Una mirada en profundidad a estas peligrosas explotaciones de vulnerabilidades de microprocesadores y por qué podría haber más de ellas por ahí

Estamos acostumbrados a pensar en los procesadores de computadora como máquinas ordenadas que proceden de una instrucción simple a la siguiente con total regularidad. Pero la verdad es que, durante décadas, han estado haciendo sus tareas fuera de orden y adivinando lo que debería venir a continuación. Son muy buenos en eso, por supuesto. Tan buena, de hecho, que esta capacidad, llamada ejecución especulativa, ha sustentado gran parte de la mejora en la potencia de cálculo durante los últimos 25 años aproximadamente. Pero el 3 de enero de 2018, el mundo se enteró de que este truco, que había hecho tanto por la informática moderna, era ahora una de sus mayores vulnerabilidades.
A lo largo de 2017, investigadores de Cyberus Technology, Google Project Zero, la Universidad Tecnológica de Graz, Rambus, la Universidad de Adelaida y la Universidad de Pensilvania, así como investigadores independientes como el criptógrafo Paul Kocher, elaboraron por separado ataques que se aprovecharon de la ejecución especulativa. Nuestro propio grupo había descubierto la vulnerabilidad original detrás de uno de estos ataques en 2016, pero no juntamos todas las piezas.
Este tipo de ataques, llamados Meltdown y Spectre, no eran errores comunes. En el momento en que se descubrió, Meltdown podía hackear todos los microprocesadores Intel x86 y procesadores IBM Power, así como algunos procesadores basados en ARM. Spectre y sus muchas variaciones agregaron procesadores de Microdispositivos Avanzados (AMD) a esa lista. En otras palabras, casi todo el mundo de la informática era vulnerable.
Y debido a que la ejecución especulativa se integra en gran medida en el hardware del procesador, corregir estas vulnerabilidades no ha sido un trabajo fácil. Hacerlo sin causar que las velocidades de computación se muevan a baja velocidad lo ha hecho aún más difícil. De hecho, un año después, el trabajo está lejos de terminar. Se necesitaban parches de seguridad no solo de los fabricantes de procesadores, sino de aquellos que estaban más abajo en la cadena de suministro, como Apple, Dell, Linux y Microsoft. Las primeras computadoras alimentadas por chips que están diseñadas intencionalmente para ser resistentes incluso a algunas de estas vulnerabilidades llegaron recientemente.
Spectre y Meltdown son el resultado de la diferencia entre lo que se supone que hace el software y la microarquitectura del procesador, los detalles de cómo realmente hace esas cosas. Estas dos clases de hacks han descubierto una forma de que la información se filtre a través de esa diferencia. Y hay muchas razones para creer que se descubrirán más formas. Ayudamos a encontrar dos, el Branchscope y los EspectrOSB, el año pasado.
Si vamos a mantener el ritmo de las mejoras informáticas sin sacrificar la seguridad, vamos a tener que entender cómo ocurren estas vulnerabilidades de hardware. Y eso comienza con la comprensión de Spectre y Meltdown.
En los sistemas informáticos modernos, los programas de software escritos en lenguajes comprensibles para el ser humano, como C++, se compilan en instrucciones de lenguaje ensamblador, operaciones fundamentales que el procesador de la computadora puede ejecutar. Para acelerar la ejecución, los procesadores modernos utilizan un enfoque llamado canalización. Al igual que una línea de montaje, la tubería es una serie de etapas, cada una de las cuales es un paso necesario para completar una instrucción. Algunas etapas típicas de un procesador Intel x86 incluyen las que traen la instrucción de la memoria y la decodifican para comprender lo que significa la instrucción. La segmentación básicamente reduce el paralelismo al nivel de ejecución de instrucciones: Cuando una instrucción se realiza usando un escenario, la siguiente instrucción es libre de usarla.
Desde la década de 1990, los microprocesadores se han basado en dos trucos para acelerar el proceso de canalización: ejecución fuera de orden y especulación. Si dos instrucciones son independientes entre sí, es decir, la salida de una no afecta a la entrada de otra, se pueden reordenar y su resultado seguirá siendo correcto. Eso es útil, porque permite que el procesador siga funcionando si una instrucción se detiene en la tubería. Por ejemplo, si una instrucción requiere datos que están en la memoria principal de la DRAM en lugar de en la memoria caché ubicada en la propia CPU, es posible que se necesiten unos cientos de ciclos de reloj para obtener esos datos. En lugar de esperar, el procesador puede mover otra instrucción a través de la canalización.
