学習目標
- オペラント条件付けの原則を概説する。
- 補強スケジュールと二次補強材を使用して、学習をどのように形作ることができるかを説明します。
古典的なコンディショニングでは、生物は新しい刺激を唾液分泌や恐怖などの自然な生物学的応答と関連付けることを学びます。 生物は何か新しいことを学ぶのではなく、新しい信号の存在下で既存の行動を実行し始めます。 一方、オペラント条件付けは、行動の結果に基づいて発生する学習であり、新しい行動の学習を伴う可能性があります。 オペラントのコンディショニングは、過去にそうしていることで賞賛されているために犬がコマンドをロールオーバーしたとき、そうすることで彼が彼の道を得ることができるので、教室のいじめっ子がクラスメートを脅かすとき、そして彼女の両親が彼女がしなければ彼女を罰すると脅しているので子供が良い成績を得るときに発生します。 オペラント条件付けでは、生物はそれ自身の行動の結果から学ぶ。
強化と罰が行動にどのように影響するか:ThorndikeとSkinnerの研究
心理学者Edward L.Thorndike(1874-1949)は、オペラント条件付けを体系的に研究した最初の科学者でした。 彼の研究では、ソーンダイク(1898)は、彼らが脱出しようとした”パズルボックス”に置かれていた猫を観察した(”ビデオクリップ:ソーンダイクのパズルボックス”)。 最初は、猫は出て行く方法の任意のアイデアなしで、無計画に引っ掻き、ビット、およびswatted。 しかし、最終的に、そして誤って、彼らはドアを開け、彼らの賞、魚のスクラップに出たレバーを押しました。 次に猫が箱の中に拘束されたとき、それは成功した脱出を実行する前に無効な応答の少ないを試み、いくつかの試験の後、猫はほとんどすぐに正しい応答を行うことを学びました。
これらの猫の行動の変化を観察することにより、Thorndikeは、特定の状況で典型的に楽しい結果をもたらす応答は、同様の状況で再び発生する可能性が高いのに対し、典型的に不快な結果をもたらす応答は、状況で再び発生する可能性が低いという効果の法則を開発した(Thorndike、1911)。 効果の法則の本質は、彼らが楽しいので、成功した応答は、経験によって”スタンプ”され、したがって、より頻繁に発生するということです。 不快な経験を生成する失敗した応答は、”スタンプアウト”され、その後、あまり頻繁に発生します。
ソーンダイクが猫をパズルボックスに入れたとき、彼は各試行の後、彼らが重要な脱出行動に迅速に従事することを学んだことを発見しました。 ソーンダイクは、効果の法則の観点から強化に従う学習を説明しました。
 ウォッチ:”ソーンダイクのパズルボックス” : http://www.youtube.com/watch?v=BDujDOLre-8
ウォッチ:”ソーンダイクのパズルボックス” : http://www.youtube.com/watch?v=BDujDOLre-8
影響力のある行動心理学者B.F. スキナー(1904年-1990年)は、オペラント条件付けを説明するためのより完全な原則のセットを開発するためにソーンダイクのアイデアに拡大しました。 スキナーは、体系的に学習を研究するためにオペラント室(通常はスキナーボックスと呼ばれる)として知られている特別に設計された環境を作 スキナーボックス(オペラント室)は、げっ歯類や鳥に適合するのに十分な大きさであり、生物が食物や水を放出するために押すか、またはつつくことがで また、動物の応答を記録するためのデバイスも含まれています(図8.5)。
スキナーの実験の最も基本的なものは、ソーンダイクの猫の研究と非常によく似ていた。 部屋の中に置かれたネズミは期待通りに反応し、箱の周りを慌て、床と壁を嗅ぎ、爪を立てました。 最終的にラットはレバーに偶然遭遇し、それは食物のペレットを放出するために押した。 次に、ラットはレバーを押すのに少し時間がかかり、連続した試行では、レバーを押すのにかかった時間が短くなりました。 すぐにラットは早くそれが現れた食べ物を食べることができるようにレバーを押していた。 効果の法則によって予測されるように、ラットは食物をもたらした行動を繰り返し、そうでない行動を止めることを学んだ。
