niech X będzie zmienną losową o wartości rzeczywistej i niech 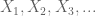
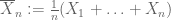
słabe prawo wielkich liczb. Załóżmy, że pierwszy moment
z X jest skończony. Następnie
zbiega się z prawdopodobieństwem do
, tak więc
dla każdego
.
silne prawo wielkich liczb. Załóżmy, że pierwszy moment
.
(jeśli wzmocni się założenie pierwszej chwili do skończoności drugiej chwili 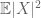
słabe prawo jest łatwe do udowodnienia, ale silne prawo (co oczywiście implikuje słabe prawo, przez twierdzenie Egoroffa) jest bardziej subtelne i w rzeczywistości dowód tego prawa (zakładając skończoność pierwszej chwili) zwykle pojawia się tylko w tekstach dla zaawansowanych absolwentów. Pomyślałem więc, że przedstawię tutaj dowód obu praw, które opierają się na standardowych technikach metody chwili i obcinania. Nacisk w tej ekspozycji będzie położony na motywację i metody, a nie zwięzłość i siłę wyników; istnieją dowody mocnego prawa w literaturze, które zostały skompresowane do rozmiaru jednej strony lub mniej, ale to nie jest mój cel tutaj.
— metoda momentu —
metoda momentu ma na celu kontrolę prawdopodobieństwa ogonowego zmiennej losowej (tj. prawdopodobieństwa, że zmienia się ona znacznie od swojej średniej) za pomocą momentów, a w szczególności zera, pierwszego lub drugiego momentu. Powodem, dla którego ta metoda jest tak skuteczna, jest to, że pierwsze kilka chwil często można obliczyć dość precyzyjnie. Metoda pierwszego momentu zazwyczaj wykorzystuje nierówność Markowa
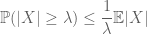
(co następuje, przyjmując nierówność punktową 

(zauważ, że (2) jest po prostu (1) stosowane do zmiennej losowej 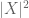

Ogólnie rzecz biorąc, aby obliczyć pierwszy moment, zwykle stosuje się liniowość oczekiwań

aby obliczyć drugi moment, trzeba również zrozumieć kowariancje (które są szczególnie proste, jeśli zakłada się niezależność parami), dzięki tożsamościom takim jak
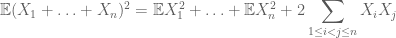
lub wariant znormalizowany
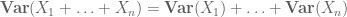

wyższe momenty mogą zasadniczo dawać dokładniejsze informacje, ale często wymagają silniejszych założeń dotyczących badanych obiektów, takich jak wspólna niezależność.
oto podstawowe zastosowanie metody first moment:
Borel-Cantelli lemma. Niech
będzie ciągiem zdarzeń takich, że
jest skończony. Wtedy prawie na pewno tylko finalnie wiele zdarzeń
jest prawdą.
dowód. Niech 


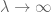

Wracając do prawa dużych liczb, metoda pierwszego momentu daje następujący ogon związany:
Lemma 1. Jeśli
jest skończona, to
.
dowód. Przez nierówność trójkąta, 

Lemma 1 sama w sobie nie jest wystarczająco silna, aby udowodnić prawo dużych liczb w słabej lub silnej formie – w szczególności nie wykazuje żadnej poprawy, ponieważ N staje się duży – ale przydatne będzie obsłużenie jednego z terminów błędów w tych dowodach.
możemy uzyskać silniejsze granice niż Lemma 1 – w szczególności granice, które poprawiają się z n-kosztem silniejszych założeń na X.
Lemma 2. Jeśli
.
dowód. Standardowe obliczenia, wykorzystujące (3) i parową niezależność 



w przeciwnym kierunku istnieje metoda momentu zerowego, bardziej znana jako Związanie

lub równoważnie (aby wyjaśnić terminologię „moment zerowy”)

