Uno sguardo in profondità a queste pericolose strumentalizzazioni delle microprocessore vulnerabilità e perché ci potrebbe essere più di loro là fuori

Siamo abituati a pensare ai processori per computer come macchine ordinate che procedono da una semplice istruzione all’altra con completa regolarità. Ma la verità è, che per decenni, hanno fatto i loro compiti fuori servizio e solo indovinando quello che dovrebbe venire dopo. Sono molto bravi, ovviamente. Così buono, infatti, che questa capacità, chiamata esecuzione speculativa, ha sostenuto gran parte del miglioramento della potenza di calcolo nel corso degli ultimi 25 anni o giù di lì. Ma il 3 gennaio 2018, il mondo ha appreso che questo trucco, che aveva fatto così tanto per l’informatica moderna, era ora una delle sue più grandi vulnerabilità.
Nel corso del 2017, i ricercatori di Cyberus Technology, Google Project Zero, Graz University of Technology, Rambus, University of Adelaide e University of Pennsylvania, oltre a ricercatori indipendenti come il crittografo Paul Kocher, hanno elaborato separatamente attacchi che hanno approfittato dell’esecuzione speculativa. Il nostro gruppo aveva scoperto la vulnerabilità originale dietro uno di questi attacchi nel 2016, ma non abbiamo messo tutti i pezzi insieme.
Questi tipi di attacchi, chiamati Meltdown e Spectre, non erano bug ordinari. Al momento è stato scoperto, Meltdown potrebbe incidere tutti i microprocessori Intel x86 e processori IBM Power, così come alcuni processori basati su ARM. Spectre e le sue numerose varianti hanno aggiunto processori Advanced Micro Devices (AMD) a tale elenco. In altre parole, quasi tutto il mondo dell’informatica era vulnerabile.
E poiché l’esecuzione speculativa è in gran parte cotta nell’hardware del processore, correggere queste vulnerabilità non è stato un lavoro facile. Farlo senza causare velocità di calcolo a macinare in marcia bassa ha reso ancora più difficile. Infatti, un anno dopo, il lavoro è tutt’altro che finito. Le patch di sicurezza erano necessarie non solo dai produttori di processori, ma da quelli più in basso nella catena di fornitura, come Apple, Dell, Linux e Microsoft. I primi computer alimentati da chip che sono intenzionalmente progettati per essere resistenti anche ad alcune di queste vulnerabilità sono arrivati solo di recente.
Spectre e Meltdown sono il risultato della differenza tra ciò che il software dovrebbe fare e la microarchitettura del processore—i dettagli di come effettivamente fa quelle cose. Queste due classi di hack hanno scoperto un modo per far trapelare informazioni attraverso quella differenza. E ci sono tutte le ragioni per credere che verranno scoperti altri modi. Abbiamo aiutato a trovare due, Branchscope e SpectreRSB, l’anno scorso.
Se vogliamo mantenere il ritmo dei miglioramenti informatici senza sacrificare la sicurezza, dovremo capire come si verificano queste vulnerabilità hardware. E questo inizia con la comprensione di Spectre e Meltdown.
Nei moderni sistemi informatici, i programmi software scritti in linguaggi comprensibili come il C++ sono compilati in istruzioni in linguaggio assembly-operazioni fondamentali che il processore del computer può eseguire. Per velocizzare l’esecuzione, i processori moderni utilizzano un approccio chiamato pipelining. Come una catena di montaggio, la pipeline è una serie di fasi, ognuna delle quali è un passaggio necessario per completare un’istruzione. Alcune fasi tipiche per un processore Intel x86 includono quelle che portano l’istruzione dalla memoria e la decodificano per capire cosa significa l’istruzione. Il pipelining porta fondamentalmente il parallelismo al livello di esecuzione delle istruzioni: quando un’istruzione viene eseguita utilizzando uno stage, l’istruzione successiva è libera di usarla.
