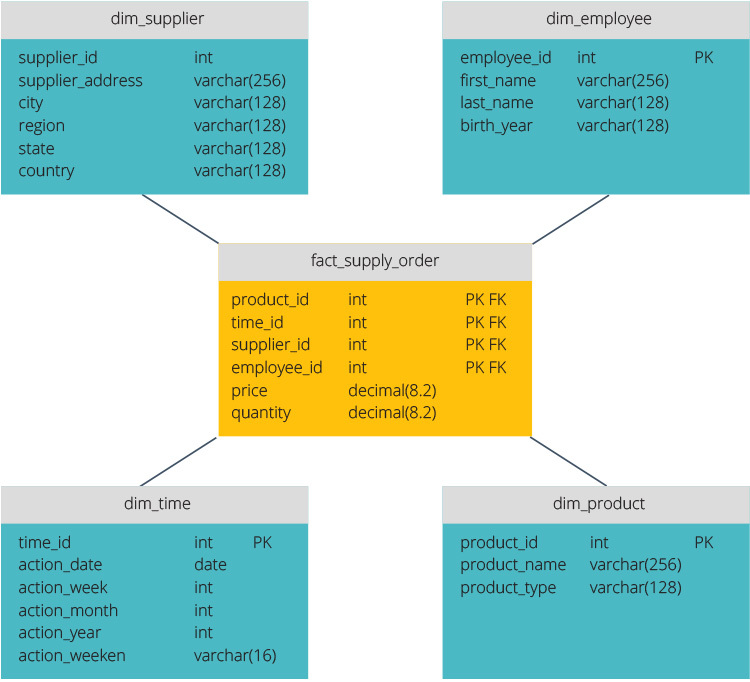
schemat Gwiazdy ma scentralizowane repozytorium danych, przechowywane w tabeli faktów. Schemat dzieli tabelę faktów na szereg denormalizowanych tabel wymiarów. Tabela faktów zawiera zagregowane dane do wykorzystania do celów sprawozdawczych, podczas gdy tabela wymiarów opisuje przechowywane dane.
Denormalizowane projekty są mniej złożone, ponieważ dane są grupowane. Tabela faktów używa tylko jednego łącza do łączenia z każdą tabelą wymiarów. Prostsza konstrukcja schematu gwiazdowego znacznie ułatwia pisanie złożonych zapytań.
schemat płatka śniegu jest inny, ponieważ normalizuje dane. Normalizacja oznacza efektywną organizację danych tak, aby wszystkie zależności danych były zdefiniowane, a każda tabela zawiera minimalne redundancje. W ten sposób tabele pojedynczego wymiaru dzielą się na oddzielne tabele wymiarowe.
schemat płatka śniegu zużywa mniej miejsca na dysku i lepiej zachowuje integralność danych. Główną wadą jest złożoność zapytań wymaganych do uzyskania dostępu do danych-każde zapytanie musi kopać głęboko, aby dostać się do odpowiednich danych, ponieważ istnieje wiele połączeń.
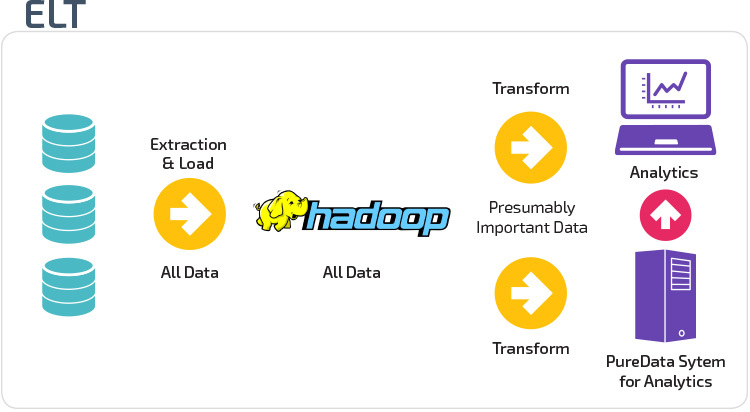
ETL vs. ELT
ETL i ELT to dwie różne metody ładowania danych do magazynu.