スキナーは、動物が強化と罰によって行動をどのように変化させたかを詳細に研究し、オペラント学習のプロセスを説明する用語を開発しました(表8.1、”正と負の強化と罰が行動にどのように影響するか”)。 スキナーは、行動の可能性を強化または増加させるイベントを指すためにreinforcerという用語を使用し、行動の可能性を弱めるか減少させるイベントを指すためにpunisherという用語を使用した。 そして、彼は補強がそれぞれ提示されたか削除されたかどうかを指すために、正と負の用語を使用しました。 従って、肯定的な補強は応答の後で気持が良い何かを示すことによって応答を増強し、否定的な補強は不愉快な何かを減らすか、または取除くことに 例えば、彼の宿題を完了するための子供の賞賛を与えることは肯定的な強化を表し、頭痛の痛みを軽減するためにアスピリンを服用することは否定的な強化を表す。 どちらの場合も、強化により、将来的に行動が再び発生する可能性が高くなります。

| オペラント条件付け用語 | 説明 | 結果 | 例 |
|---|---|---|---|
| 肯定的な強化 | 楽しい刺激を追加または増加させる | 行動が強化される | テストでAを取得した後、学生に賞を与える |
| 負の強化 | 不快な刺激を軽減または除去 | 行動が強化される | 痛みを排除する鎮痛剤を服用すると、あなたが取る可能性が高くなります 再び鎮痛剤 |
| 肯定的な罰 | 不快な刺激を提示または追加する | 行動が弱まっている | クラスで不正な動作をした後、生徒に余分な宿題を与える |
| 否定的な罰 | 楽しい刺激を減らすか取り除く | 行動が弱まる | 夜間外出禁止令を逃した後に十代のコンピュータを奪う |
正または負のいずれかの補強は、行動の可能性を高めることによって機能します。 一方、罰は、行動の可能性を弱めるか、または減少させるあらゆる出来事を指します。 肯定的な罰は応答の後で不愉快な何かを示すことによって応答を弱める否定的な罰は気持が良い何かを減らすか、または取除くことによって応答 兄弟と戦った後に接地されている子供(肯定的な罰)または貧しい等級(否定的な罰)を得た後に休憩に行く機会を失う子供は、これらの行動を繰り返す可
強化(行動を増加させる)と罰(それを減少させる)の区別は通常明らかですが、強化者が正か負かを判断することは困難な場合もあります。 暑い日には、涼しい風が肯定的な補強材(冷たい空気を取り込むため)または否定的な補強材(熱い空気を取り除くため)として見ることができます。 他の場合には、補強は正と負の両方になる可能性があります。 それは喜び(正の強化)をもたらすので、それはニコチン(負の強化)のための渇望を排除するので、一つは、タバコを吸うことができます。
強化と罰は単に反対ではないことに注意することも重要です。 行動の変化に積極的な強化を使用することは、ほとんどの場合、罰を使用するよりも効果的です。 これは肯定的な補強が人か動物をよりよく感じさせ、補強を提供する人との肯定的な関係を作成するのを助けるのである。 日常生活に効果的な肯定的な強化の種類には、口頭での賞賛または承認、地位または威信の授与、および直接的な財政的支払いが含まれます。 一方、罰は強制に基づいており、通常は補強を提供する人との否定的で敵対的な関係を作成するため、行動の一時的な変化のみを作成する可能性が高 罰を提供する人が状況を離れると、望ましくない行動が戻る可能性があります。
オペラント条件付けによる複雑な行動の作成
おそらく、あなたは映画を見たり、動物—多分犬、馬、またはイルカ—がかなり素晴らしいことをしたショー トレーナーはコマンドを与え、イルカはプールの底に泳いで、その鼻のリングを拾い、空気中のフープを介して水から飛び出し、プールの底に再びダイビングし、別のリングを拾い、その後、プールの端にあるトレーナーにリングの両方を取った。 動物はトリックを行うように訓練され、オペラント条件付けの原則がそれを訓練するために使用されました。 しかし、これらの複雑な行動は、私たちがこれまでに考えてきた単純な刺激応答の関係からは程遠いものです。 このような複雑な行動を作成するために補強をどのように使用できますか?