Dal 1990, i microprocessori hanno fatto affidamento su due trucchi per accelerare il processo della pipeline: esecuzione fuori ordine e speculazione. Se due istruzioni sono indipendenti l’una dall’altra—cioè, l’output di una non influisce sull’input di un’altra—possono essere riordinate e il loro risultato sarà comunque corretto. Questo è utile, perché consente al processore di continuare a funzionare se un’istruzione si blocca nella pipeline. Ad esempio, se un’istruzione richiede dati che si trovano nella memoria principale DRAM piuttosto che nella memoria cache situata nella CPU stessa, potrebbero essere necessari alcune centinaia di cicli di clock per ottenere tali dati. Invece di aspettare, il processore può spostare un’altra istruzione attraverso la pipeline.
Il secondo trucco è la speculazione. Per capirlo, inizia con il fatto che alcune istruzioni portano necessariamente a un cambiamento in cui le istruzioni vengono dopo. Considera un programma contenente un’istruzione “if”: controlla una condizione e, se la condizione è vera, il processore passa a una posizione diversa nel programma. Questo è un esempio di un’istruzione di ramo condizionale, ma ci sono altre istruzioni che portano anche a cambiamenti nel flusso di istruzioni.
Considera ora cosa succede quando una tale istruzione di ramo entra in una pipeline. È una situazione che porta a un enigma. Quando l’istruzione arriva all’inizio della pipeline, non conosciamo il suo risultato finché non è progredita abbastanza in profondità nella pipeline. E senza conoscere questo risultato, non possiamo prendere l’istruzione successiva. Una soluzione semplice ma ingenua è impedire che nuove istruzioni entrino nella pipeline finché l’istruzione del ramo non raggiunge un punto in cui sappiamo da dove verrà l’istruzione successiva. Molti cicli di clock vengono sprecati in questo processo, poiché le pipeline hanno in genere da 15 a 25 stadi. Ancora peggio, istruzioni ramo venire abbastanza spesso, che rappresentano verso l’alto del 20 per cento di tutte le istruzioni in molti programmi.
Per evitare il costo elevato delle prestazioni di stallo della pipeline, i processori moderni utilizzano un’unità architettonica chiamata predittore di ramo per indovinare da dove verrà l’istruzione successiva, dopo un ramo. Lo scopo di questo predittore è quello di speculare su un paio di punti chiave. Innanzitutto, verrà preso un ramo condizionale, facendo sì che il programma si spenga in una sezione diversa del programma o continuerà sul percorso esistente? E in secondo luogo, se viene preso il ramo, dove andrà il programma-quale sarà la prossima istruzione? Armati di queste previsioni, la pipeline del processore può essere mantenuta piena.
Poiché l’esecuzione dell’istruzione si basa su una previsione, viene eseguita “speculativamente”: se la previsione è corretta, le prestazioni migliorano sostanzialmente. Ma se la previsione si rivela errata, il processore deve essere in grado di annullare gli effetti di eventuali istruzioni eseguite speculativamente in tempi relativamente brevi.
Il design del predittore di ramo è stato oggetto di ricerche approfondite nella comunità dell’architettura informatica per molti anni. I predittori moderni utilizzano la cronologia dell’esecuzione all’interno di un programma come base per i loro risultati. Questo schema raggiunge precisioni superiori al 95% su molti diversi tipi di programmi, portando a notevoli miglioramenti delle prestazioni, rispetto a un microprocessore che non specula. L’errata speculazione, tuttavia, è possibile. E sfortunatamente, è un errore di Spectre che gli attacchi Spectre sfruttano.
