een data warehouse is een elektronisch systeem dat gegevens verzamelt uit een breed scala aan bronnen binnen een bedrijf en de gegevens gebruikt om managementbeslissingen te ondersteunen.
bedrijven bewegen zich steeds meer naar cloudgebaseerde datawarehouses in plaats van traditionele on-premise systemen. Cloud-based data warehouses verschillen van traditionele warehouses op de volgende manieren:
- er is geen noodzaak om fysieke hardware te kopen.
- het is sneller en goedkoper om clouddatawarehouses op te zetten en te schalen.
- cloudgebaseerde datawarehouse-architecturen kunnen doorgaans veel sneller complexe analytische query ‘ s uitvoeren omdat ze gebruikmaken van massively parallel processing (MPP).
de rest van dit artikel behandelt de traditionele architectuur van datawarehouses en introduceert enkele architectonische ideeën en concepten die worden gebruikt door de meest populaire cloudgebaseerde datawarehouseservices.
voor meer details, zie onze pagina over Data warehouse concepten in deze gids.
- traditionele datawarehouse-architectuur
- Three-Tier architectuur
- Kimball vs. Inmon
- datawarehouse-modellen
- Star Schema vs. Snowflake Schema
- ETL vs. ELT
- organisatorische volwassenheid
- nieuwe datawarehouse-architecturen
- Amazon Redshift
- Google BigQuery
- Panoply
- Clouddatawarehouses
- meer informatie over datawarehouses
traditionele datawarehouse-architectuur
de volgende concepten benadrukken enkele van de gevestigde ideeën en ontwerpprincipes die worden gebruikt voor het bouwen van traditionele datawarehouses.
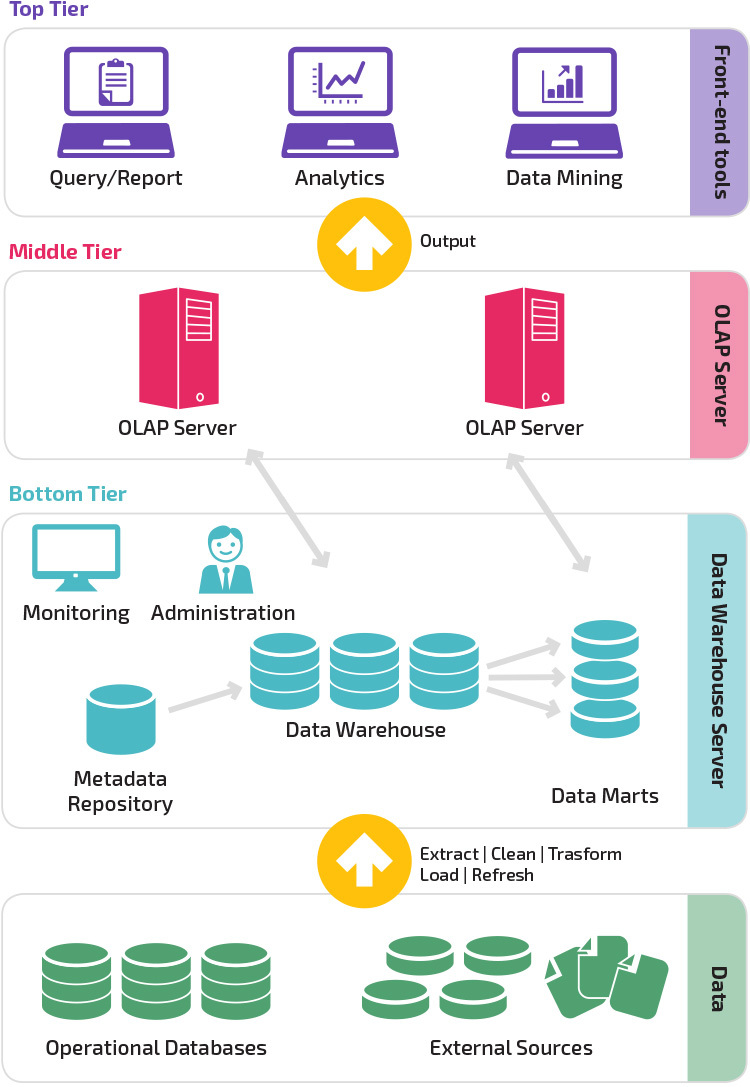
Three-Tier architectuur
traditionele Data warehouse architectuur maakt gebruik van een three-tier structuur die bestaat uit de volgende niveaus.