El segundo truco es la especulación. Para entenderlo, comience con el hecho de que algunas instrucciones conducen necesariamente a un cambio en las instrucciones que vienen a continuación. Considere un programa que contiene una instrucción «if»: Comprueba si hay una condición, y si la condición es verdadera, el procesador salta a una ubicación diferente en el programa. Este es un ejemplo de instrucción de rama condicional, pero hay otras instrucciones que también conducen a cambios en el flujo de instrucciones.
Ahora considere lo que sucede cuando una instrucción de rama de este tipo entra en una canalización. Es una situación que lleva a un enigma. Cuando la instrucción llega al principio de la tubería, no sabemos su resultado hasta que ha progresado bastante profundo en la tubería. Y sin conocer este resultado, no podemos obtener la siguiente instrucción. Una solución simple pero ingenua es evitar que nuevas instrucciones entren en la canalización hasta que la instrucción de rama llegue a un punto en el que sepamos de dónde vendrá la siguiente instrucción. Muchos ciclos de reloj se desperdician en este proceso, porque las tuberías suelen tener de 15 a 25 etapas. Peor aún, las instrucciones de rama aparecen con bastante frecuencia, representando más del 20 por ciento de todas las instrucciones en muchos programas.
Para evitar el alto costo de rendimiento de detener la canalización, los procesadores modernos utilizan una unidad arquitectónica llamada predictor de ramas para adivinar de dónde vendrá la siguiente instrucción, después de una rama. El propósito de este predictor es especular sobre un par de puntos clave. Primero, ¿se tomará una rama condicional, haciendo que el programa se desvíe a una sección diferente del programa, o continuará en la ruta existente? Y segundo, si se toma la rama, ¿a dónde irá el programa-cuál será la siguiente instrucción? Armado con estas predicciones, la canalización del procesador se puede mantener llena.
Debido a que la ejecución de la instrucción se basa en una predicción, se está ejecutando «especulativamente»: Si la predicción es correcta, el rendimiento mejora sustancialmente. Pero si la predicción resulta incorrecta, el procesador debe ser capaz de deshacer los efectos de cualquier instrucción ejecutada especulativamente con relativa rapidez.
El diseño del predictor de ramas se ha investigado exhaustivamente en la comunidad de arquitectura informática durante muchos años. Los predictores modernos utilizan el historial de ejecución dentro de un programa como base para sus resultados. Este esquema logra precisiones superiores al 95 por ciento en muchos tipos diferentes de programas, lo que conduce a mejoras de rendimiento dramáticas, en comparación con un microprocesador que no especula. Sin embargo, la especulación errónea es posible. Y desafortunadamente, es la especulación errónea la que explotan los ataques del Espectro.
Otra forma de especulación que ha dado lugar a problemas es la especulación dentro de una sola instrucción en la tubería. Es un concepto bastante abstracto, así que vamos a desempaquetarlo. Supongamos que una instrucción requiere permiso para ejecutarse. Por ejemplo, una instrucción podría dirigir a la computadora a escribir un trozo de datos en la porción de memoria reservada para el núcleo del sistema operativo. No querrías que eso sucediera, a menos que fuera aprobado por el propio sistema operativo, o te arriesgarías a que la computadora se estrellara. Antes del descubrimiento de Meltdown y Spectre, la sabiduría convencional era que está bien comenzar a ejecutar la instrucción de forma especulativa incluso antes de que el procesador haya alcanzado el punto de verificar si la instrucción tiene o no permiso para hacer su trabajo.
Al final, si el permiso no se cumple, en nuestro ejemplo, el sistema operativo no ha aprobado este intento de jugar con su memoria, los resultados se eliminan y el programa indica un error. En general, el procesador puede especular en torno a cualquier parte de una instrucción que pueda hacer que espere, siempre que la condición se resuelva finalmente y los resultados de las malas conjeturas se deshagan, de manera efectiva. Es este tipo de especulación intra-instrucción lo que está detrás de todas las variantes del error de fusión, incluida su versión posiblemente más peligrosa, Foreshadow.