Un’altra forma di speculazione che ha portato a problemi è la speculazione all’interno di una singola istruzione nella pipeline. Questo è un concetto piuttosto astruso, quindi scompattiamolo. Supponiamo che un’istruzione richieda l’autorizzazione per l’esecuzione. Ad esempio, un’istruzione potrebbe indirizzare il computer a scrivere un blocco di dati nella porzione di memoria riservata al nucleo del sistema operativo. Non vorresti che ciò accadesse, a meno che non sia stato sanzionato dal sistema operativo stesso, o rischieresti di schiantare il computer. Prima della scoperta di Meltdown e Spectre, la saggezza convenzionale era che va bene iniziare a eseguire l’istruzione speculativamente anche prima che il processore abbia raggiunto il punto di verificare se l’istruzione ha il permesso di fare il suo lavoro.
Alla fine, se l’autorizzazione non è soddisfatta—nel nostro esempio, il sistema operativo non ha sanzionato questo tentativo di giocherellare con la sua memoria—i risultati vengono espulsi e il programma indica un errore. In generale, il processore può speculare su qualsiasi parte di un’istruzione che potrebbe causarne l’attesa, a condizione che la condizione venga eventualmente risolta e che qualsiasi risultato derivante da ipotesi errate venga effettivamente annullato. È questo tipo di speculazione intra-istruzione che sta dietro tutte le varianti del bug Meltdown, inclusa la sua versione probabilmente più pericolosa, Prefigurano.
L’intuizione che consente gli attacchi di speculazione è questa: durante la speculazione errata, non si verifica alcun cambiamento che un programma possa osservare direttamente. In altre parole, non esiste un programma che si possa scrivere che visualizzi semplicemente i dati generati durante l’esecuzione speculativa. Tuttavia, il fatto che la speculazione si sta verificando lascia tracce influenzando il tempo necessario per eseguire le istruzioni. E, sfortunatamente, ora è chiaro che possiamo rilevare questi segnali di temporizzazione ed estrarre dati segreti da loro.
Che cos’è questa informazione di temporizzazione e come fa un hacker a entrare in possesso di esso? Per capirlo, è necessario cogliere il concetto di canali laterali. Un canale laterale è un percorso non intenzionale che perde informazioni da un’entità all’altra (di solito entrambi sono programmi software), in genere attraverso una risorsa condivisa come un disco rigido o una memoria.
Come esempio di attacco a canale laterale, si consideri un dispositivo programmato per ascoltare il suono proveniente da una stampante e quindi utilizza quel suono per dedurre ciò che viene stampato. Il suono, in questo caso, è un canale laterale.
Nei microprocessori, qualsiasi risorsa hardware condivisa può, in linea di principio, essere utilizzata come canale laterale che perde informazioni da un programma vittima a un programma attaccante. In un attacco a canale laterale comunemente usato, la risorsa condivisa è la cache della CPU. La cache è una memoria relativamente piccola, ad accesso rapido sul chip del processore utilizzato per memorizzare i dati più frequentemente necessari da un programma. Quando un programma accede alla memoria, il processore prima controlla la cache; se i dati sono lì (un colpo di cache), viene recuperato rapidamente. Se i dati non sono nella cache (una mancanza), il processore deve attendere fino a quando non viene recuperato dalla memoria principale, che può richiedere diverse centinaia di cicli di clock. Ma una volta che i dati arrivano dalla memoria principale, vengono aggiunti alla cache, il che potrebbe richiedere il lancio di altri dati per fare spazio. La cache è divisa in segmenti chiamati set di cache e ogni posizione nella memoria principale ha un set corrispondente nella cache. Questa organizzazione rende facile verificare se qualcosa è nella cache senza dover cercare il tutto.
Gli attacchi basati sulla cache erano stati ampiamente studiati anche prima che Spectre e Meltdown apparissero sulla scena. Sebbene l’attaccante non possa leggere direttamente i dati della vittima, anche quando tali dati si trovano in una risorsa condivisa come la cache, l’attaccante può ottenere informazioni sugli indirizzi di memoria a cui accede dalla vittima. Questi indirizzi possono dipendere da dati sensibili, consentendo a un malintenzionato intelligente di recuperare questi dati segreti.
