Un almacén de datos es un sistema electrónico que recopila datos de una amplia gama de fuentes dentro de una empresa y utiliza los datos para respaldar la toma de decisiones de gestión.
Las empresas se están moviendo cada vez más hacia almacenes de datos basados en la nube en lugar de sistemas locales tradicionales. Los almacenes de datos basados en la nube difieren de los almacenes tradicionales de las siguientes maneras:
- No es necesario comprar hardware físico.
- Configurar y escalar almacenes de datos en la nube es más rápido y barato.
- Las arquitecturas de almacén de datos basadas en la nube normalmente pueden realizar consultas analíticas complejas mucho más rápido porque utilizan procesamiento paralelo masivo (MPP).
El resto de este artículo cubre la arquitectura de almacén de datos tradicional e introduce algunas ideas y conceptos arquitectónicos utilizados por los servicios de almacén de datos basados en la nube más populares.
Para obtener más información, consulte nuestra página sobre conceptos de almacén de datos en esta guía.
- Arquitectura de almacén de datos tradicional
- Arquitectura de tres niveles
- Kimball vs. Inmon
- Modelos de almacén de datos
- Esquema de estrella vs. Esquema de copo de nieve
- ETL vs ELT
- Madurez organizacional
- Nuevas arquitecturas de almacén de datos
- Amazon Redshift
- Google BigQuery
- Panoply
- Más allá de los almacenes de datos en la nube
- Más información sobre los Almacenes de datos
Arquitectura de almacén de datos tradicional
Los siguientes conceptos destacan algunas de las ideas establecidas y los principios de diseño utilizados para construir almacenes de datos tradicionales.
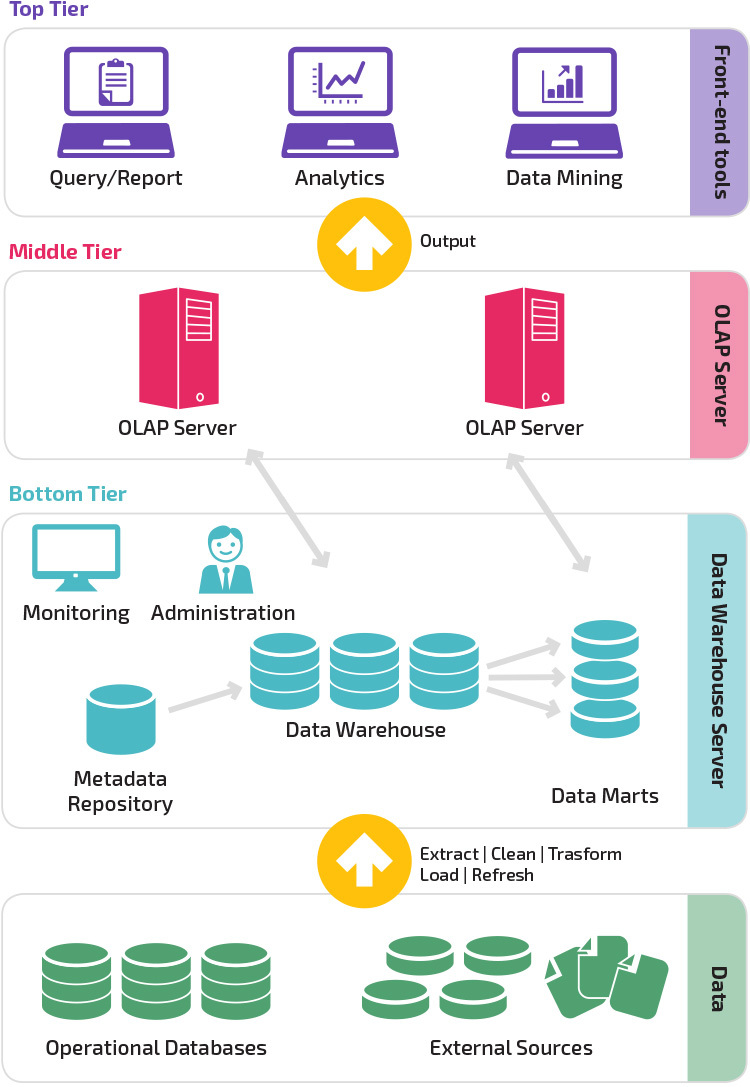
Arquitectura de tres niveles
La arquitectura tradicional de almacén de datos emplea una estructura de tres niveles compuesta por los siguientes niveles.