Extract, Transform, Load (ETL) najpierw wyodrębnia dane z puli źródeł danych, którymi zazwyczaj są transakcyjne bazy danych. Dane są przechowywane w tymczasowej bazie danych. Następnie wykonywane są operacje transformacji, aby ustrukturyzować i przekształcić dane w odpowiednią formę dla docelowego systemu hurtowni danych. Ustrukturyzowane dane są następnie ładowane do magazynu i gotowe do analizy.
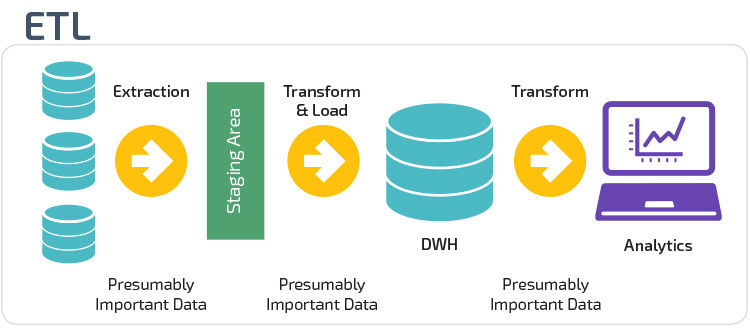
dzięki funkcji Extract Load Transform (ELT) dane są ładowane natychmiast po wyodrębnieniu z puli danych źródłowych. Nie ma bazy danych, co oznacza, że dane są natychmiast ładowane do jednego, scentralizowanego repozytorium. Dane są przekształcane wewnątrz systemu hurtowni danych w celu korzystania z narzędzi Business intelligence i analityki.
dojrzałość organizacyjna
struktura hurtowni danych organizacji zależy również od jej aktualnej sytuacji i potrzeb.
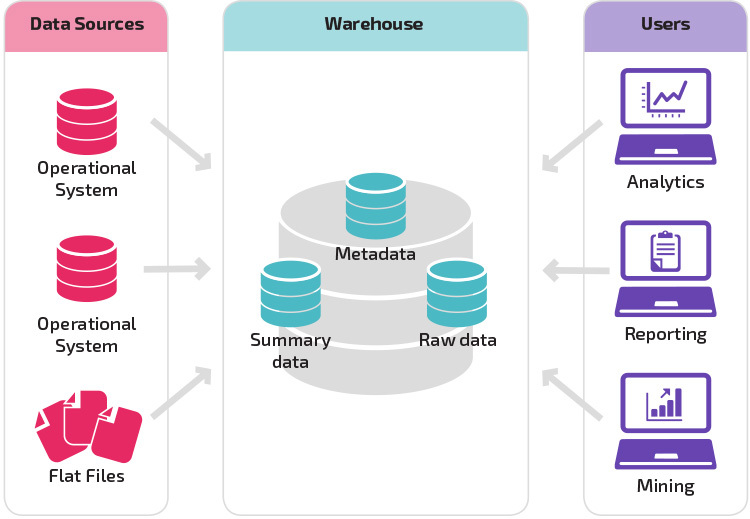
podstawowa struktura umożliwia użytkownikom końcowym magazynu bezpośredni dostęp do danych zbiorczych pochodzących z systemów źródłowych i wykonywanie analiz, raportowania i wydobywania tych danych. Ta struktura jest przydatna, gdy źródła danych pochodzą z tych samych typów systemów bazodanowych.
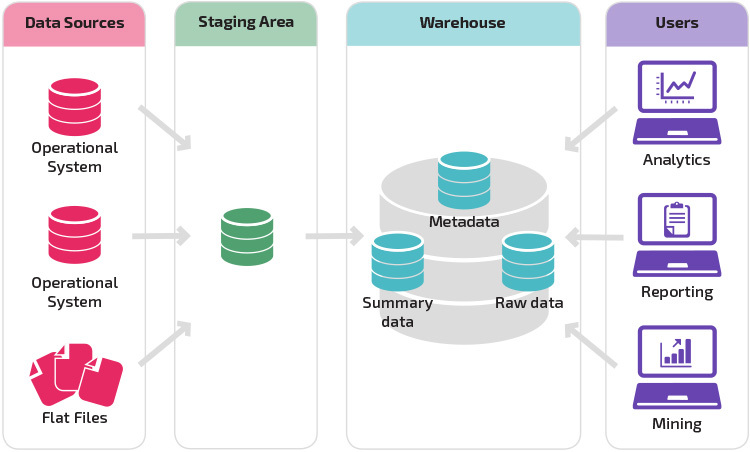
magazyn z miejscem postoju jest kolejnym logicznym krokiem w organizacji z różnymi źródłami danych z wieloma różnymi typami i formatami danych. Obszar przechowalni konwertuje dane do podsumowanego strukturalnego formatu, który jest łatwiejszy do odpytywania dzięki narzędziom do analizy i raportowania.
