Um data warehouse é um sistema eletrônico que reúne dados de uma ampla variedade de fontes de dentro da empresa e usa os dados para apoiar a tomada de decisões de gestão.
as empresas estão cada vez mais se movendo em direção a armazéns de dados baseados em nuvem em vez de sistemas tradicionais no local. Os armazéns de dados baseados nas nuvens diferem dos armazéns tradicionais das seguintes formas::
- não há necessidade de comprar hardware físico.
- é mais rápido e mais barato criar e escalar armazéns de dados em nuvem.
- as arquiteturas de armazenamento de dados em nuvem podem tipicamente realizar consultas analíticas complexas muito mais rápido porque eles usam processamento massivamente paralelo (MPP).
o resto deste artigo abrange a arquitectura tradicional de data warehouse e introduz algumas ideias e conceitos arquitectónicos utilizados pelos mais populares serviços de data warehouse baseados em nuvem.
para mais detalhes, consulte a nossa página sobre conceitos de data warehouse neste guia.
- arquitetura tradicional de Data Warehouse
- Arquitectura de três níveis
- Kimball vs. Inmon
- Data Warehouse Models
- star Schema vs. Snowflake Schema
- ETL vs. ELT
- maturidade organizacional
- novas arquiteturas de armazenamento de dados
- Redshift Amazon
- Google BigQuery
- Panoply
- além dos armazéns de dados em nuvem
- Saiba mais sobre armazéns de dados
arquitetura tradicional de Data Warehouse
os seguintes conceitos destacam algumas das ideias estabelecidas e princípios de design utilizados para a construção de armazéns de dados tradicionais.
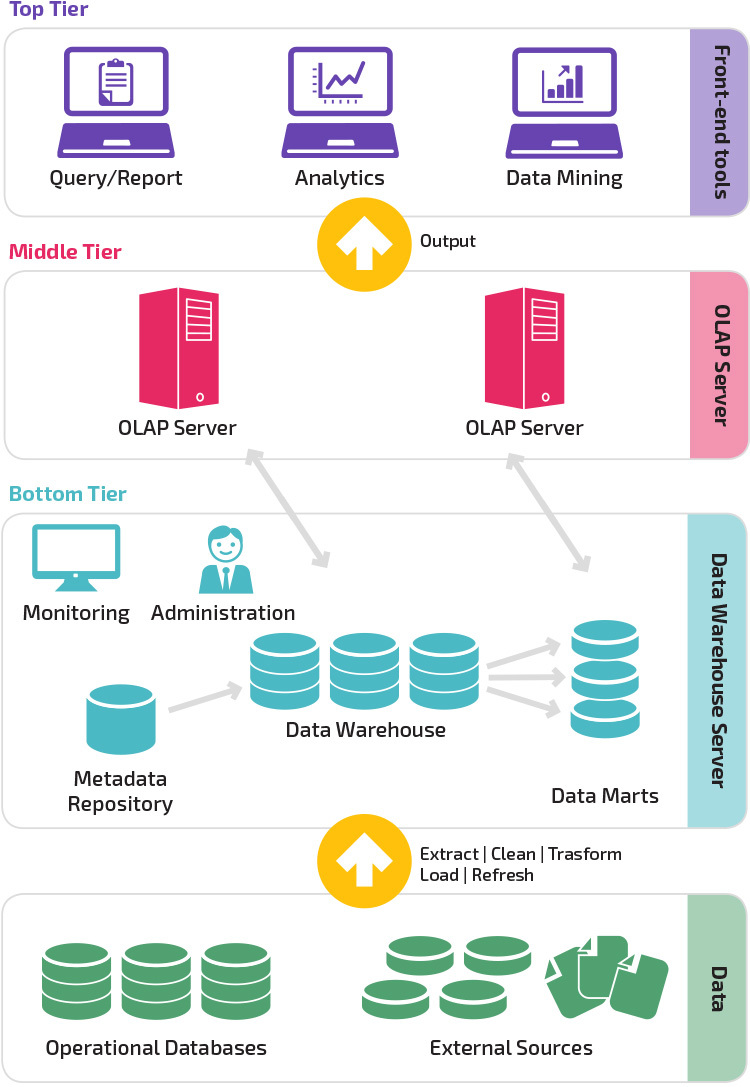
Arquitectura de três níveis
arquitectura tradicional de data warehouse emprega uma estrutura de três níveis composta pelos seguintes níveis.