- Nivel inferior: Este nivel contiene el servidor de base de datos utilizado para extraer datos de muchas fuentes diferentes, como las bases de datos transaccionales utilizadas para aplicaciones front-end.
- nivel Medio: El nivel medio alberga un servidor OLAP, que transforma los datos en una estructura más adecuada para el análisis y las consultas complejas. El servidor OLAP puede funcionar de dos maneras: como un sistema de gestión de bases de datos relacionales extendido que mapea las operaciones en datos multidimensionales a operaciones relacionales estándar (OLAP relacional), o utilizando un modelo OLAP multidimensional que implementa directamente los datos y operaciones multidimensionales.
- Nivel superior: El nivel superior es la capa de cliente. Este nivel contiene las herramientas utilizadas para el análisis de datos de alto nivel, la generación de informes de consultas y la minería de datos.
Kimball vs. Inmon
Dos pioneros del almacenamiento de datos, Bill Inmon y Ralph Kimball, tenían diferentes enfoques para el diseño de almacenes de datos.
El enfoque de Ralph Kimball enfatizó la importancia de los data marts, que son repositorios de datos pertenecientes a líneas de negocio particulares. El almacén de datos es simplemente una combinación de diferentes data marts que facilita la generación de informes y el análisis. El diseño del almacén de datos de Kimball utiliza un enfoque «ascendente».
Bill Inmon consideraba el almacén de datos como el repositorio centralizado para todos los datos empresariales. En este enfoque, una organización primero crea un modelo de almacén de datos normalizado. A continuación, se crean mercados de datos dimensionales basados en el modelo de almacén. Esto se conoce como un enfoque descendente para el almacenamiento de datos.
Modelos de almacén de datos
En una arquitectura tradicional hay tres modelos de almacén de datos comunes: almacén virtual, data mart y almacén de datos empresarial:
- Un almacén de datos virtual es un conjunto de bases de datos separadas, que se pueden consultar juntas, para que un usuario pueda acceder de manera efectiva a todos los datos como si estuvieran almacenados en un almacén de datos.
- Se utiliza un modelo de data mart para informes y análisis específicos de líneas de negocio. En este modelo de almacén de datos, los datos se agregan de una variedad de sistemas de origen relevantes para un área de negocio específica, como ventas o finanzas.
- Un modelo de almacén de datos empresarial prescribe que el almacén de datos contenga datos agregados que abarquen toda la organización. Este modelo considera el almacén de datos como el corazón del sistema de información de la empresa, con datos integrados de todas las unidades de negocio.
Esquema de estrella vs. Esquema de copo de nieve
El esquema de estrella y el esquema de copo de nieve son dos formas de estructurar un almacén de datos.
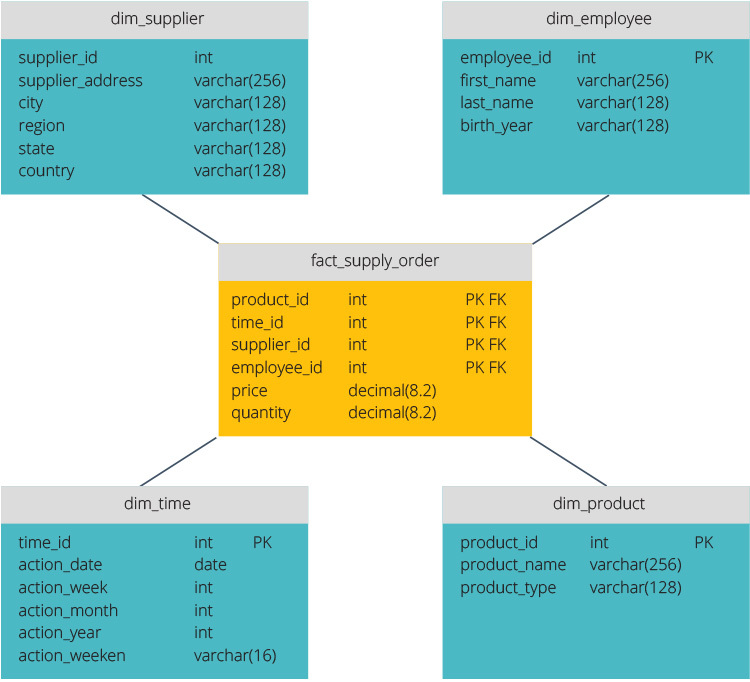
El esquema star tiene un repositorio de datos centralizado, almacenado en una tabla de datos. El esquema divide la tabla de hechos en una serie de tablas de dimensiones desnormalizadas. La tabla de hechos contiene datos agregados que se utilizarán para la elaboración de informes, mientras que la tabla de dimensiones describe los datos almacenados.