La información que habilita los ataques de especulación es la siguiente: Durante la especulación errónea, no se produce ningún cambio que un programa pueda observar directamente. En otras palabras, no hay ningún programa que puedas escribir que simplemente muestre los datos generados durante la ejecución especulativa. Sin embargo, el hecho de que se esté produciendo especulación deja huellas al afectar el tiempo que se tarda en ejecutar las instrucciones. Y, desafortunadamente, ahora está claro que podemos detectar estas señales de tiempo y extraer datos secretos de ellas.
¿Qué es esta información de tiempo y cómo la obtiene un hacker? Para entender eso, es necesario comprender el concepto de canales laterales. Un canal lateral es una vía no deseada que filtra información de una entidad a otra (por lo general, ambos son programas de software), por lo general a través de un recurso compartido, como un disco duro o una memoria.
Como ejemplo de ataque de canal lateral, considere un dispositivo que está programado para escuchar el sonido que emana de una impresora y luego usa ese sonido para deducir lo que se está imprimiendo. El sonido, en este caso, es un canal lateral.
En los microprocesadores, cualquier recurso de hardware compartido puede, en principio, usarse como canal lateral que filtra información de un programa víctima a un programa atacante. En un ataque de canal lateral de uso común, el recurso compartido es la caché de la CPU. La caché es una memoria relativamente pequeña de acceso rápido en el chip del procesador que se utiliza para almacenar los datos que un programa necesita con mayor frecuencia. Cuando un programa accede a la memoria, el procesador primero comprueba la caché; si los datos están allí (una visita a la caché), se recuperan rápidamente. Si los datos no están en la caché (un error), el procesador tiene que esperar hasta que se recuperen de la memoria principal, lo que puede llevar varios cientos de ciclos de reloj. Pero una vez que los datos llegan de la memoria principal, se agregan a la caché, lo que puede requerir lanzar algunos otros datos para hacer espacio. La caché se divide en segmentos llamados conjuntos de caché, y cada ubicación en la memoria principal tiene un conjunto correspondiente en la caché. Esta organización hace que sea fácil verificar si hay algo en la caché sin tener que buscar todo.
Los ataques basados en caché habían sido ampliamente investigados incluso antes de que Spectre y Meltdown aparecieran en la escena. Aunque el atacante no puede leer directamente los datos de la víctima, incluso cuando esos datos se encuentran en un recurso compartido como la caché, el atacante puede obtener información sobre las direcciones de memoria a las que accede la víctima. Estas direcciones pueden depender de datos confidenciales, lo que permite a un atacante inteligente recuperar estos datos secretos.
¿Cómo hace esto el atacante? Hay varias maneras posibles. Una variación, llamada Descarga y recarga, comienza con el atacante eliminando los datos compartidos de la caché utilizando la instrucción «descarga». El atacante espera a que la víctima acceda a esos datos. Debido a que ya no está en la caché, cualquier dato que la víctima solicite debe ser traído de la memoria principal. Más tarde, el atacante accede a los datos compartidos mientras cronometra el tiempo que tarda esto. Una coincidencia en caché, es decir, que los datos están de vuelta en la caché, indica que la víctima accedió a los datos. Un error de caché indica que no se ha accedido a los datos. Por lo tanto, simplemente midiendo el tiempo que tardó en acceder a los datos, el atacante puede determinar a qué conjuntos de caché accedió la víctima. Se necesita un poco de magia algorítmica, pero este conocimiento de a qué conjuntos de caché se accedió y cuáles no, puede conducir al descubrimiento de claves de cifrado y otros secretos.
Meltdown, Spectre y sus variantes siguen el mismo patrón. Primero, desencadenan especulaciones para ejecutar el código deseado por el atacante. Este código lee datos secretos sin permiso. Luego, los ataques comunican el secreto usando Descarga y recarga o un canal lateral similar. Esa última parte es bien entendida y similar en todas las variaciones de ataque. Por lo tanto, los ataques difieren solo en el primer componente, que es cómo desencadenar y explotar la especulación.