- onderste laag: dit niveau bevat de databaseserver die wordt gebruikt om gegevens uit veel verschillende bronnen te extraheren, zoals uit transactionele databases die worden gebruikt voor front-end-toepassingen.
- Middelste Laag: De middle tier herbergt een OLAP-server, die de gegevens omzet in een structuur die beter geschikt is voor analyse en complexe querying. De OLAP-server kan op twee manieren werken: ofwel als een uitgebreid relationeel databasemanagementsysteem dat de operaties op multidimensionale data in kaart brengt met standaard relationele operaties (relationele OLAP), of met behulp van een multidimensionaal OLAP-model dat de multidimensionale data en operaties direct implementeert.
- bovenste laag: de bovenste laag is de clientlaag. Dit niveau bevat de tools die worden gebruikt voor data-analyse op hoog niveau, querying rapportage en data mining.
Kimball vs. Inmon
twee pioniers van data warehousing genaamd Bill Inmon en Ralph Kimball hadden verschillende benaderingen van data warehouse design.De benadering van Ralph Kimball benadrukte het belang van data marts, die opslagplaatsen zijn van gegevens die tot bepaalde bedrijfsonderdelen behoren. Het datawarehouse is gewoon een combinatie van verschillende data marts die rapportage en analyse faciliteert. Het ontwerp van het Kimball data warehouse maakt gebruik van een” bottom-up ” benadering.Bill Inmon beschouwde het datawarehouse als de centrale opslagplaats voor alle bedrijfsgegevens. In deze aanpak creëert een organisatie eerst een genormaliseerd datawarehouse-model. Dimensionale datamartsâ worden vervolgens gemaakt op basis van het warehouse model. Dit staat bekend als een top-down benadering van data warehousing.
datawarehouse-modellen
in een traditionele architectuur zijn er drie gemeenschappelijke datawarehouse-modellen: virtual warehouse, data mart en enterprise data warehouse:
- een virtueel datawarehouse is een reeks afzonderlijke databases die samen kunnen worden opgevraagd, zodat een gebruiker effectief toegang heeft tot alle gegevens alsof deze in één datawarehouse waren opgeslagen.
- een data mart-model wordt gebruikt voor bedrijfsspecifieke rapportage en analyse. In dit datawarehouse-model worden gegevens geaggregeerd uit een reeks bronsystemen die relevant zijn voor een specifiek bedrijfsgebied, zoals sales of finance.
- een enterprise data warehouse model schrijft voor dat het Data warehouse geaggregeerde gegevens bevat die de gehele organisatie omvatten. Dit model ziet het datawarehouse als het hart van het informatiesysteem van de onderneming, met geà ntegreerde gegevens van alle business units.