Los diseños desnormalizados son menos complejos porque los datos están agrupados. La tabla fact utiliza solo un enlace para unirse a cada tabla de dimensiones. El diseño más simple del esquema star hace que sea mucho más fácil escribir consultas complejas.
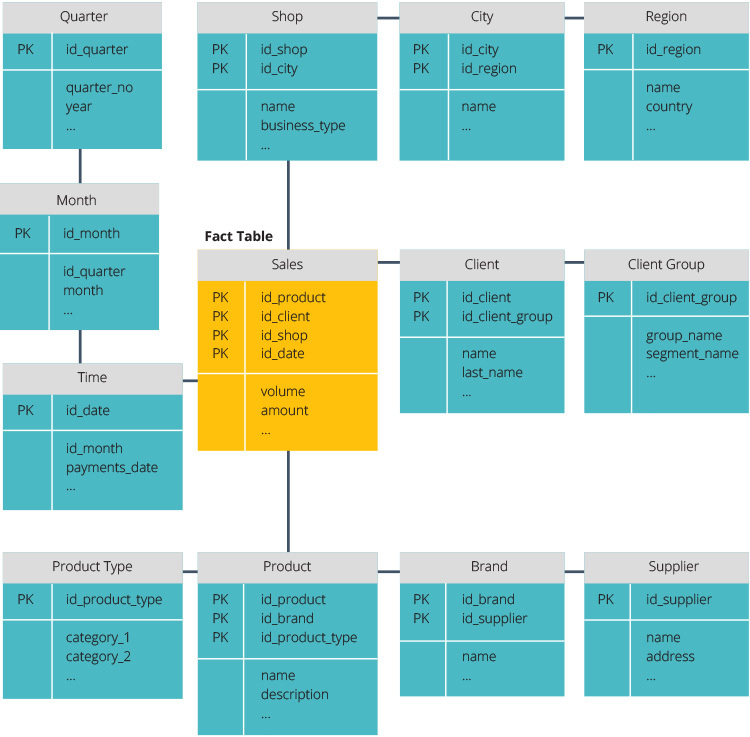
El esquema de copo de nieve es diferente porque normaliza los datos. Normalización significa organizar eficientemente los datos para que se definan todas las dependencias de datos y cada tabla contenga redundancias mínimas. Las tablas de una sola dimensión se ramifican en tablas de dimensiones separadas.
El esquema snowflake utiliza menos espacio en disco y conserva mejor la integridad de los datos. La principal desventaja es la complejidad de las consultas necesarias para acceder a los datos: cada consulta debe profundizar para llegar a los datos relevantes porque hay varias uniones.