Come fa l’attaccante a farlo? Ci sono diversi modi possibili. Una variante, chiamata Flush e Reload, inizia con l’attaccante che rimuove i dati condivisi dalla cache utilizzando l’istruzione” flush”. L’attaccante attende quindi che la vittima acceda a tali dati. Poiché non è più nella cache, tutti i dati richiesti dalla vittima devono essere portati dalla memoria principale. Successivamente, l’attaccante accede ai dati condivisi mentre cronometra il tempo necessario. Un hit cache-il che significa che i dati sono tornati nella cache-indica che la vittima ha avuto accesso ai dati. Una mancanza di cache indica che i dati non sono stati accessibili. Quindi, semplicemente misurando quanto tempo ci è voluto per accedere ai dati, l’attaccante può determinare quali set di cache sono stati accessibili dalla vittima. Ci vuole un po ‘ di magia algoritmica, ma questa conoscenza di quali set di cache sono stati accessibili e che non erano può portare alla scoperta di chiavi di crittografia e altri segreti.
Meltdown, Spectre e le loro varianti seguono tutti lo stesso schema. In primo luogo, innescano la speculazione per eseguire il codice desiderato dall’attaccante. Questo codice legge i dati segreti senza autorizzazione. Quindi, gli attacchi comunicano il segreto usando Flush e Reload o un canale laterale simile. Quest’ultima parte è ben compresa e simile in tutte le varianti di attacco. Pertanto, gli attacchi differiscono solo nel primo componente, che è come innescare e sfruttare la speculazione.
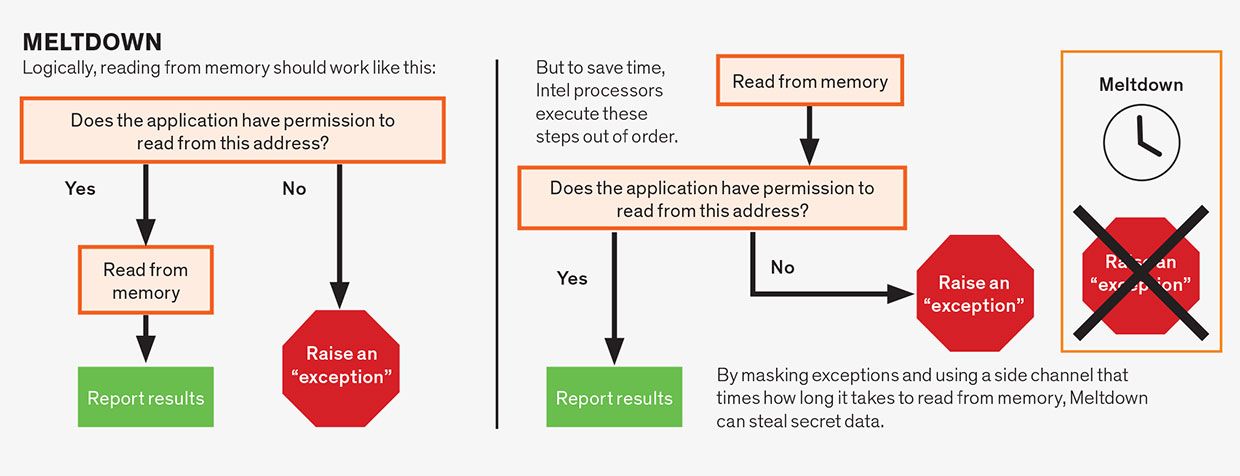
Attacchi Meltdown
Attacchi Meltdown sfruttano la speculazione all’interno di una singola istruzione. Sebbene le istruzioni in linguaggio assembly siano in genere semplici, una singola istruzione spesso consiste in più operazioni che possono dipendere l’una dall’altra. Ad esempio, le operazioni di lettura della memoria dipendono spesso dall’istruzione che soddisfa le autorizzazioni associate all’indirizzo di memoria letto. Un’applicazione di solito ha il permesso di leggere solo dalla memoria che è stata assegnata ad essa, non dalla memoria allocata, ad esempio, al sistema operativo o al programma di un altro utente. Logicamente, dovremmo controllare le autorizzazioni prima di consentire la lettura di procedere, che è ciò che fanno alcuni microprocessori, in particolare quelli di AMD. Tuttavia, a condizione che il risultato finale sia corretto, i progettisti della CPU presumevano di essere liberi di eseguire speculativamente queste operazioni fuori servizio. Pertanto, i microprocessori Intel leggono la posizione di memoria prima di controllare le autorizzazioni, ma solo “commit” l’istruzione—rendendo i risultati visibili al programma—quando le autorizzazioni sono soddisfatte. Ma poiché i dati segreti sono stati recuperati speculativamente, possono essere scoperti utilizzando un canale laterale, rendendo i processori Intel vulnerabili a questo attacco.