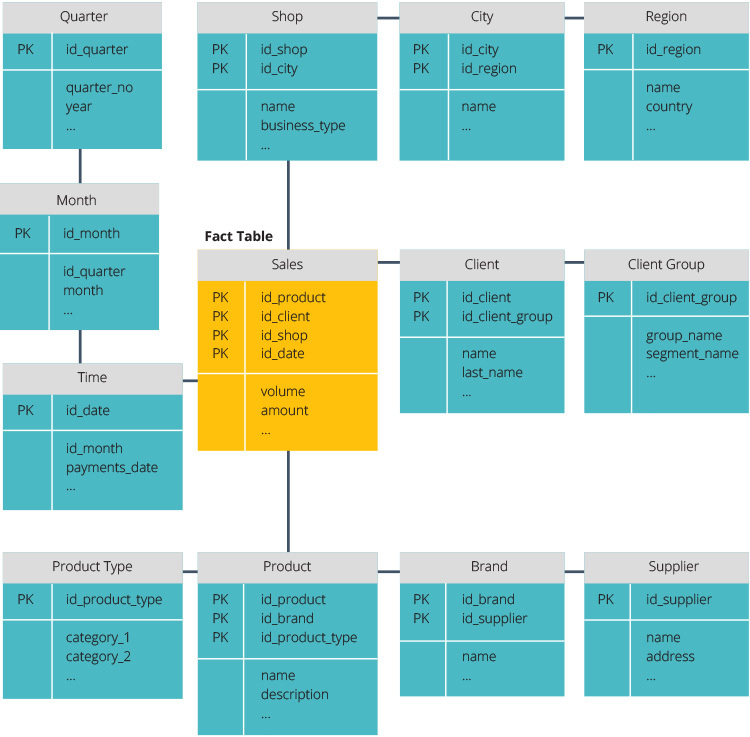
Star Schema vs. Snowflake Schema
het star schema en snowflake schema zijn twee manieren om een datawarehouse te structureren.
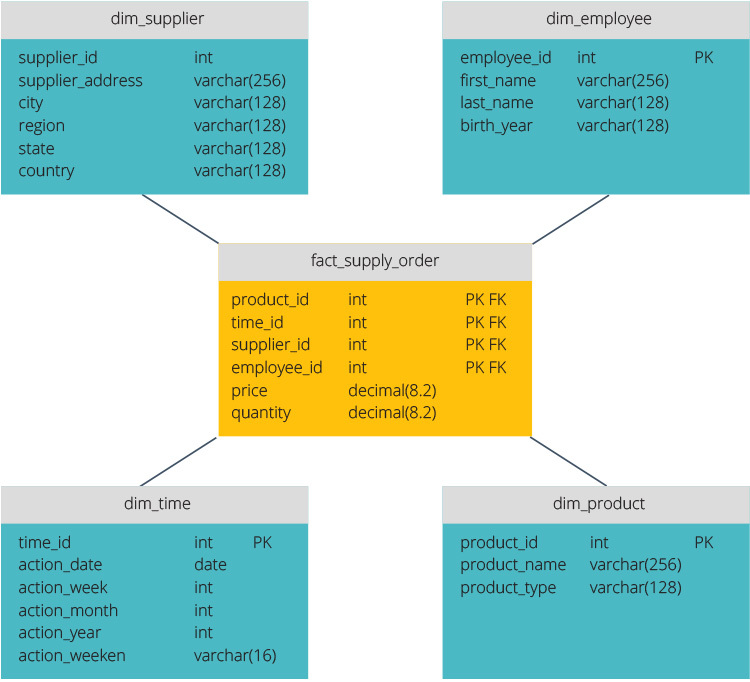
het star-schema heeft een gecentraliseerd gegevensarchief, opgeslagen in een feittabel. Het schema splitst de feittabel in een reeks van denormaliseerde dimensietabellen. De fact-tabel bevat geaggregeerde gegevens die voor rapportagedoeleinden moeten worden gebruikt, terwijl de dimensietabel de opgeslagen gegevens beschrijft.
Gedenormaliseerde ontwerpen zijn minder complex omdat de gegevens gegroepeerd zijn. De feittabel gebruikt slechts één link om aan elke dimensietabel mee te doen. Het eenvoudiger ontwerp van het sterrenschema maakt het veel gemakkelijker om complexe query ‘ s te schrijven.
het sneeuwvlokschema is anders omdat het de gegevens normaliseert. Normalisatie betekent efficiënt organiseren van de gegevens, zodat alle gegevens afhankelijkheden worden gedefinieerd, en elke tabel bevat minimale redundanties. Enkele dimensietabellen vertakken zich dus in afzonderlijke dimensietabellen.
het snowflake-schema gebruikt minder schijfruimte en behoudt de integriteit van de gegevens beter. Het belangrijkste nadeel is de complexiteit van query ‘ s die nodig zijn om toegang te krijgen tot gegevens—elke query moet diep graven om de relevante gegevens te krijgen, omdat er meerdere joins.