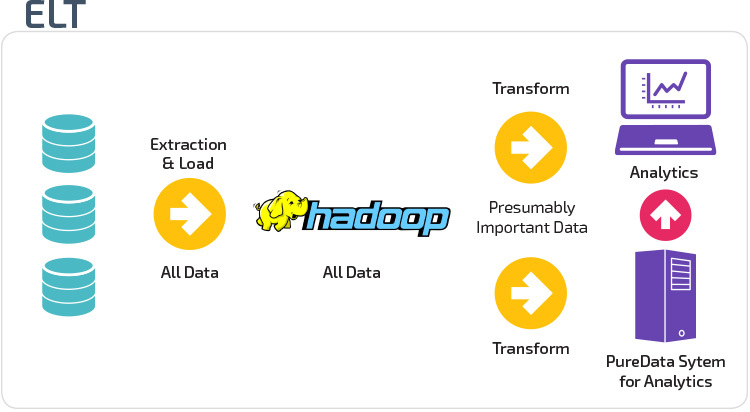
ETL vs ELT
ETL y ELT son dos métodos diferentes de carga de datos en un almacén.
Extraer, transformar, cargar (ETL) primero extrae los datos de un conjunto de fuentes de datos, que normalmente son bases de datos transaccionales. Los datos se guardan en una base de datos provisional temporal. A continuación, se realizan operaciones de transformación para estructurar y convertir los datos en una forma adecuada para el sistema de almacenamiento de datos de destino. Los datos estructurados se cargan en el almacén, listos para su análisis.
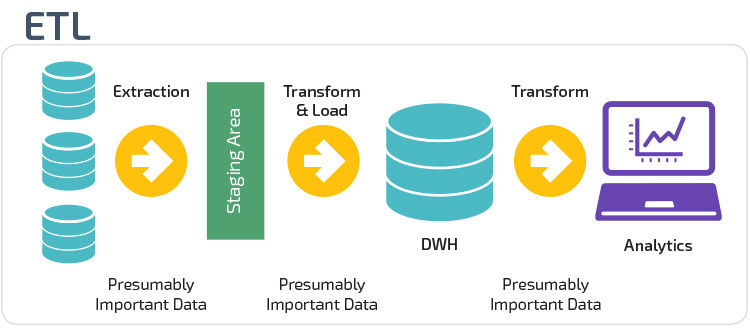
Con la transformación de carga de extracción (ELT), los datos se cargan inmediatamente después de extraerse de los grupos de datos de origen. No hay una base de datos provisional, lo que significa que los datos se cargan inmediatamente en el repositorio único y centralizado. Los datos se transforman dentro del sistema de almacenamiento de datos para usarlos con herramientas de inteligencia empresarial y análisis.
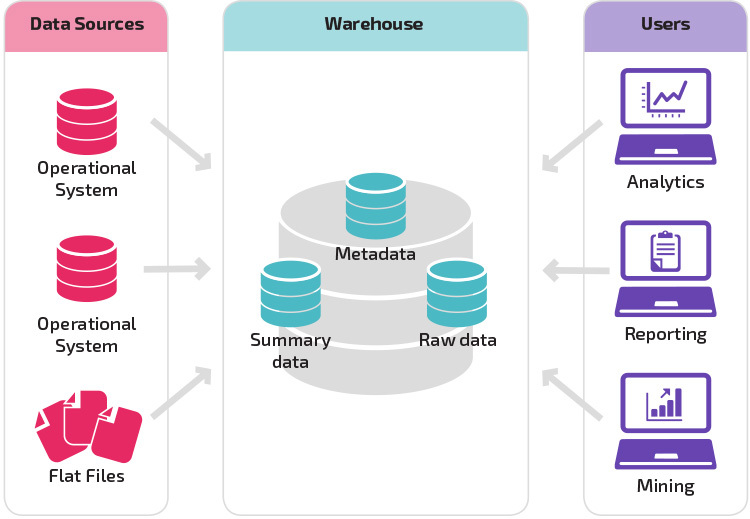
Madurez organizacional
La estructura del almacén de datos de una organización también depende de su situación y necesidades actuales.
La estructura básica permite a los usuarios finales del almacén acceder directamente a los datos resumidos derivados de los sistemas de origen y realizar análisis, informes y minería de esos datos. Esta estructura es útil cuando las fuentes de datos se derivan de los mismos tipos de sistemas de bases de datos.