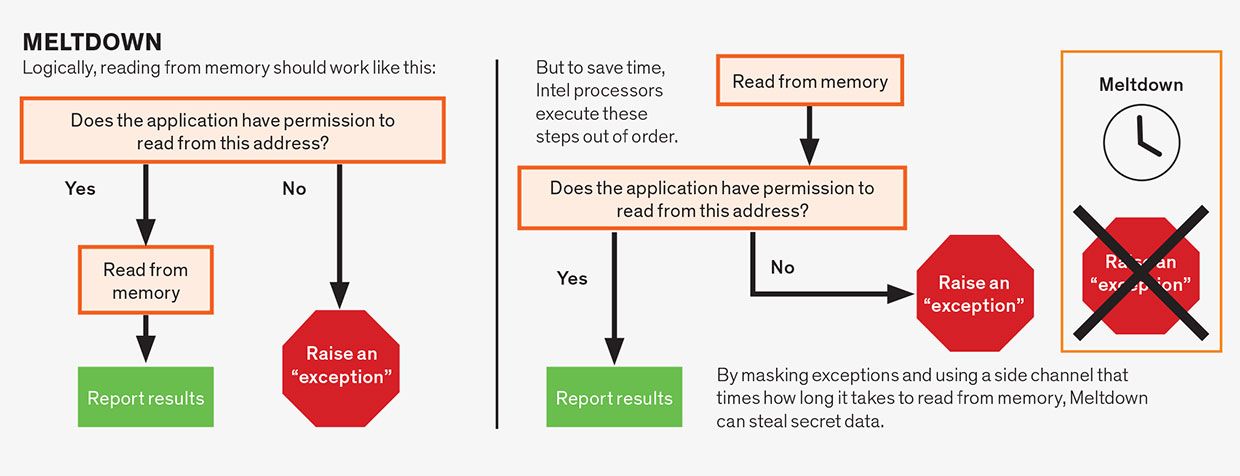
Ataques de fusión
Los ataques de fusión explotan la especulación dentro de una sola instrucción. Aunque las instrucciones en lenguaje ensamblador suelen ser simples, una sola instrucción a menudo consiste en varias operaciones que pueden depender unas de otras. Por ejemplo, las operaciones de lectura de memoria a menudo dependen de que la instrucción cumpla los permisos asociados con la dirección de memoria que se está leyendo. Una aplicación generalmente tiene permiso para leer solo desde la memoria que se le ha asignado, no desde la memoria asignada, por ejemplo, al sistema operativo o al programa de algún otro usuario. Lógicamente, debemos verificar los permisos antes de permitir que la lectura continúe, que es lo que hacen algunos microprocesadores, especialmente los de AMD. Sin embargo, siempre que el resultado final sea correcto, los diseñadores de CPU asumieron que eran libres de ejecutar especulativamente estas operaciones fuera de orden. Por lo tanto, los microprocesadores Intel leen la ubicación de la memoria antes de comprobar los permisos, pero solo «confirman» la instrucción, haciendo que los resultados sean visibles para el programa, cuando se cumplen los permisos. Pero debido a que los datos secretos se han recuperado de forma especulativa, se pueden descubrir utilizando un canal lateral, lo que hace que los procesadores Intel sean vulnerables a este ataque.
El ataque de sombra es una variación de la vulnerabilidad Meltdown. Este ataque afecta a los microprocesadores Intel debido a una debilidad a la que Intel se refiere como Falla de terminal L1 (L1TF). Mientras que el ataque de fusión original se basó en un retraso en la comprobación de permisos, Foreshadow se basa en la especulación que ocurre durante una etapa de la canalización llamada traducción de direcciones.
El software visualiza la memoria y los activos de almacenamiento de la computadora como un único tramo contiguo de memoria virtual propia. Pero físicamente, estos activos se dividen y comparten entre diferentes programas y procesos. La traducción de direcciones convierte una dirección de memoria virtual en una dirección de memoria física.
Los circuitos especializados en el microprocesador ayudan con la traducción de direcciones de memoria virtual a física, pero puede ser lenta y requerir múltiples búsquedas de memoria. Para acelerar las cosas, los microprocesadores Intel permiten especular durante el proceso de traducción, lo que permite a un programa leer de forma especulativa el contenido de una parte de la caché llamada L1, independientemente de quién posea esos datos. El atacante puede hacer esto y luego divulgar los datos utilizando el enfoque de canal lateral que ya describimos.
De alguna manera el presagio es más peligroso que la fusión, de otras maneras es menos. A diferencia de Meltdown, Foreshadow solo puede leer el contenido de la caché L1, debido a las características específicas de la implementación de Intel de su arquitectura de procesador. Sin embargo, Foreshadow puede leer cualquier contenido en L1, no solo datos direccionables por el programa.