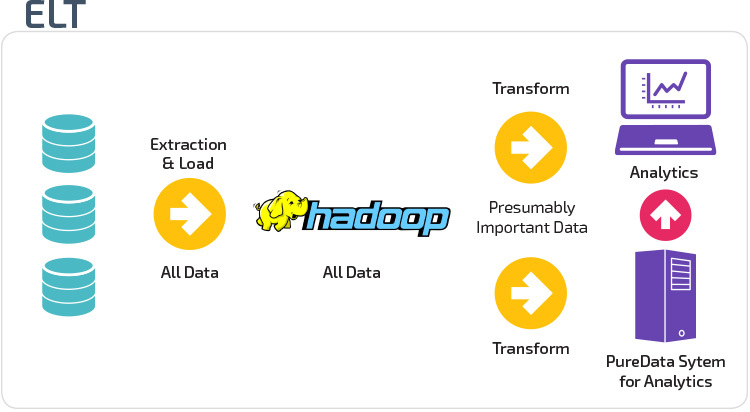
ETL vs. ELT
ETL en ELT zijn twee verschillende methoden voor het laden van gegevens in een magazijn.
Extract, Transform, Load (ETL) extraheert eerst de gegevens uit een pool van gegevensbronnen, die typisch transactionele databases zijn. De gegevens worden bewaard in een tijdelijke staging database. Vervolgens worden transformatiehandelingen uitgevoerd, om de gegevens te structureren en om te zetten in een geschikte vorm voor het target data warehouse-systeem. De gestructureerde gegevens worden vervolgens in het magazijn geladen, klaar voor analyse.
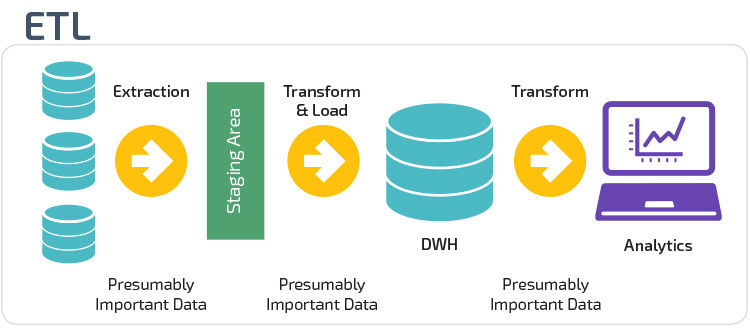
met Extract Load Transform (ELT) worden gegevens onmiddellijk geladen nadat ze uit de brongegevenspools zijn geëxtraheerd. Er is geen staging database, wat betekent dat de gegevens onmiddellijk worden geladen in de enkele, gecentraliseerde repository. De data wordt getransformeerd in het Data warehouse systeem voor gebruik met business intelligence tools en analytics.
organisatorische volwassenheid
de structuur van het datawarehouse van een organisatie hangt ook af van de huidige situatie en behoeften.
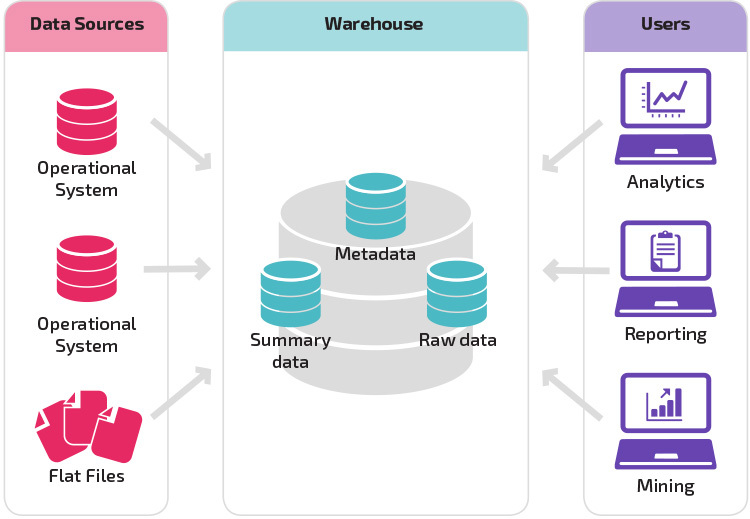
de basisstructuur geeft eindgebruikers van het magazijn rechtstreeks toegang tot samenvattende gegevens afkomstig van bronsystemen en voert analyse, rapportage en mining uit op die gegevens. Deze structuur is nuttig voor wanneer gegevensbronnen afkomstig zijn van dezelfde soorten databasesystemen.