- nível inferior: este nível contém o servidor de base de dados usado para extrair dados de muitas fontes diferentes, tais como a partir de bases de dados transacionais usadas para aplicações front-end.
- nível médio: O nível médio abriga um servidor OLAP, que transforma os dados em uma estrutura mais adequada para análise e perguntas complexas. O servidor OLAP pode trabalhar de duas maneiras: ou como um sistema de gerenciamento de banco de dados relacional estendido que mapeia as operações em dados multidimensionais para operações relacionais padrão (OLAP relacional), ou usando um modelo multidimensional OLAP que implementa diretamente os dados multidimensionais e operações.
- camada superior: a camada superior é a camada cliente. Este nível contém as ferramentas utilizadas para a análise de dados de alto nível, relatórios de pesquisa e Mineração de dados.
Kimball vs. Inmon
Two pioneers of data warehousing named Bill Inmon and Ralph Kimball had different approaches to data warehouse design.
a abordagem de Ralph Kimball enfatizou a importância dos marts de dados, que são repositórios de dados pertencentes a linhas particulares de negócios. O data warehouse é simplesmente uma combinação de diferentes marts de dados que facilita a comunicação e análise. O projeto do armazém de dados Kimball usa uma abordagem “bottom-up”.
Bill Inmon considerou o data warehouse como o repositório centralizado para todos os dados da empresa. Nesta abordagem, uma organização primeiro cria um modelo de data warehouse normalizado. Os marts de dados dimensionais são então criados com base no modelo de armazém. Isto é conhecido como uma abordagem top-down para armazenamento de dados.
Data Warehouse Models
In a traditional architecture there are three common data warehouse models: virtual warehouse, data mart, and enterprise data warehouse:
- um armazém de dados virtual é um conjunto de bases de dados separadas, que podem ser pesquisadas em conjunto, para que um usuário possa efetivamente acessar todos os dados como se ele fosse armazenado em um armazém de dados.
- é utilizado um modelo data mart para a informação e análise específicas dos segmentos de actividade. Neste modelo de data warehouse, os dados são agregados a partir de uma gama de sistemas fonte relevantes para uma área de Negócio específica, tais como vendas ou finanças.
- um modelo enterprise data warehouse prescreve que o data warehouse contém dados agregados que abrangem toda a organização. Este modelo vê o data warehouse como o coração do sistema de informação da empresa, com Dados Integrados de todas as unidades de Negócio.
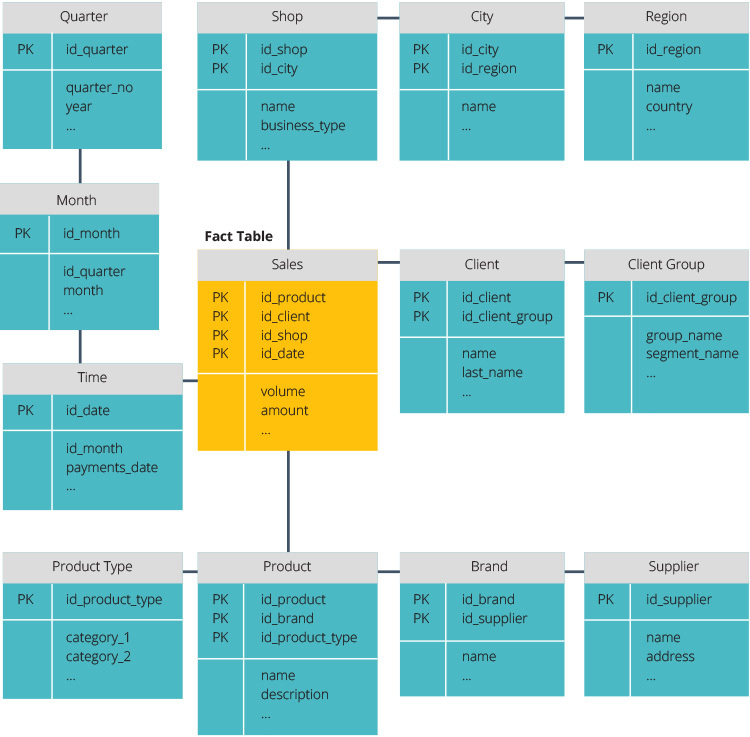
star Schema vs. Snowflake Schema
the star schema and snowflake schema are two ways to structure a data warehouse.
o esquema estelar tem um repositório de dados centralizado, armazenado em uma tabela de fatos. O esquema divide a tabela de fatos em uma série de tabelas dimensionais desnormalizadas. O quadro fact contém dados agregados a utilizar para efeitos de reporte, enquanto o quadro dimensional descreve os dados armazenados.
os desenhos desnormalizados são menos complexos porque os dados estão agrupados. A tabela de fatos usa apenas um link para se juntar a cada tabela de dimensões. O desenho mais simples do esquema da estrela torna muito mais fácil escrever consultas complexas.