オペラント学習の使用を拡大する1つの方法は、補強が適用されるスケジュールを変更することです。 この時点までに、我々は唯一の所望の応答は、それが発生するたびに強化されている継続的な補強スケジュールを、議論してきました; 犬が転がるたびに、例えば、それはビスケットを取得します。 連続的な補強はreinforcerが消えたら望ましい行動の比較的速い学習しかしまた急速な絶滅で起因する。 問題は、生物はすべての行動の後に補強を受けることに慣れているので、応答者は現れないときにすぐにあきらめるかもしれないということです。
ほとんどの現実世界の補強材は連続的ではなく、部分的な(または間欠的な)補強スケジュールで発生します-応答が時々補強され、時には補強されないスケジュー 連続的な補強と比較して、部分的な補強スケジュールは初期学習を遅くしますが、絶滅に対するより大きな抵抗にもつながります。 強化はすべての行動の後に現れるわけではないので、学習者が報酬がもはや来ていないと判断するのに時間がかかり、したがって絶滅は遅くな 部分補強スケジュールの四つのタイプは、表8.2″補強スケジュール”に要約されています。”
| 補強スケジュール | 説明 | 実世界の例 |
|---|---|---|
| 固定比 | 特定の数の応答の後に動作が強化されます。 | 生産する製品の数に応じて支払われる工場労働者 |
| 可変比 | 行動は、平均的ではあるが予測不可能な応答数の後に強化されます。 | スロットマシンやチャンスの他のゲームからのペイオフ |
| 固定間隔 | の動作は、特定の時間が経過した後の最初の応答に対して強化されます。 | 月給を稼ぐ人 |
| 可変間隔 | の動作は、平均ではあるが予測不可能な時間が経過した後の最初の応答に対して強化されます。 | メールをチェックしている人 |
部分的な補強スケジュールは、補強が補強の間の経過時間(間隔)に基づいて提示されるか、生物が関与する応答の数(比率)に基づいて提示されるか、補強が 固定間隔のスケジュールでは、特定の時間が経過した後に行われた最初の応答に対して補強が行われます。 例えば、1分間の固定間隔のスケジュールでは、動物は1分間に少なくとも1回は行動に従事すると仮定して、毎分補強を受けます。 図8.6″異なる部分補強スケジュールの下で訓練された動物による応答パターンの例”でわかるように、固定間隔スケジュールの下での動物は、補強の直後に応答を遅くする傾向がありますが、次の補強の時間が近づくにつれて再び行動を増加させる傾向があります。 (ほとんどの学生は同じように試験のために勉強します。)可変間隔スケジュールでは、補強子は間隔スケジュールに表示されますが、タイミングは平均間隔の周りで変化し、補強子の実際の外観は予測できません。 たとえば、あなたの電子メールをチェックすることがあります:あなたは、平均して、たとえば、30分ごとに来るメッセージを受信することによって強化され 間隔の補強のスケジュールは応答の遅く、安定した率を作り出しがちである。
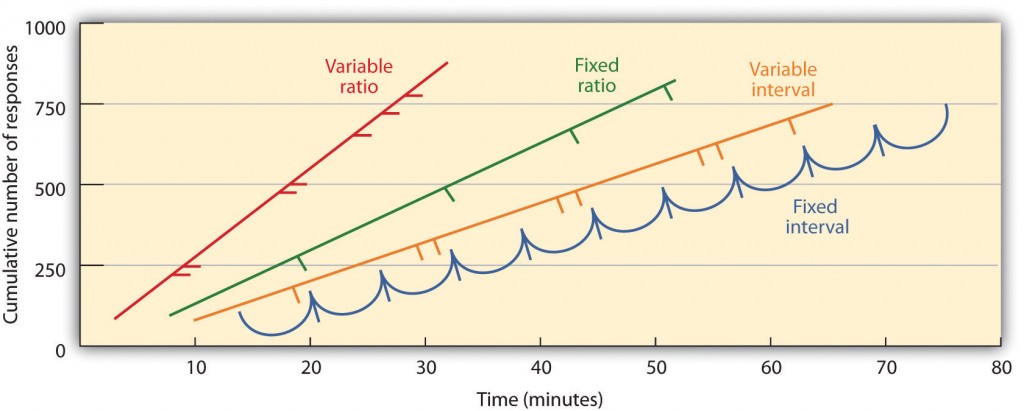
固定比率のスケジュールでは、特定の数の応答の後に行動が強化されます。 たとえば、ラットの行動は、キーを20回押した後に強化されたり、10個の製品を販売した後に営業担当者がボーナスを受け取ることがあります。 図8に示すように。6、”異なる部分強化スケジュールの下で訓練された動物による応答パターンの例”生物は、固定比スケジュールに従って行動することを学んだ後、強化が高レベ 可変比率のスケジュールは応答の特定しかし平均数の後でreinforcersを提供する。 スロットマシンから、または宝くじでお金を獲得することは、可変比率のスケジュールで発生する強化の例です。 例えば、スロットマシン(図8を参照。7、”スロットマシン”)は、平均して、ユーザがハンドルを引っ張る20回ごとに勝利を提供するようにプログラムすることができます。 比率のスケジュールは応答の数が増加すると同時に補強が増加するので応答の高い比率を作り出しがちである。