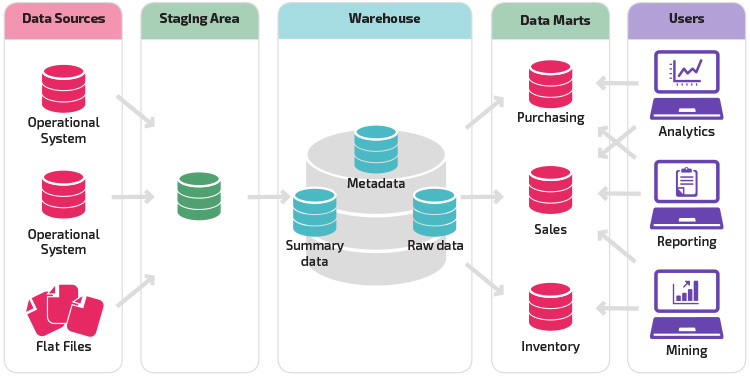
wariacją na temat struktury postoju jest dodanie martów danych do hurtowni danych. Sklep data marts podsumował dane dla konkretnej branży, dzięki czemu dane te są łatwo dostępne dla konkretnych form analizy. Na przykład dodawanie danych marts może pozwolić analitykowi finansowemu na łatwiejsze wykonywanie szczegółowych zapytań dotyczących danych sprzedaży, aby przewidywać zachowania klientów. Data marts ułatwia analizę, dostosowując dane specjalnie do potrzeb użytkownika końcowego.
nowe architektury hurtowni danych
w ostatnich latach hurtownie danych przenoszą się do chmury. Nowe hurtownie danych oparte na chmurze nie są zgodne z tradycyjną architekturą; każda oferta hurtowni danych ma unikalną architekturę.
w tej sekcji podsumowano architektury używane przez dwa najpopularniejsze magazyny w chmurze: Amazon Redshift i Google BigQuery.
Amazon Redshift
Amazon Redshift to oparta na chmurze reprezentacja tradycyjnej hurtowni danych.
Redshift wymaga Aprowizacji i skonfigurowania zasobów obliczeniowych w postaci klastrów, które zawierają zbiór jednego lub więcej węzłów. Każdy węzeł ma swój własny procesor, pamięć masową i pamięć RAM. Węzeł lidera kompiluje zapytania i przekazuje je do węzłów obliczeniowych, które wykonują zapytania.
na każdym węźle dane są przechowywane w kawałkach, zwanych plasterkami. Redshift używa magazynu kolumnowego, co oznacza, że każdy blok danych zawiera wartości z jednej kolumny w wielu wierszach, zamiast pojedynczego wiersza z wartościami z wielu kolumn.
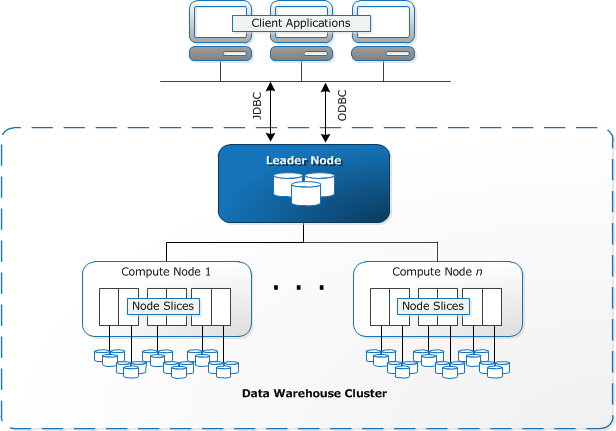
źródło: dokumentacja AWS
Redshift wykorzystuje architekturę MPP, dzieląc duże zbiory danych na części, które są przypisane do plasterków w każdym węźle. Zapytania działają szybciej, ponieważ węzły obliczeniowe przetwarzają zapytania w każdym plasterku jednocześnie. Węzeł Leader agreguje wyniki i zwraca je do aplikacji klienckiej.