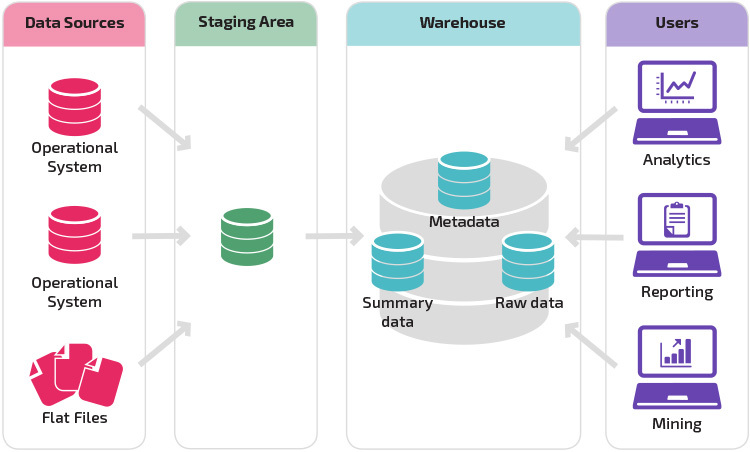
een magazijn met een staging area is de volgende logische stap in een organisatie met uiteenlopende gegevensbronnen met veel verschillende soorten en formaten van data. De staging area zet de gegevens om in een samengevat gestructureerd formaat dat gemakkelijker te bevragen is met analyse-en rapportagetools.
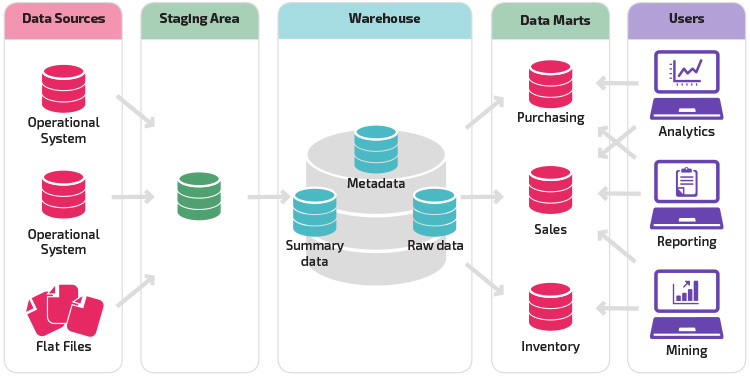
een variatie op de staging structuur is de toevoeging van data marts aan het Data warehouse. De data marts slaan samengevatte gegevens op voor een bepaalde branche, waardoor die gegevens gemakkelijk toegankelijk zijn voor specifieke vormen van analyse. Bijvoorbeeld, het toevoegen van data marts kan een financieel analist gemakkelijker gedetailleerde query ‘ s uit te voeren op verkoopgegevens, om voorspellingen over het gedrag van de klant te maken. Data marts maken analyse gemakkelijker door gegevens specifiek op de behoeften van de eindgebruiker af te stemmen.
nieuwe datawarehouse-architecturen
de afgelopen jaren zijn datawarehouses naar de cloud verhuisd. De nieuwe cloudgebaseerde datawarehouses houden zich niet aan de traditionele architectuur; elk datawarehouse-aanbod heeft een unieke architectuur.
deze sectie geeft een overzicht van de architecturen die worden gebruikt door twee van de meest populaire cloudgebaseerde magazijnen: Amazon Redshift en Google BigQuery.