複雑な行動は、最終的な所望の行動への逐次近似を使用することによって、生物の行動を所望の結果に導くプロセスである整形によっても作 スキナーは彼の箱のこのプロシージャの広範な使用をした。 例えば、彼は動物がバーの近くに移動したときに最初に食べ物を提供することによって、食べ物を受け取るためにバーを2回押すようにラットを訓練す その行動が学習されたとき、スキナーはラットがバーに触れたときにのみ食べ物を提供し始めるだろう。 さらに成形すると、ラットがバーを押したときにのみ、バーを押して二度目に触れたときにのみ、最終的にバーを二度押したときにのみ補強が制限されました。 それは長い時間がかかることができますが、このようにオペラント条件付けは、彼らが完了したときにのみ強化されている行動のチェーンを作成することができます。
同様の刺激を正しく区別すれば、動物を強化することで、科学者は動物の学習能力をテストすることができ、彼らが作ることができる差別は時々顕著 ハトは、チャーリー-ブラウンと他のピーナッツのキャラクター(Cerella、1980)のイメージと、音楽と芸術の異なるスタイル(Porter&Neuringer、1984)の間を区別するように訓練されています; 渡辺,坂本&脇田,1995).
行動は、二次補強材を使用して訓練することもできます。 第一次reinforcerが自然に好まれるか、または有機体によって、食糧、水および苦痛からの救助のような楽しまれる刺激を含んでいる一方、第二次reinforcerは(時々調節されたreinforcerと呼 二次補強の例は、動物のトレーナーによって与えられた笛であり、これは時間の経過とともに一次補強、食物と関連している。 毎日の二次補強の例はお金です。 私たちは、刺激自体のためではなく、むしろそれが関連している主要な強化者(お金が買うことができるもの)のために、お金を持つことを楽しんでい
主要な注意
- Edward Thorndikeは効果の法則を開発しました:特定の状況で典型的に楽しい結果を生み出す応答は、同様の状況で再び発生する可能性が高いのに対し、典型的に不快な結果を生み出す応答は、状況で再び発生する可能性が低いという原則です。
- スキナーはソーンダイクのアイデアを拡張し、オペラント条件付けを説明する一連の原則を開発した。
- 正の強化は、応答の後に典型的に楽しいものを提示することによって応答を強化し、負の強化は、典型的に不快なものを減少または除去することによ
- 肯定的な罰は、応答の後に典型的に不快なものを提示することによって応答を弱めるのに対し、否定的な罰は、典型的に快適なものを減少または除去
- 補強は、部分的または連続的ないずれかであることができます。 部分的な補強スケジュールは、補強が補強の間の経過時間(間隔)に基づいて提示されるか、生物が関与する応答の数(比率)に基づいて提示されるか、補強が
- 複雑な行動は、最終的な所望の行動への逐次近似を使用することによって、生物の行動を所望の結果に導くプロセスである整形によって作成され
練習と批判的思考
- 次のそれぞれの日常生活からの例を与えます:肯定的な強化、否定的な強化、肯定的な罰、否定的な罰。
- あなたが投げるフリスビーを捕まえて取り出すために犬を訓練するために使用する可能性のある補強技術を考えてみましょう。
- 現在のテレビ番組から以下の二つのビデオを見る。 どの学習手順が実証されているかを判断できますか?
- オフィス:http://www.break.com/usercontent/2009/11/the-office-altoid-実験-1499823
- ビッグバン理論: http://www.youtube.com/watch?v=JA96Fba-WHk
Cerella,J.(1980). 写真の鳩の分析。 パターン認識、12、1-6。
Thorndike,E.L.(1898). 動物知能(Animal intelligence):動物における連想過程の実験的研究。 ワシントンD.C.:アメリカの心理学協会。
画像属性
図8.6: 2003年(平成15年)から放送されている。