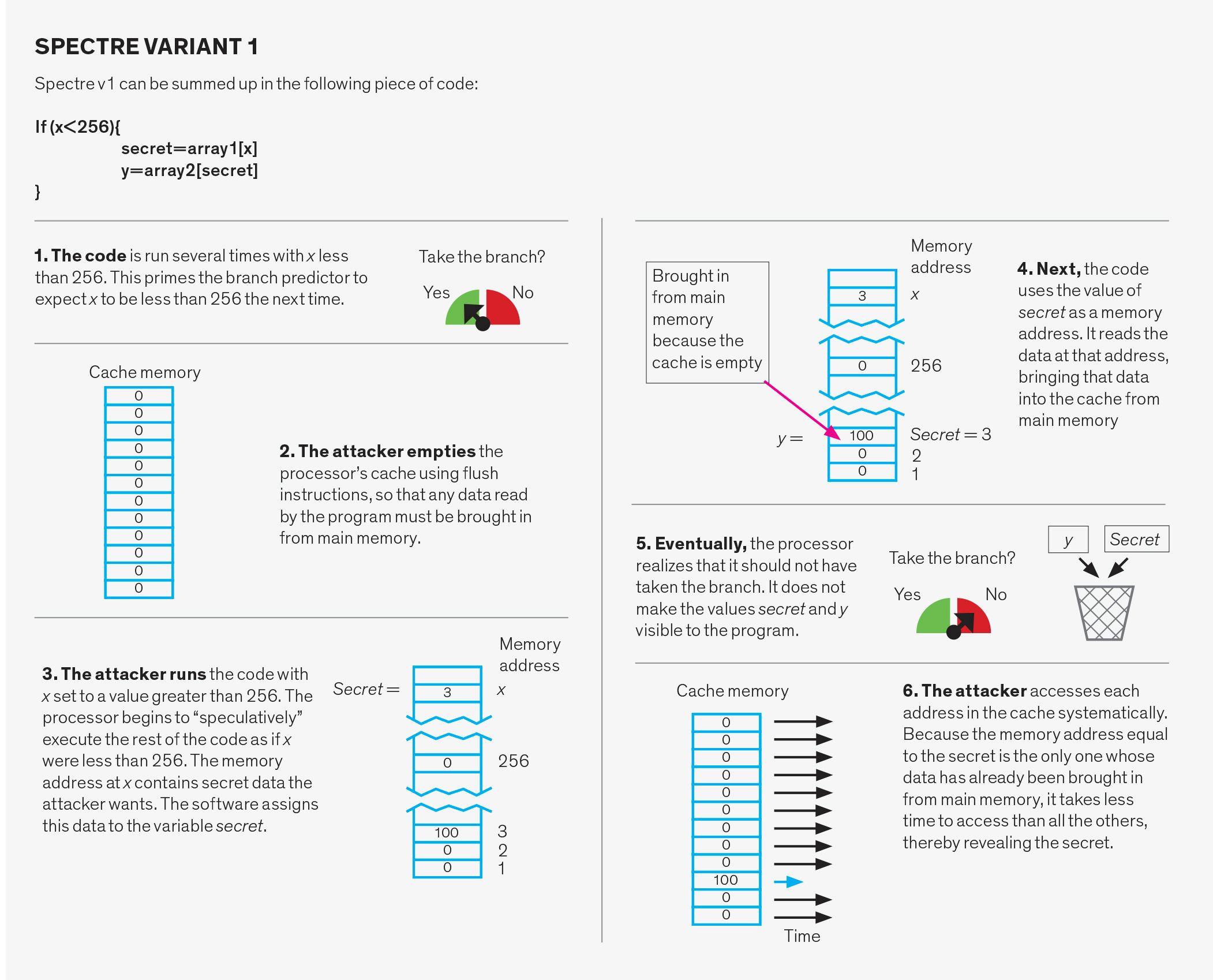
Ataques Spectre
Los ataques Spectre manipulan el sistema de predicción de ramas. Este sistema tiene tres partes: el predictor de dirección de rama, el predictor de destino de rama y el búfer de pila de retorno.