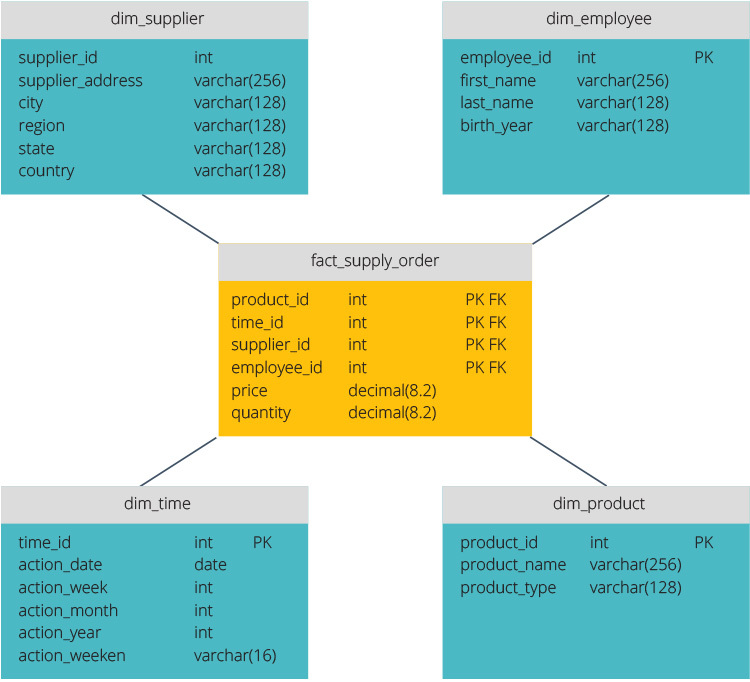
o esquema do floco de neve é diferente porque normaliza os dados. Normalização significa organizar eficientemente os dados para que todas as dependências de dados sejam definidas, e cada tabela contém redundâncias mínimas. Os quadros de dimensão única são, assim, divididos em quadros de dimensão separados.
o esquema do floco de neve usa menos espaço em disco e preserva melhor a integridade dos dados. A principal desvantagem é a complexidade das consultas necessárias para acessar dados—cada consulta deve cavar profundamente para chegar aos dados relevantes, porque há múltiplas ligações.
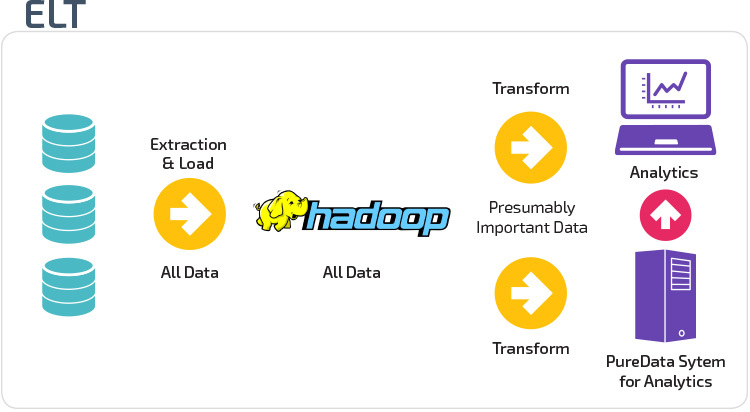
ETL vs. ELT
ETL e ELT são dois métodos diferentes de carregamento de dados em um armazém.
extrato, transformação, carga (ETL) primeiro extrai os dados de um conjunto de fontes de dados, que são tipicamente bases de dados transacionais. Os dados são guardados numa base de dados temporária. As operações de transformação são então realizadas, para estruturar e converter os dados em uma forma adequada para o sistema de armazenamento de dados alvo. Os dados estruturados são então carregados no armazém, prontos para análise.