aplikacje klienckie, takie jak narzędzia analityczne i BI, mogą bezpośrednio łączyć się z Redshift za pomocą sterowników JDBC i ODBC typu open source PostgreSQL. Analitycy mogą więc wykonywać swoje zadania bezpośrednio na danych Redshift.
Redshift może ładować tylko dane strukturalne. Możliwe jest załadowanie danych do Redshift za pomocą wstępnie zintegrowanych systemów, w tym Amazon S3 i DynamoDB, poprzez wypychanie danych z dowolnego hosta lokalnego z połączeniem SSH lub poprzez integrację innych źródeł danych za pomocą interfejsu API Redshift.
Google BigQuery
Architektura BigQuery jest bezserwerowa, co oznacza, że Google dynamicznie zarządza alokacją zasobów maszyny. Wszystkie decyzje dotyczące zarządzania zasobami są zatem ukryte przed użytkownikiem.
BigQuery umożliwia Klientom ładowanie danych z Google Cloud Storage i innych czytelnych źródeł danych. Alternatywną opcją jest przesyłanie strumieniowe danych, co pozwala programistom dodawać dane do hurtowni danych w czasie rzeczywistym, wiersz po wierszu, gdy będzie ona dostępna.
BigQuery używa silnika wykonywania zapytań o nazwie Dremel, który może skanować miliardy wierszy danych w ciągu zaledwie kilku sekund. Dremel wykorzystuje masowo równoległe zapytania do skanowania danych w bazowym systemie zarządzania plikami Colossus. Colossus rozdziela pliki na 64 megabajty wśród wielu zasobów obliczeniowych zwanych węzłami, które są zgrupowane w klastry.
Dremel wykorzystuje kolumnową strukturę danych, podobną do Redshift. Architektura drzewa wysyła zapytania wśród tysięcy maszyn w ciągu kilku sekund.
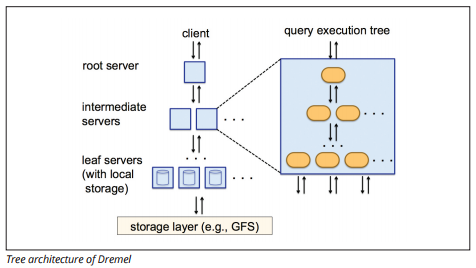
źródło obrazu
proste polecenia SQL są używane do wykonywania zapytań o dane.
Panoply
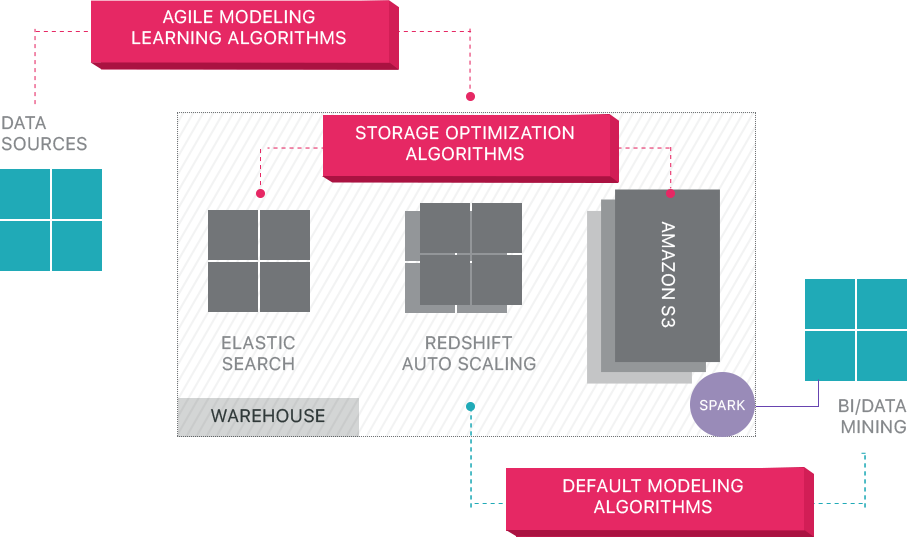
panoply zapewnia kompleksowe zarządzanie danymi jako usługa. Jego unikalna, samooptymalizująca się architektura wykorzystuje uczenie maszynowe i przetwarzanie języka naturalnego (NLP) do modelowania i usprawniania podróży danych od źródła do analizy, skracając czas od danych do wartości tak blisko, jak to możliwe, do zera.