El predictor de dirección de rama predice si una rama condicional, como una utilizada para implementar una instrucción «if» en un lenguaje de programación, se tomará o no. Para hacer esto, rastrea el comportamiento anterior de ramas similares. Por ejemplo, puede significar que si una rama se toma dos veces seguidas, las predicciones futuras dirán que se debe tomar.
El predictor de destino de rama predice la dirección de memoria de destino de lo que se denominan ramas indirectas. En una rama condicional, se deletrea la dirección de la siguiente instrucción, pero para una rama indirecta esa dirección debe calcularse primero. El sistema que predice estos resultados es una estructura de caché llamada búfer de destino de rama. Esencialmente, realiza un seguimiento del último objetivo calculado de las ramas indirectas y las usa para predecir a dónde debería conducir la siguiente rama indirecta.
El búfer de pila de retorno se utiliza para predecir el destino de una instrucción de» retorno». Cuando se «llama» a una subrutina durante un programa, la instrucción de retorno hace que el programa se reanude en el punto desde el que se llamó a la subrutina. Intentar predecir el punto correcto al que volver basándose solo en direcciones de retorno anteriores no funcionará, porque se puede llamar a la misma función desde muchas ubicaciones diferentes en el código. En su lugar, el sistema utiliza el búfer de pila de retorno, una pieza de memoria en el procesador, que mantiene las direcciones de retorno de las funciones tal como se llaman. A continuación, utiliza estas direcciones cuando se encuentra un retorno en el código de la subrutina.
Cada una de estas tres estructuras puede explotarse de dos maneras diferentes. En primer lugar, el predictor puede ser deliberadamente erróneo. En este caso, el atacante ejecuta código aparentemente inocente diseñado para confundir al sistema. Más tarde, el atacante ejecuta deliberadamente una rama que no especula, haciendo que el programa salte a un fragmento de código elegido por el atacante, llamado gadget. El dispositivo entonces se pone a robar datos.
Una segunda forma de ataque de Espectro se denomina inyección directa. Resulta que, en algunas condiciones, los tres predictores se comparten entre diferentes programas. Lo que esto significa es que el programa atacante puede llenar las estructuras predictoras con datos incorrectos cuidadosamente seleccionados a medida que se ejecuta. Cuando una víctima involuntaria ejecuta su programa al mismo tiempo que el atacante o después, la víctima terminará usando el estado predictor que completó el atacante y activará un gadget sin saberlo. Este segundo ataque es particularmente preocupante porque permite que un programa víctima sea atacado desde un programa diferente. Esta amenaza es especialmente perjudicial para los proveedores de servicios en la nube, ya que no pueden garantizar que los datos de sus clientes estén protegidos.
Las vulnerabilidades Spectre y Meltdown presentaron un enigma para la industria informática porque la vulnerabilidad se origina en el hardware. En algunos casos, lo mejor que podemos hacer para los sistemas existentes, que constituyen la mayor parte de los servidores y PC instalados, es intentar reescribir el software para intentar limitar el daño. Pero estas soluciones son ad hoc, incompletas y, a menudo, resultan en un gran éxito para el rendimiento de la computadora. Al mismo tiempo, los investigadores y diseñadores de CPU han comenzado a pensar en cómo diseñar CPU futuras que mantengan la especulación sin comprometer la seguridad.
Una defensa, llamada kernel page-table isolation (KPTI) , ahora está integrada en Linux y otros sistemas operativos. Recuerde que cada aplicación ve la memoria y los activos de almacenamiento de la computadora como una única extensión contigua de memoria virtual propia. Pero físicamente, estos activos se dividen y comparten entre diferentes programas y procesos. La tabla de páginas es esencialmente el mapa del sistema operativo, diciéndole qué partes de una dirección de memoria virtual corresponden a qué direcciones de memoria física. La tabla de páginas del núcleo es responsable de hacer esto para el núcleo del sistema operativo. KPTI y sistemas similares se defienden contra la fusión al hacer que los datos secretos en la memoria, como el sistema operativo, sean inaccesibles cuando el programa de un usuario (y potencialmente el programa de un atacante) se está ejecutando. Para ello, elimina las partes prohibidas de la tabla de páginas. De esta manera, incluso el código ejecutado de forma especulativa no puede acceder a los datos. Sin embargo, esta solución significa trabajo adicional para el sistema operativo para mapear estas páginas cuando se ejecuta y desmapearlas después.