L’attacco Foreshadow è una variante della vulnerabilità Meltdown. Questo attacco colpisce i microprocessori Intel a causa di una debolezza che Intel si riferisce a come L1 Terminal Fault (L1TF). Mentre l’attacco Meltdown originale si basava su un ritardo nel controllo delle autorizzazioni, Foreshadow si basa sulla speculazione che si verifica durante una fase della pipeline chiamata address translation.
Il software visualizza le risorse di memoria e archiviazione del computer come un singolo tratto contiguo di memoria virtuale tutto suo. Ma fisicamente, queste risorse sono divise e condivise tra diversi programmi e processi. Address translation trasforma un indirizzo di memoria virtuale in un indirizzo di memoria fisica.
I circuiti specializzati sul microprocessore aiutano con la traduzione di indirizzi di memoria da virtuale a fisico, ma può essere lenta, richiedendo più ricerche di memoria. Per accelerare le cose, i microprocessori Intel consentono speculazioni durante il processo di traduzione, consentendo a un programma di leggere speculativamente il contenuto di una parte della cache chiamata L1 indipendentemente da chi possiede quei dati. L’attaccante può farlo e quindi rivelare i dati utilizzando l’approccio del canale laterale che abbiamo già descritto.
In qualche modo Prefigurare è più pericoloso di Meltdown, in altri modi è meno. A differenza di Meltdown, Foreshadow può leggere il contenuto solo della cache L1, a causa delle specifiche dell’implementazione di Intel della sua architettura del processore. Tuttavia, Foreshadow può leggere qualsiasi contenuto in L1 – non solo i dati indirizzabili dal programma.
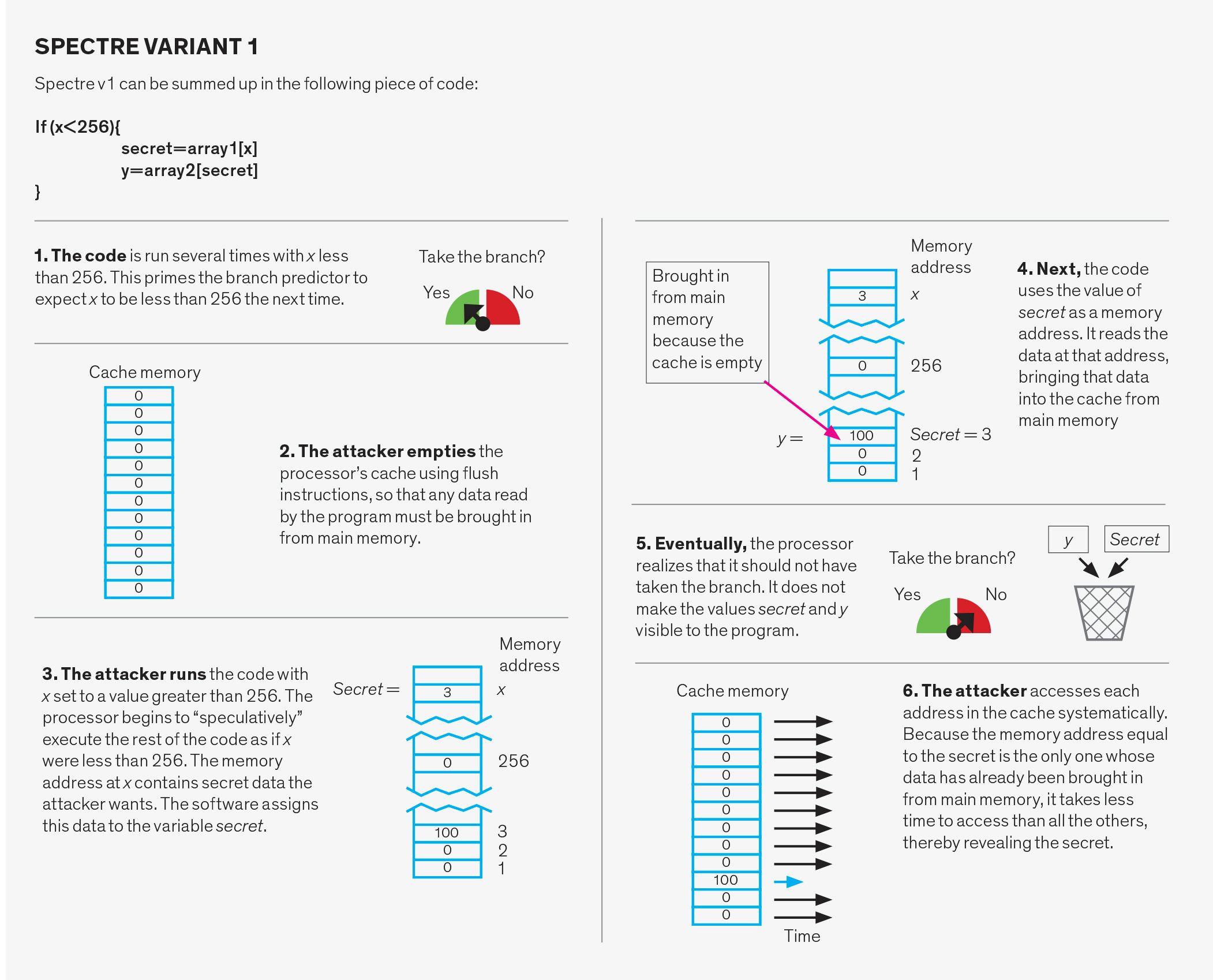
Attacchi Spectre