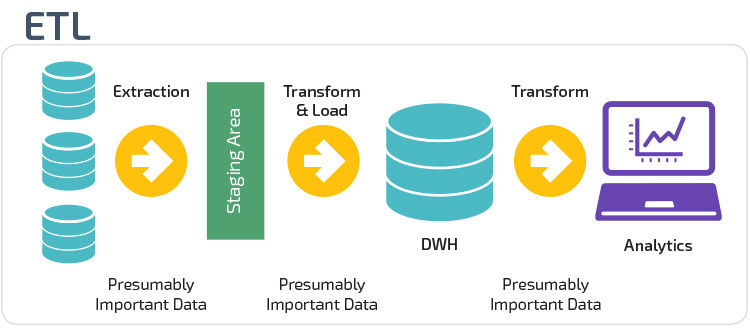
com o Extract Load Transform( ELT), os dados são imediatamente carregados após serem extraídos dos conjuntos de dados de origem. Não há base de dados de staging, o que significa que os dados são imediatamente carregados no repositório único e centralizado. Os dados são transformados dentro do sistema de armazenamento de dados para uso com ferramentas de inteligência de negócios e análises.
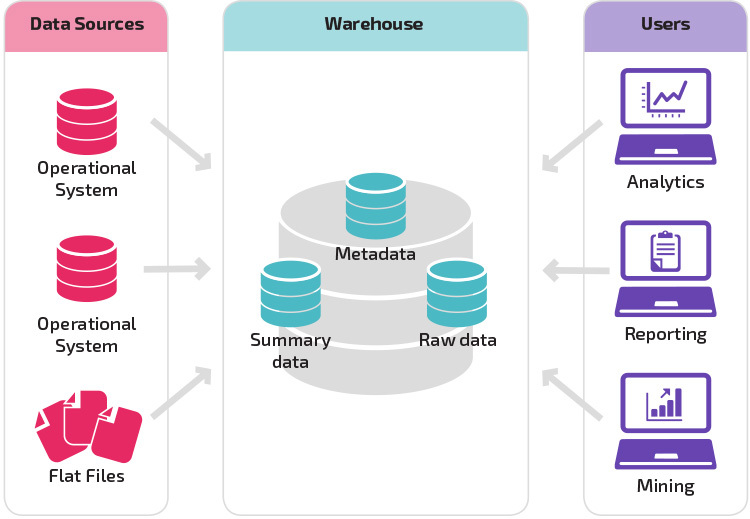
maturidade organizacional
a estrutura do armazém de dados de uma organização também depende de sua situação atual e necessidades.
a estrutura básica permite aos usuários finais do armazém acessar diretamente os dados resumidos derivados de sistemas de origem e realizar análises, relatórios e Mineração sobre esses dados. Esta estrutura é útil para quando as fontes de dados derivam dos mesmos tipos de sistemas de banco de dados.
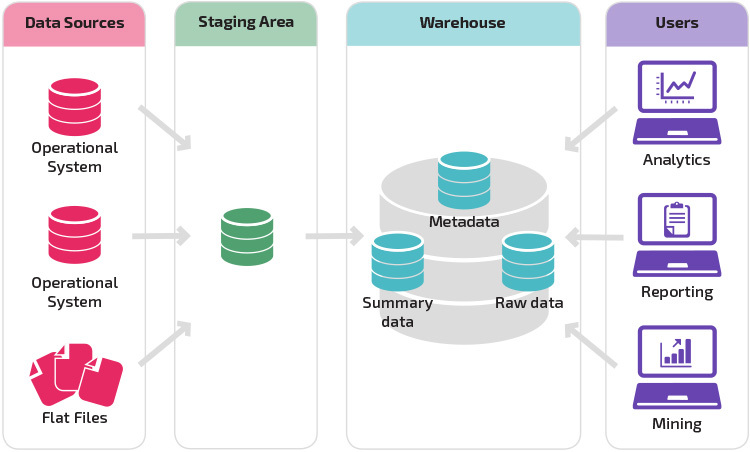
um armazém com uma área de preparação é o próximo passo lógico de uma organização com fontes de dados díspares com muitos tipos e formatos diferentes de dados. A área de preparação converte os dados em um formato estruturado resumido que é mais fácil de consultar com ferramentas de análise e relatórios.