Amazon Redshift
Amazon Redshift is een cloudgebaseerde weergave van een traditioneel datawarehouse.
Redshift vereist dat computerbronnen worden ingericht en opgezet in de vorm van clusters, die een verzameling van een of meer knooppunten bevatten. Elk knooppunt heeft zijn eigen CPU, opslag en RAM. Een leader-knooppunt compileert query ’s en draagt ze over aan het berekenen van nodes, die de query’ s uitvoeren.
op elk knooppunt worden gegevens opgeslagen in brokken, slices genaamd. Redshift gebruikt een zuilvormige opslag, wat betekent dat elk gegevensblok waarden bevat uit een enkele kolom over een aantal rijen, in plaats van een enkele rij met waarden uit meerdere kolommen.
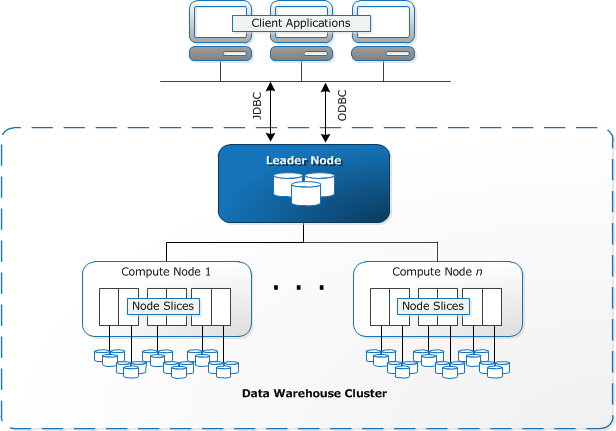
bron: AWS Documentation
Redshift maakt gebruik van een MPP-architectuur, waarbij grote datasets worden opgesplitst in brokken die worden toegewezen aan slices binnen elk knooppunt. Query ’s presteren sneller omdat de compute nodes query’ s in elke slice tegelijkertijd verwerken. Het Leader-knooppunt verzamelt de resultaten en retourneert ze naar de client-applicatie.
clienttoepassingen, zoals bi-en analysehulpmiddelen, kunnen rechtstreeks verbinding maken met Redshift met behulp van Open source PostgreSQL JDBC-en ODBC-stuurprogramma ‘ s. Analisten kunnen hun taken dus direct uitvoeren op de Roodverschuivingsgegevens.
roodverschuiving kan alleen gestructureerde gegevens laden. Het is mogelijk om gegevens te laden naar Redshift met behulp van vooraf geà ntegreerde systemen, waaronder Amazon S3 en DynamoDB, door het pushen van gegevens van elke lokale host met SSH-connectiviteit, of door het integreren van andere gegevensbronnen met behulp van de Redshift API.
Google BigQuery
BigQuery ‘ s architectuur is serverloos, wat betekent dat Google dynamisch de toewijzing van machinebronnen beheert. Alle beslissingen over resourcebeheer zijn daarom verborgen voor de gebruiker.
met BigQuery kunnen clients gegevens uit Google cloudopslag en andere leesbare gegevensbronnen Laden. De alternatieve optie is om gegevens te streamen, die ontwikkelaars in staat stelt om gegevens toe te voegen aan de data warehouse in real-time, rij-voor-rij, als het beschikbaar komt.
BigQuery gebruikt een query execution engine genaamd Dremel, die miljarden rijen gegevens in slechts een paar seconden kan scannen. Dremel gebruikt massaal parallelle querying om gegevens te scannen in het onderliggende Colossus bestandsbeheer systeem. Colossus distribueert bestanden in brokken van 64 megabytes onder vele computing resources genaamd nodes, die zijn gegroepeerd in clusters.
Dremel gebruikt een kolomvormige gegevensstructuur, vergelijkbaar met roodverschuiving. Een boomarchitectuur verstuurt vragen tussen duizenden machines in seconden.