Gli attacchi Spectre manipolano il sistema di predizione dei rami. Questo sistema ha tre parti: il predittore di direzione del ramo, il predittore di destinazione del ramo e il buffer dello stack di ritorno.
Il predittore di diramazione predice se un ramo condizionale, come quello utilizzato per implementare un’istruzione “if” in un linguaggio di programmazione, verrà preso o meno. Per fare ciò, tiene traccia del comportamento precedente di rami simili. Ad esempio, può significare che se un ramo viene preso due volte di seguito, le previsioni future diranno che dovrebbe essere preso.
Il predittore branch-target predice l’indirizzo di memoria di destinazione dei cosiddetti rami indiretti. In un ramo condizionale, l’indirizzo dell’istruzione successiva viene specificato, ma per un ramo indiretto tale indirizzo deve essere calcolato per primo. Il sistema che prevede questi risultati è una struttura di cache chiamata branch-target buffer. Essenzialmente, tiene traccia dell’ultimo target calcolato dei rami indiretti e li usa per prevedere dove dovrebbe portare il prossimo ramo indiretto.
Il buffer dello stack di ritorno viene utilizzato per prevedere il target di un’istruzione “return”. Quando una subroutine viene” chiamata ” durante un programma, l’istruzione return fa sì che il programma riprenda il lavoro nel punto da cui è stata chiamata la subroutine. Cercare di prevedere il punto giusto per tornare in base solo agli indirizzi di ritorno precedenti non funzionerà, perché la stessa funzione può essere chiamata da molte posizioni diverse nel codice. Invece, il sistema utilizza il buffer dello stack di ritorno, un pezzo di memoria sul processore, che mantiene gli indirizzi di ritorno delle funzioni come vengono chiamate. Utilizza quindi questi indirizzi quando viene rilevato un ritorno nel codice della subroutine.