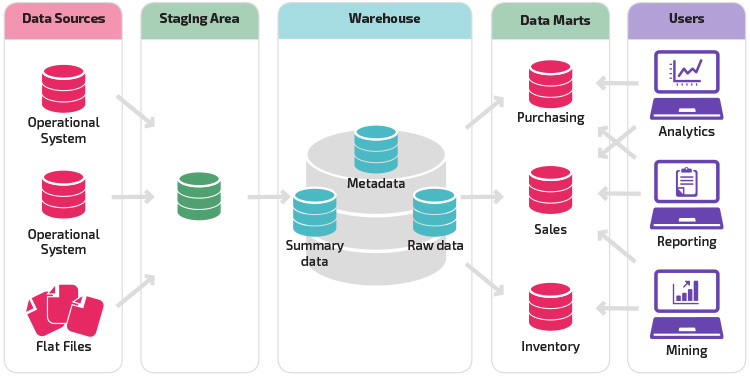
uma variação na estrutura de encenação é a adição de marts de dados ao armazém de dados. Os marts de dados armazenam dados resumidos para uma determinada linha de negócio, tornando esses dados facilmente acessíveis para formas específicas de análise. Por exemplo, a adição de dados marts pode permitir que um analista financeiro para realizar mais facilmente consultas detalhadas sobre dados de vendas, para fazer previsões sobre o comportamento do cliente. Os marts de dados facilitam a análise, adaptando os dados especificamente para atender às necessidades do usuário final.
novas arquiteturas de armazenamento de dados
nos últimos anos, os armazéns de dados estão se movendo para a nuvem. Os novos armazéns de dados baseados em nuvem não aderem à arquitetura tradicional; cada oferta de armazenamento de dados tem uma arquitetura única.
esta secção resume as arquitecturas usadas por dois dos armazéns mais populares nas nuvens: Amazon Redshift e Google BigQuery.
Redshift Amazon
Redshift Amazon é uma representação em nuvem de um armazém de dados tradicional.
Redshift requer recursos computacionais para serem provisionados e configurados na forma de clusters, que contêm uma coleção de um ou mais nós. Cada nó tem sua própria CPU, armazenamento e RAM. Um nó líder compila consultas e transfere-as para computar nós, que executam as consultas.
em cada nó, os dados são armazenados em pedaços, chamados fatias. Redshift usa um armazenamento colunar, o que significa que cada bloco de dados contém valores de uma única coluna ao longo de um número de linhas, em vez de uma única linha com valores de várias colunas.
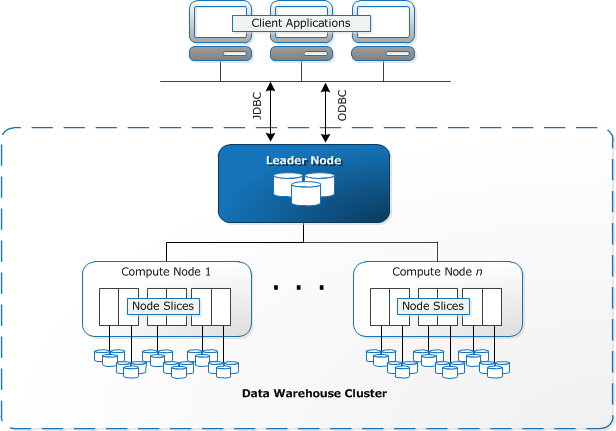
Fonte: AWS Documentação
Redshift usa uma arquitetura MPP, a quebra de grandes conjuntos de dados em blocos que são atribuídos aos fatias dentro de cada nó. As consultas realizam mais rápido porque os nós computados processam consultas em cada fatia simultaneamente. O nó líder agrega os resultados e devolve-os à aplicação cliente.
aplicações cliente, tais como ferramentas BI e analytics, podem se conectar diretamente ao Redshift usando drivers de código aberto PostgreSQL JDBC e ODBC. Os analistas podem assim executar as suas tarefas directamente nos dados Redshift.
o Redshift só pode carregar dados estruturados. É possível carregar dados para Redshift usando sistemas pré-integrados incluindo Amazon S3 e DynamoDB, empurrando dados de qualquer host no local com conectividade SSH, ou integrando outras fontes de dados usando a API Redshift.
Google BigQuery
Bigquery’s architecture is serverless, meaning Google dynamically manages the allocation of machine resources. Todas as decisões de gestão de recursos estão, portanto, escondidas do Usuário.
BigQuery permite que os clientes carreguem dados do Google Cloud Storage e outras fontes de dados legíveis. A opção alternativa é transmitir dados, o que permite aos desenvolvedores adicionar dados ao armazém de dados em tempo real, linha a linha, à medida que ele se torna disponível.