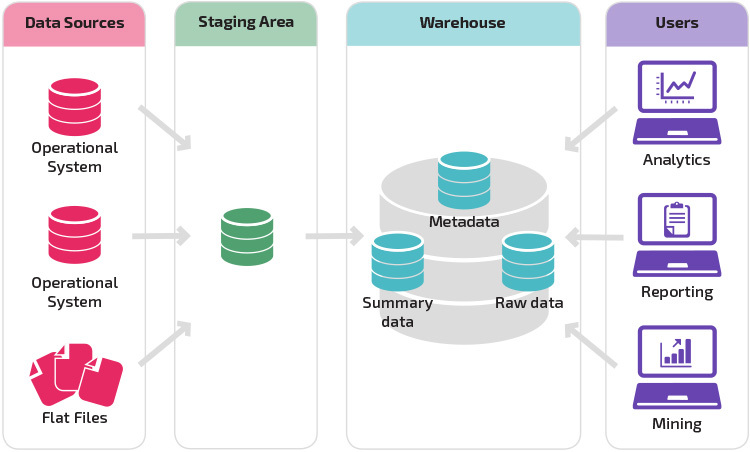
Un almacén con un área de preparación es el siguiente paso lógico en una organización con fuentes de datos dispares con muchos tipos y formatos de datos diferentes. El área de preparación convierte los datos en un formato estructurado resumido que es más fácil de consultar con herramientas de análisis e informes.
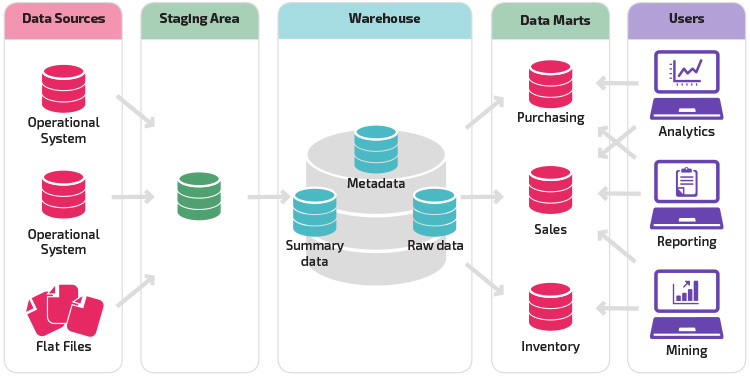
Una variación en la estructura de etapas es la adición de data marts al almacén de datos. Los data marts almacenan datos resumidos para una línea de negocio en particular, lo que hace que los datos sean fácilmente accesibles para formas específicas de análisis. Por ejemplo, agregar data marts puede permitir que un analista financiero realice consultas detalladas sobre los datos de ventas con mayor facilidad, para hacer predicciones sobre el comportamiento de los clientes. Los Data marts facilitan el análisis al adaptar los datos específicamente para satisfacer las necesidades del usuario final.
Nuevas arquitecturas de almacén de datos
En los últimos años, los almacenes de datos se están trasladando a la nube. Los nuevos almacenes de datos basados en la nube no se adhieren a la arquitectura tradicional; cada oferta de almacén de datos tiene una arquitectura única.
En esta sección se resumen las arquitecturas utilizadas por dos de los almacenes basados en la nube más populares: Amazon Redshift y Google BigQuery.
Amazon Redshift
Amazon Redshift es una representación basada en la nube de un almacén de datos tradicional.
Redshift requiere de recursos informáticos para aprovisionar y configurar en forma de racimos, que contienen una colección de uno o más nodos. Cada nodo tiene su propia CPU, almacenamiento y RAM. Un nodo líder compila consultas y las transfiere a nodos de cómputo, que ejecutan las consultas.
En cada nodo, los datos se almacenan en trozos, llamados segmentos. Redshift utiliza un almacenamiento en columnas, lo que significa que cada bloque de datos contiene valores de una sola columna en varias filas, en lugar de una sola fila con valores de varias columnas.