Otra clase de defensas ofrece a los programadores un conjunto de herramientas para limitar la especulación peligrosa. Por ejemplo, el parche Retpoline de Google reescribe el tipo de ramas que son vulnerables a la Variante 2 del Espectro, de modo que obliga a la especulación a apuntar a un gadget vacío y benigno. Los programadores también pueden agregar una instrucción de lenguaje ensamblador que limite Spectre v1, restringiendo las lecturas de memoria especulativa que siguen ramas condicionales. Convenientemente, esta instrucción ya está presente en la arquitectura del procesador y se usa para imponer el orden correcto entre las operaciones de memoria que se originan en diferentes núcleos del procesador.
Como diseñadores de procesadores, Intel y AMD tuvieron que ir más allá de un parche de software normal. Sus correcciones actualizan el microcódigo del procesador. El microcódigo es una capa de instrucciones que se ajusta entre el lenguaje ensamblador del software normal y los circuitos reales del procesador. El microcódigo añade flexibilidad al conjunto de instrucciones que un procesador puede ejecutar. También hace que sea más sencillo diseñar una CPU porque al usar microcódigo, las instrucciones complejas se traducen en múltiples instrucciones más simples que son más fáciles de ejecutar en una canalización.
Básicamente, Intel y AMD ajustaron su microcódigo para cambiar el comportamiento de algunas instrucciones en lenguaje ensamblador de manera que limitaran la especulación. Por ejemplo, los ingenieros de Intel agregaron opciones que interfieren con algunos de los ataques al permitir que el sistema operativo vacíe las estructuras predictoras de ramas en ciertas circunstancias.
Una clase diferente de soluciones intenta interferir con la capacidad del atacante para transmitir los datos a través de canales laterales. Por ejemplo, la tecnología DAWG del MIT divide de forma segura la caché del procesador para que los diferentes programas no compartan ninguno de sus recursos. Más ambiciosamente, hay propuestas para nuevas arquitecturas de procesador que introducirían estructuras en la CPU dedicadas a la especulación y separadas de la caché del procesador y otro hardware. De esta manera, las operaciones que se ejecutan de forma especulativa pero que no se comprometen finalmente nunca son visibles. Si se confirma el resultado de la especulación, los datos especulativos se envían a las estructuras principales del procesador.
Las vulnerabilidades de especulación han permanecido inactivas en los procesadores durante más de 20 años y, hasta donde nadie sabe, permanecieron sin explotar. Su descubrimiento ha sacudido sustancialmente la industria y ha puesto de relieve cómo la ciberseguridad no solo es un problema para los sistemas de software, sino también para el hardware. Desde el descubrimiento inicial, se han revelado alrededor de una docena de variantes de Spectre y Meltdown, y es probable que haya más. Spectre y Meltdown son, después de todo, efectos secundarios de principios de diseño básicos en los que hemos confiado para mejorar el rendimiento del equipo, lo que dificulta la eliminación de tales vulnerabilidades en los diseños de sistemas actuales. Es probable que los nuevos diseños de CPU evolucionen para retener la especulación, al tiempo que se evita el tipo de fuga de canal lateral que permite estos ataques. Sin embargo, los futuros diseñadores de sistemas informáticos, incluidos los que diseñan chips de procesador, deben ser conscientes de las implicaciones de seguridad de sus decisiones y ya no optimizar solo el rendimiento, el tamaño y la potencia.
Sobre el autor
Nael Abu-Ghazaleh es presidente del programa de ingeniería informática de la Universidad de California, Riverside. Dmitry Evtyushkin es profesor asistente de ciencias de la computación en el College of William and Mary, en Williamsburg, Virginia. Dmitry Ponomarev es profesor de informática en la Universidad Estatal de Nueva York en Binghamton.
Para investigar más
Paul Kocher y los otros investigadores que revelaron colectivamente Spectre lo explicaron aquí . Moritz Lipp explicó Meltdown en esta charla en Seguridad Usenix ‘ 18. Foreshadow se detalló en la misma conferencia.
Un grupo de investigadores, incluido uno de los autores, ha elaborado una evaluación sistemática de los ataques Spectre y Meltdown que descubre posibles ataques adicionales . Los ingenieros de IBM hicieron algo similar, y los ingenieros de Google llegaron recientemente a la conclusión de que los ataques de ejecución especulativa y de canal lateral han llegado para quedarse .