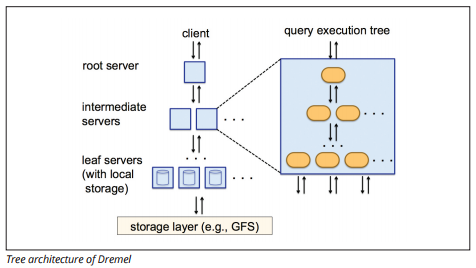
Afbeeldingsbron
eenvoudige SQL-opdrachten worden gebruikt om query ‘ s op Gegevens uit te voeren.
Panoply
Panoply biedt end-to-end data management-as-a-service. De unieke zelfoptimaliserende architectuur maakt gebruik van machine learning en natural language processing (NLP) om het datatraject van bron tot analyse te modelleren en te stroomlijnen, waardoor de tijd van data tot waarde zo dicht mogelijk bij nul wordt verkort.
de slimme gegevensinfrastructuur van Panoply bevat de volgende functies:
- analyseren van queries en gegevens-identificeren van de beste configuratie voor elke use case, aanpassen in de tijd, en het bouwen van indexen, sortkeys, diskeys, gegevenstypen, Stofzuigen en partitioneren.
- het identificeren van query ‘ s die niet de beste praktijken volgen – zoals geneste lussen of impliciete casting – en herschrijft ze tot een gelijkwaardige query die een fractie van de runtime of resources vereist.
- serverconfiguraties in de loop van de tijd optimaliseren op basis van querypatronen en door te leren welke serverinstellingen het beste werken. Het platform wisselt naadloos van servertype en meet de resulterende prestaties.
Clouddatawarehouses
cloudgebaseerde datawarehouses zijn een grote stap voorwaarts ten opzichte van traditionele architecturen. Echter, gebruikers nog steeds geconfronteerd met verschillende uitdagingen bij het opzetten van hen:
- het laden van gegevens naar cloud data warehouses is niet-triviaal, en voor grootschalige data pijpleidingen, het vereist het opzetten, testen en onderhouden van een ETL-proces. Dit deel van het proces wordt meestal gedaan met tools van derden.
- Updates, upserts en verwijderingen kunnen lastig zijn en moeten zorgvuldig worden uitgevoerd om degradatie in query-prestaties te voorkomen.
- Semi-gestructureerde gegevens zijn moeilijk te verwerken – moeten worden genormaliseerd in een relationele database formaat, die automatisering vereist voor grote gegevensstromen.
- geneste structuren worden doorgaans niet ondersteund in clouddatawarehouses. U moet geneste tabellen plat te leggen in een formaat dat de data warehouse kan begrijpen.
- uw cluster optimaliseren – er zijn verschillende opties voor het instellen van een Roodverschuivingscluster om uw workloads uit te voeren. Verschillende workloads, datasets of zelfs verschillende soorten query ‘ s vereisen mogelijk een andere setup. Om optimaal te blijven moet je voortdurend opnieuw te bezoeken en tweak uw setup.
- Query-optimalisatie – gebruikersquery ‘ s volgen mogelijk geen best practices en zullen daarom veel langer duren. U kunt vinden jezelf werken met gebruikers of geautomatiseerde client applicaties om query ‘ s te optimaliseren, zodat de data warehouse kan presteren zoals verwacht.
- back-up en herstel—hoewel de datawarehouse-leveranciers tal van opties bieden voor het back-uppen van uw gegevens, zijn ze niet triviaal om ze op te zetten en vereisen ze monitoring en aandacht.
Panoply is een slim datawarehouse dat een laag van automatisering toevoegt die zorgt voor alle complexe taken hierboven, waardoor kostbare tijd wordt bespaard en u in minuten van gegevens naar inzicht kunt komen.
meer informatie over Panoply ‘ s smart data warehouse tools.
meer informatie over datawarehouses
- datawarehouse-Concepten: traditioneel vs. Cloud
- Database vs. Data Warehouse
- Data Mart vs. Data Warehouse
- Amazon Redshift Architecture