inteligentna infrastruktura danych Panoply obejmuje następujące funkcje:
- Analiza zapytań i danych – identyfikacja najlepszej konfiguracji dla każdego przypadku użycia, dostosowywanie jej w czasie i budowanie indeksów, klawiszy sortowania, dyskietek, typów danych, Odkurzanie i partycjonowanie.
- identyfikowanie zapytań, które nie są zgodne z najlepszymi praktykami – takimi jak te, które zawierają zagnieżdżone pętle lub ukryte rzucanie – i przepisywanie ich do równoważnego zapytania wymagającego ułamka środowiska wykonawczego lub zasobów.
- Optymalizacja konfiguracji serwera w czasie na podstawie wzorców zapytań i dzięki nauce, która konfiguracja serwera działa najlepiej. Platforma bezproblemowo przełącza typy serwerów i mierzy wynikającą z tego wydajność.
poza hurtowniami danych w chmurze
hurtownie danych oparte na chmurze to duży krok naprzód w stosunku do tradycyjnych architektur. Jednak użytkownicy nadal napotykają kilka wyzwań podczas ich konfigurowania:
- ładowanie danych do hurtowni danych w chmurze nie jest trywialne, a w przypadku potoków danych na dużą skalę wymaga skonfigurowania, przetestowania i utrzymania procesu ETL. Ta część procesu jest zwykle wykonywana za pomocą narzędzi innych firm.
- aktualizacje, polecenia upsert i usunięcia mogą być trudne i muszą być wykonywane ostrożnie, aby zapobiec pogorszeniu wydajności zapytań.
- dane półstrukturalne są trudne do opanowania-muszą zostać znormalizowane do formatu relacyjnej bazy danych, który wymaga automatyzacji dla dużych strumieni danych.
- zagnieżdżone struktury zazwyczaj nie są obsługiwane w hurtowniach danych w chmurze. Konieczne będzie spłaszczenie zagnieżdżonych tabel w formacie, który może zrozumieć hurtownia danych.
- Optymalizacja klastra – istnieją różne opcje konfiguracji klastra Redshift do uruchamiania obciążeń. Różne obciążenia, zestawy danych, a nawet różne typy zapytań mogą wymagać innej konfiguracji. Aby zachować optymalność, musisz stale powracać do swoich ustawień i dostosowywać je.
- optymalizacja zapytań-zapytania Użytkowników mogą nie być zgodne z najlepszymi praktykami i w związku z tym ich uruchomienie zajmie znacznie więcej czasu. Możesz pracować z użytkownikami lub zautomatyzowanymi aplikacjami klienckimi w celu optymalizacji zapytań, aby hurtownia danych mogła działać zgodnie z oczekiwaniami.
- tworzenie kopii zapasowych i odzyskiwanie—chociaż dostawcy hurtowni danych oferują wiele opcji tworzenia kopii zapasowych danych, nie są banalni w konfiguracji i wymagają monitorowania i uważnej uwagi.
Panoply to inteligentna Hurtownia danych, która dodaje warstwę automatyzacji, która zajmuje się wszystkimi złożonymi zadaniami powyżej, oszczędzając cenny czas i pomagając uzyskać dostęp do danych w ciągu kilku minut.
dowiedz się więcej o narzędziach inteligentnej hurtowni danych Panoply.
dowiedz się więcej o hurtowniach danych
- koncepcje hurtowni danych: tradycyjny vs. Chmura
- baza danych vs. Hurtownia danych
- Data Mart vs. Hurtownia danych
- Architektura Amazon Redshift