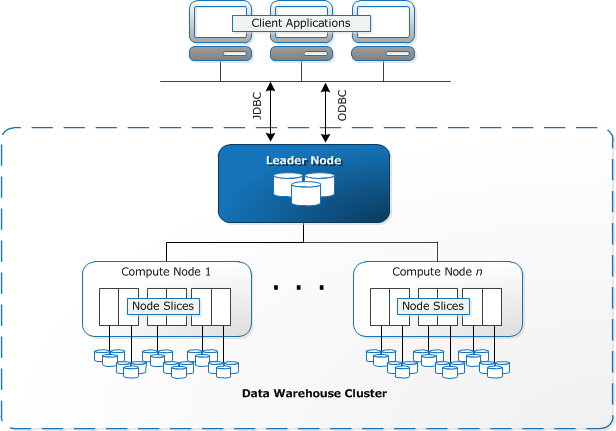
Fuente: Documentación de AWS
Redshift utiliza una arquitectura MPP, que divide grandes conjuntos de datos en trozos que se asignan a segmentos dentro de cada nodo. Las consultas funcionan más rápido porque los nodos de cómputo procesan las consultas en cada segmento simultáneamente. El nodo Líder agrega los resultados y los devuelve a la aplicación cliente.
Las aplicaciones cliente, como las herramientas de BI y análisis, se pueden conectar directamente a Redshift mediante controladores de código abierto PostgreSQL JDBC y ODBC. De este modo, los analistas pueden realizar sus tareas directamente en los datos de corrimiento al rojo.
Redshift solo puede cargar datos estructurados. Es posible cargar datos en Redshift mediante sistemas preintegrados, incluidos Amazon S3 y DynamoDB, enviando datos desde cualquier host local con conectividad SSH o integrando otras fuentes de datos mediante la API de Redshift.
Google BigQuery
La arquitectura de BigQuery no tiene servidor, lo que significa que Google administra dinámicamente la asignación de recursos de máquina. Por lo tanto, todas las decisiones de gestión de recursos se ocultan al usuario.
BigQuery permite a los clientes cargar datos desde el almacenamiento en la nube de Google y otras fuentes de datos legibles. La opción alternativa es transmitir datos, lo que permite a los desarrolladores agregar datos al almacén de datos en tiempo real, fila por fila, a medida que estén disponibles.
BigQuery utiliza un motor de ejecución de consultas llamado Dremel, que puede escanear miles de millones de filas de datos en solo unos segundos. Dremel utiliza consultas masivas en paralelo para escanear datos en el sistema de administración de archivos Colossus subyacente. Colossus distribuye archivos en trozos de 64 megabytes entre muchos recursos informáticos llamados nodos, que se agrupan en clústeres.
Dremel utiliza una estructura de datos en columnas, similar al corrimiento al rojo. Una arquitectura de árbol envía consultas entre miles de máquinas en segundos.
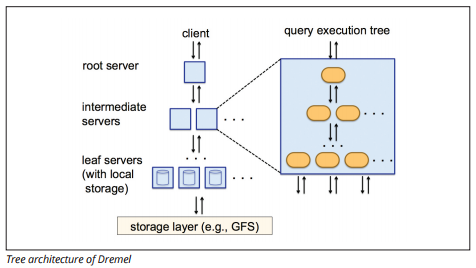
Fuente de imagen
Se utilizan comandos SQL simples para realizar consultas sobre datos.
Panoply
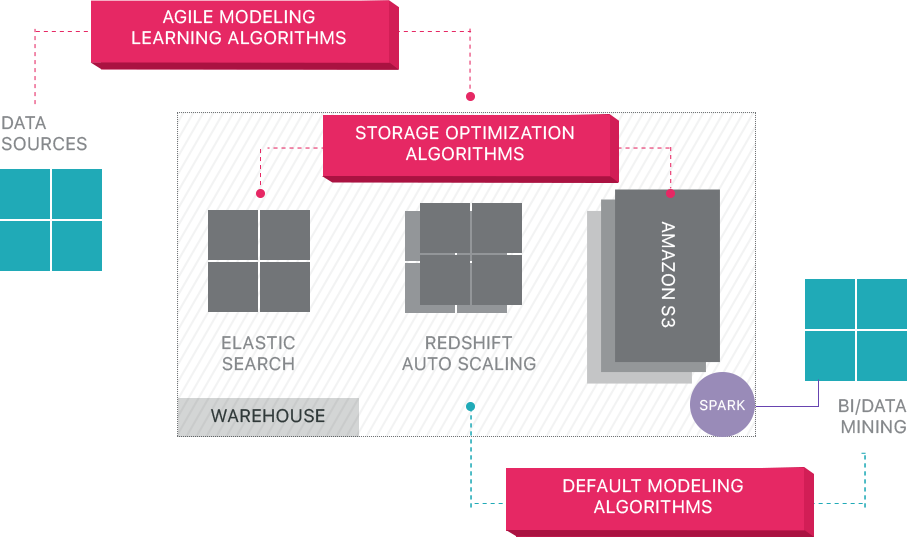
Panoply proporciona gestión de datos como servicio de extremo a extremo. Su arquitectura única de auto-optimización utiliza aprendizaje automático y procesamiento de lenguaje natural (PNL) para modelar y agilizar el recorrido de los datos desde el origen hasta el análisis, reduciendo el tiempo de los datos al valor lo más cerca posible de ninguno.