dla dowolnych nieujemnych zmiennych losowych 
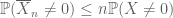
tak jak drugi moment związany (Lemma 2) jest użyteczny tylko wtedy, gdy ktoś ma dobrą kontrolę nad drugim momentem (lub wariancją) X, Estymator ogona momentu zerowego (3) jest użyteczny tylko wtedy, gdy mamy dobrą kontrolę nad momentem zerowym 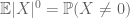
— Obcinanie —
drugi moment związany ogonem (Lemat 2) daje już słabe prawo dużych liczb w przypadku, gdy X ma skończony drugi moment (lub równoważnie, skończoną wariancję). Ogólnie rzecz biorąc, jeśli wszystko, co wiemy o X, to to, że ma skończony pierwszy moment, to nie możemy stwierdzić, że X ma skończony drugi moment. Możemy jednak wykonać obcinanie
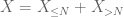
z X na dowolnym wymaganym progu N, gdzie 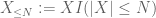

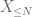
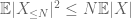
i stąd też mamy skończoną wariancję
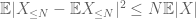
drugi termin 
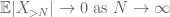
przez nierówność trójkąta wnioskujemy, że pierwszy wyraz
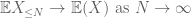
to są wszystkie narzędzia, których potrzebujemy, aby udowodnić słabe prawo dużych liczb:
dowód słabego prawa. Let 

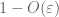
z (7), (8) możemy znaleźć próg N (w zależności od 
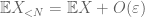

od pierwszej chwili (Lemma 1) wiemy, że 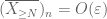
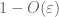
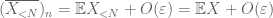
— silne prawo –
silne prawo można udowodnić, przesuwając powyższe metody nieco dalej i stosując kilka dodatkowych sztuczek.
pierwszą sztuczką jest obserwacja, że aby udowodnić silne prawo, wystarczy to zrobić dla nieujemnych zmiennych losowych

gdy X jest nieujemne, widzimy, że średnie empiryczne

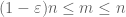
z powodu tej kwazimonotoniczności możemy sparować zbiór n, dla którego musimy udowodnić silne prawo. Dokładniej, wystarczy pokazać
mocne prawo dużych liczb, wersja zredukowana. Niech
będzie nieujemną zmienną losową z
i niech
będzie ciągiem liczb całkowitych, który jest lakunarny w tym sensie, że
dla niektórych
i wszystkie wystarczająco duże J. następnie
zbiega się prawie na pewno do
rzeczywiście, jeśli moglibyśmy udowodnić wersję skróconą, to przy zastosowaniu tej wersji do sekwencji lakunarnej 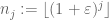


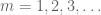
teraz, gdy mamy sparsyfikowaną sekwencję, ekonomiczne staje się zastosowanie lematu Borela-Cantellego. Rzeczywiście, przez wiele zastosowań tego lematu widzimy, że wystarczy pokazać, że

dla nieujemnego X skończonego pierwszego momentu, dowolny ciąg lakunarny 
w tym momencie wracamy i stosujemy metody, które już działały, aby dać słabe prawo. Mianowicie, aby oszacować każde z prawdopodobieństw ogonowych 
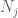
powinniśmy przynajmniej wybrać 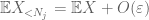


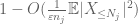

teraz patrzymy na wkład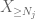
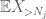
ale jest jeszcze jedna ostatnia karta do zagrania, czyli metoda momentu zerowego (4). Jak wspomniano wcześniej, to wiązanie jest ogólnie kiepskie-ale jest bardzo dobre, gdy X jest w większości zerem, co jest dokładnie sytuacją z 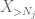


składając to wszystko w całość, widzimy, że

Podsumowując to w j, widzimy, że skończymy, gdy tylko dowiemy się, jak wybrać
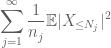
oraz
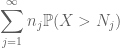
są skończone. (Jak zwykle, mamy kompromis: zwiększenie
opierając się na wcześniejszej dyskusji, naturalnym jest ustawienie 

oraz
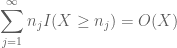
(gdzie implikowana stała tutaj zależy od sekwencji 
Uwaga 1. Powyższy dowód w rzeczywistości pokazuje, że silne prawo dużych liczb obowiązuje nawet wtedy, gdy zakłada się tylko parową niezależność 

Uwaga 2. Istotne jest,aby zmienne losowe 

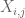
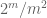
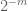



Z punktu widzenia teorii interpolacji, można postrzegać powyższy argument jako argument interpolacji, ustanawiając 


Oglądając ciąg