Ognuna di queste tre strutture può essere sfruttata in due modi diversi. Innanzitutto, il predittore può essere deliberatamente maltrattato. In questo caso, l’attaccante esegue codice apparentemente innocente progettato per confondere il sistema. Successivamente, l’utente malintenzionato esegue deliberatamente un ramo che verrà specificato in modo errato, facendo sì che il programma salti su un pezzo di codice scelto dall’utente malintenzionato, chiamato gadget. Il gadget quindi imposta il furto di dati.
Un secondo modo di attacco Spectre è chiamato iniezione diretta. Si scopre che in alcune condizioni i tre predittori sono condivisi tra diversi programmi. Ciò significa che il programma attaccante può riempire le strutture predittive con dati errati scelti con cura durante l’esecuzione. Quando una vittima inconsapevole esegue il proprio programma contemporaneamente all’attaccante o in seguito, la vittima finirà per utilizzare lo stato predittivo che è stato compilato dall’attaccante e involontariamente innescato un gadget. Questo secondo attacco è particolarmente preoccupante perché consente a un programma vittima di essere attaccato da un programma diverso. Tale minaccia è particolarmente dannosa per i fornitori di servizi cloud perché non possono quindi garantire che i loro dati dei clienti siano protetti.
Le vulnerabilità Spectre e Meltdown hanno presentato un enigma per l’industria informatica perché la vulnerabilità ha origine nell’hardware. In alcuni casi il meglio che possiamo fare per i sistemi esistenti—che costituiscono la maggior parte dei server e dei PC installati—è cercare di riscrivere il software per tentare di limitare i danni. Ma queste soluzioni sono ad hoc, incomplete, e spesso si traducono in un grande successo per le prestazioni del computer. Allo stesso tempo, ricercatori e progettisti di CPU hanno iniziato a pensare a come progettare le CPU future che mantengono la speculazione senza compromettere la sicurezza.
Una difesa, chiamata kernel page-table Isolation (KPTI) , è ora integrata in Linux e in altri sistemi operativi. Ricordiamo che ogni applicazione visualizza le risorse di memoria e archiviazione del computer come un singolo tratto contiguo di memoria virtuale tutto suo. Ma fisicamente, queste risorse sono divise e condivise tra diversi programmi e processi. La tabella delle pagine è essenzialmente la mappa del sistema operativo, che indica quali parti di un indirizzo di memoria virtuale corrispondono a quali indirizzi di memoria fisica. La tabella delle pagine del kernel è responsabile di fare questo per il nucleo del sistema operativo. KPTI e sistemi simili difendono da Meltdown rendendo i dati segreti in memoria, come il sistema operativo, inaccessibili quando il programma di un utente (e potenzialmente il programma di un utente malintenzionato) è in esecuzione. Lo fa rimuovendo le parti proibite dalla tabella delle pagine. In questo modo, anche il codice eseguito speculativamente non può accedere ai dati. Tuttavia, questa soluzione significa lavoro extra per il sistema operativo per mappare queste pagine quando viene eseguito e unmap in seguito.
Un’altra classe di difese offre ai programmatori una serie di strumenti per limitare la speculazione pericolosa. Ad esempio, la patch Retpoline di Google riscrive il tipo di rami vulnerabili alla variante Spectre 2, in modo da costringere la speculazione a indirizzare un gadget benigno e vuoto. I programmatori possono anche aggiungere un’istruzione in linguaggio assembly che limita Spectre v1, limitando le letture di memoria speculative che seguono i rami condizionali. Convenientemente, questa istruzione è già presente nell’architettura del processore e viene utilizzata per imporre l’ordine corretto tra le operazioni di memoria originate da diversi core del processore.