La infraestructura de datos inteligentes de Panoply incluye las siguientes características:
- Análisis de consultas y datos: identificación de la mejor configuración para cada caso de uso, ajustándola a lo largo del tiempo y creando índices, claves de clasificación, diskeys, tipos de datos, aspiradoras y particiones.
- Identificar consultas que no siguen las prácticas recomendadas – como las que incluyen bucles anidados o fundición implícita, y reescribirlas a una consulta equivalente que requiera una fracción del tiempo de ejecución o los recursos.
- Optimización de las configuraciones de servidor a lo largo del tiempo en función de patrones de consulta y aprendiendo qué configuración de servidor funciona mejor. La plataforma cambia de tipo de servidor sin problemas y mide el rendimiento resultante.
Más allá de los almacenes de datos en la nube
Los almacenes de datos basados en la nube son un gran paso adelante con respecto a las arquitecturas tradicionales. Sin embargo, los usuarios aún enfrentan varios desafíos al configurarlos:
- La carga de datos en almacenes de datos en la nube no es trivial, y para canalizaciones de datos a gran escala, requiere configurar, probar y mantener un proceso ETL. Esta parte del proceso se realiza normalmente con herramientas de terceros.
- Las actualizaciones, los upserts y las eliminaciones pueden ser difíciles y deben hacerse con cuidado para evitar la degradación del rendimiento de las consultas.
- Los datos semiestructurados son difíciles de tratar: deben normalizarse en un formato de base de datos relacional, lo que requiere automatización para flujos de datos grandes.
- Las estructuras anidadas normalmente no son compatibles con los almacenes de datos en la nube. Necesitará aplanar tablas anidadas en un formato que el almacén de datos pueda entender.
- Optimización del clúster: hay diferentes opciones para configurar un clúster de corrimiento al rojo para ejecutar las cargas de trabajo. Diferentes cargas de trabajo, conjuntos de datos o incluso diferentes tipos de consultas pueden requerir una configuración diferente. Para mantenerse óptimo, tendrá que revisar y ajustar continuamente su configuración.
- Optimización de consultas: es posible que las consultas de los usuarios no sigan las prácticas recomendadas y, en consecuencia, tarden mucho más en ejecutarse. Es posible que se encuentre trabajando con usuarios o aplicaciones cliente automatizadas para optimizar las consultas de modo que el almacén de datos pueda funcionar según lo esperado.
- Copia de seguridad y recuperación: si bien los proveedores del almacén de datos ofrecen numerosas opciones para realizar copias de seguridad de sus datos, no son triviales de configurar y requieren supervisión y atención.
Panoply es un almacén de datos inteligente que agrega una capa de automatización que se encarga de todas las complejas tareas anteriores, ahorrando tiempo valioso y ayudándole a pasar de los datos a la información en cuestión de minutos.
Obtenga más información sobre las herramientas de almacenamiento de datos inteligentes de Panoply.
Más información sobre los Almacenes de datos
- Conceptos de almacén de datos: Tradicional vs. La nube
- Base de datos-Datos de Almacén
- Data Mart vs Almacén de Datos
- Amazon Redshift Arquitectura