BigQuery usa um motor de execução de consultas chamado Dremel, que pode escanear bilhões de linhas de dados em apenas alguns segundos. A Dremel usa uma pesquisa massivamente paralela para analisar dados no sistema de gerenciamento de arquivos Colossus. Colossus distribui arquivos em blocos de 64 megabytes entre muitos recursos de computação chamados nós, que são agrupados em clusters.
Dremel usa uma estrutura de dados colunares, semelhante ao Redshift. Uma arquitetura de árvore envia consultas entre milhares de máquinas em segundos.
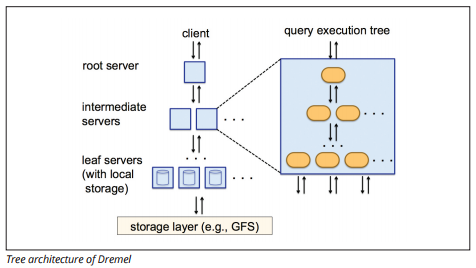
a fonte de imagem
comandos SQL simples são usados para realizar consultas sobre dados.
Panoply
Panoply provides end-to-end data management-as-a-service. Sua arquitetura única de auto-otimização utiliza a aprendizagem de máquinas e o processamento de linguagem natural (NLP) para modelar e racionalizar a jornada de dados da fonte para a análise, reduzindo o tempo dos dados para o valor o mais próximo possível de nenhum.
a infra-estrutura de dados inteligentes de Panoply inclui as seguintes características::
- Análise de consultas e dados – identificando a melhor configuração para cada caso de uso, ajustando-o ao longo do tempo, e índices de construção, chaves, chaves, tipos de dados, aspirar e particionamento.
- Identificação de consultas que não seguem as melhores práticas – tais como aqueles que incluem loops aninhados ou implícito de fundição – e reescreve-los para uma consulta equivalente exigindo uma fração do tempo de execução ou recursos.
- otimizar configurações do servidor ao longo do tempo com base em padrões de consulta e aprendendo qual a configuração do servidor funciona melhor. A plataforma muda os tipos de servidor de forma perfeita e mede o desempenho resultante.
além dos armazéns de dados em nuvem
os armazéns de dados em nuvem são um grande passo em frente das arquiteturas tradicionais. No entanto, os utilizadores ainda enfrentam vários desafios ao configurá – los:
- o carregamento de dados para armazéns de dados em nuvem não é trivial, e para pipelines de dados em larga escala, requer a criação, teste e manutenção de um processo ETL. Esta parte do processo é tipicamente feito com ferramentas de terceiros.
- atualizações, atualizações e supressões podem ser complicadas e devem ser feitas cuidadosamente para evitar a degradação no desempenho da consulta.
- dados Semi-estruturados é difícil de lidar-precisa ser normalizado em um formato de banco de dados relacional, que requer automação para grandes fluxos de dados.
- estruturas aninhadas não são normalmente suportadas em armazéns de dados em nuvem. Você terá que nivelar as tabelas aninhadas em um formato que o data warehouse pode entender.
- optimizar o seu conjunto—existem diferentes opções para configurar um conjunto Redshift para executar as suas cargas de trabalho. Diferentes cargas de trabalho, Conjuntos de dados, ou até mesmo diferentes tipos de consultas podem exigir uma configuração diferente. Para se manter óptimo, terá de rever e ajustar continuamente a sua configuração.Otimização de consultas-consultas de usuários podem não seguir as melhores práticas, e consequentemente levará muito mais tempo para ser executado. Você pode se encontrar trabalhando com usuários ou aplicações automatizadas de clientes para otimizar consultas para que o armazém de dados possa realizar como esperado.
- Backup e recuperação-enquanto os vendedores de data warehouse fornecem inúmeras opções para fazer backup de seus dados, eles não são triviais para configurar e requerem monitoramento e atenção apertada.
Panoply é um armazém de dados inteligente que adiciona uma camada de automação que cuida de todas as tarefas complexas acima, economizando tempo valioso e ajudando você a passar dos dados para o insight em minutos.
Saiba mais sobre as ferramentas smart data warehouse da Panoply.
Saiba mais sobre armazéns de dados
- conceitos de Armazém de dados: tradicional vs. Cloud
- Database vs. Data Warehouse
- Data Mart vs. Data Warehouse
- Amazon Redshift Architecture