Come i progettisti del processore, Intel e AMD hanno dovuto andare più in profondità di una normale patch software. Le loro correzioni aggiornano il microcodice del processore. Il microcodice è uno strato di istruzioni che si inserisce tra il linguaggio assembly del software normale e la circuiteria effettiva del processore. Microcode aggiunge flessibilità al set di istruzioni che un processore può eseguire. Rende anche più semplice progettare una CPU perché quando si utilizza il microcodice, le istruzioni complesse vengono tradotte in più istruzioni più semplici che sono più facili da eseguire in una pipeline.
Fondamentalmente, Intel e AMD hanno regolato il loro microcodice per modificare il comportamento di alcune istruzioni in linguaggio assembly in modi che limitano la speculazione. Ad esempio, gli ingegneri Intel hanno aggiunto opzioni che interferiscono con alcuni degli attacchi consentendo al sistema operativo di svuotare le strutture dei predittori di ramo in determinate circostanze.
Una diversa classe di soluzioni tenta di interferire con la capacità dell’attaccante di trasmettere i dati utilizzando i canali laterali. Ad esempio, la tecnologia DAWG del MIT divide in modo sicuro la cache del processore in modo che diversi programmi non condividano nessuna delle sue risorse. Più ambiziosamente, ci sono proposte per nuove architetture di processore che introdurrebbero strutture sulla CPU dedicate alla speculazione e separate dalla cache del processore e da altri hardware. In questo modo, tutte le operazioni che vengono eseguite speculativamente ma che alla fine non vengono commesse non sono mai visibili. Se il risultato della speculazione è confermato, i dati speculativi vengono inviati alle strutture principali del processore.
Le vulnerabilità speculative sono rimaste dormienti nei processori per oltre 20 anni e sono rimaste, per quanto qualcuno sappia, non sfruttate. La loro scoperta ha sostanzialmente scosso l’industria e ha evidenziato come la sicurezza informatica non sia solo un problema per i sistemi software ma anche per l’hardware. Dalla scoperta iniziale, sono state rivelate circa una dozzina di varianti di Spectre e Meltdown, ed è probabile che ce ne siano altre. Spectre e Meltdown sono, dopo tutto, effetti collaterali dei principi di progettazione di base su cui abbiamo fatto affidamento per migliorare le prestazioni del computer, rendendo difficile eliminare tali vulnerabilità nei progetti di sistema attuali. È probabile che i nuovi progetti di CPU si evolveranno per mantenere la speculazione, evitando al tempo stesso il tipo di perdita del canale laterale che consente questi attacchi. Tuttavia, i futuri progettisti di sistemi informatici, compresi quelli che progettano chip del processore, devono essere consapevoli delle implicazioni di sicurezza delle loro decisioni e non ottimizzare più solo per prestazioni, dimensioni e potenza.
Circa l’autore
Nael Abu-Ghazaleh è presidente del programma di ingegneria informatica presso l’Università della California, Riverside. Dmitry Evtyushkin è un assistente professore di informatica presso il College of William and Mary, a Williamsburg, Va. Dmitry Ponomarev è un professore di informatica presso l’Università Statale di New York a Binghamton.
Per sondare ulteriormente
Paul Kocher e gli altri ricercatori che hanno divulgato collettivamente Spectre lo hanno spiegato per la prima volta qui . Moritz Lipp ha spiegato Meltdown in questo discorso a Usenix Security ‘ 18. Foreshadow è stato dettagliato nella stessa conferenza.
Un gruppo di ricercatori tra cui uno degli autori ha elaborato una valutazione sistematica degli attacchi Spectre e Meltdown che scopre ulteriori potenziali attacchi . Gli ingegneri IBM hanno fatto qualcosa di simile e gli ingegneri di Google sono giunti di recente alla conclusione che gli attacchi a canale laterale e di esecuzione speculativa sono qui per rimanere .