lad være en reel værdi tilfældig variabel, og lad 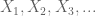
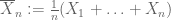
svag lov af stort antal. Antag, at det første øjeblik
af H er endeligt. Derefter
konvergerer i Sandsynlighed til
, således
for hver
.
stærk lov af stort antal. Antag, at det første øjeblik
.
(hvis man styrker det første øjebliks antagelse til det andet øjebliks endelighed 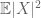
den svage lov er let at bevise, men den stærke lov (som naturligvis indebærer den svage lov ved Egoroffs sætning) er mere subtil, og faktisk vises beviset for denne lov (forudsat bare finitet i det første øjeblik) normalt kun i avancerede kandidattekster. Så jeg troede, jeg ville præsentere et bevis her for begge love, som fortsætter med moment-metodens standardteknikker og trunkering. Vægten i denne redegørelse vil være på motivation og metoder snarere end kortfattethed og styrke af resultater; der findes beviser for den stærke lov i litteraturen, der er komprimeret ned til størrelsen på en side eller mindre, men dette er ikke mit mål her.
— moment —metoden –
moment-metoden søger at kontrollere halesandsynlighederne for en tilfældig variabel (dvs.sandsynligheden for, at den svinger langt fra dens gennemsnit) ved hjælp af øjeblikke, og især nul, første eller andet øjeblik. Årsagen til, at denne metode er så effektiv, er, at de første få øjeblikke ofte kan beregnes ret præcist. Det første øjeblik metode, der normalt beskæftiger Markov ‘ s ulighed
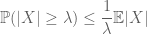
(der følger ved at tage forventninger pointwise ulighed 

(bemærk, at (2) er lige (1) anvendes til den tilfældige variabel 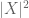

generelt set for at beregne det første øjeblik anvender man normalt linearitet af forventning

for at beregne det andet øjeblik skal man også forstå kovariancer (som er særligt enkle, hvis man antager parvis uafhængighed) takket være identiteter som
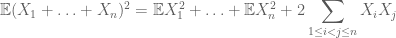
eller den normaliserede variant
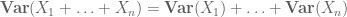

højere øjeblikke kan i princippet give mere præcise oplysninger, men kræver ofte stærkere antagelser om de objekter, der studeres, såsom fælles uafhængighed.
her er en grundlæggende anvendelse af first moment-metoden:
Borel-Cantelli lemma. Lad
være en sekvens af begivenheder, således at
er endelig. Så næsten sikkert, kun endeligt mange af begivenhederne
er sande.
bevis. Lad 


udlejning 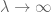

vender tilbage til loven om store tal, det første øjeblik metode giver følgende hale bundet:
Lemma 1. (Første øjeblik hale bundet) hvis
er endelig, så
.
bevis. Ved trekanten ulighed, 

Lemma 1 er ikke stærk nok i sig selv til at bevise loven om store tal i enten svag eller stærk form – især viser den ingen forbedring, da n bliver stor – men det vil være nyttigt at håndtere et af fejlbetingelserne i disse beviser.
vi kan få stærkere grænser end Lemma 1 – især grænser, der forbedres med n – på bekostning af stærkere antagelser om
Lemma 2. (Andet øjeblik hale bundet) hvis
.
bevis. En standardberegning, der udnytter (3) og den parvise uafhængighed af 



i modsat retning er der nulmomentmetoden, mere almindeligt kendt som union bundet

eller tilsvarende (for at forklare terminologien “nul øjeblik”)

for alle ikke-negative tilfældige variabler 
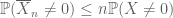
ligesom det andet øjeblik bundet (Lemma 2) kun er nyttigt, når man har god kontrol på det andet øjeblik (eller varians) af H, er nulmomentets halestimat (3) kun nyttigt, når vi har god kontrol på nulmomentet 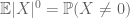
— trunkering —
det andet øjeblik hale bundet (Lemma 2) giver allerede den svage lov af store tal i tilfælde, hvor H har et endeligt andet øjeblik (eller ækvivalent, endelig varians). Generelt, hvis alt hvad man ved om K er, at det har et endeligt første øjeblik, så kan vi ikke konkludere, at K har et endeligt andet øjeblik. Vi kan dog udføre en afkortning
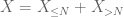
på en hvilken som helst ønsket tærskel N, hvor 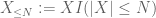

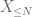
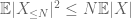
og derfor har vi også endelig varians
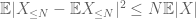
det andet udtryk
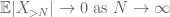
ved trekanten ulighed konkluderer vi, at det første udtryk
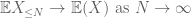
dette er alle de værktøjer, vi har brug for for at bevise den svage lov i stort antal:
bevis for svag lov. Lad 

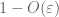
fra (7), (8), kan vi finde en tærskel N (afhængig af 
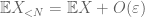

fra det første øjeblik halebundet (Lemma 1)ved vi, at 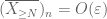
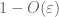
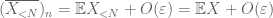
— den stærke lov-
den stærke lov kan bevises ved at skubbe ovenstående metoder lidt længere og bruge et par flere tricks.
det første trick er at observere, at for at bevise den stærke lov er det tilstrækkeligt at gøre det for ikke-negative tilfældige variabler

når det er ikke-negativt, ser vi, at de empiriske gennemsnit

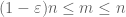
på grund af denne kvasimonotonicitet kan vi sparsificere det sæt n, som vi har brug for for at bevise den stærke lov. Mere præcist er det tilstrækkeligt at vise
stærk lov med stort antal, reduceret version. Lad
være en ikke-negativ tilfældig variabel med
, og lad
være en sekvens af heltal, der er lakunær i den forstand, at
for nogle
og alle tilstrækkeligt store j. derefter
konvergerer næsten sikkert til
faktisk, hvis vi kunne bevise den reducerede version, så ved at anvende den version til den lacunære sekvens 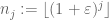


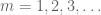
nu hvor vi har sparsificeret sekvensen, bliver det økonomisk at anvende Borel-Cantelli lemma. Faktisk ser vi ved mange anvendelser af denne lemma, at det er tilstrækkeligt at vise det

for ikke-negative træk ved det endelige første øjeblik, enhver lakunær sekvens 
på dette tidspunkt går vi tilbage og anvender de metoder, der allerede har arbejdet for at give den svage lov. For at estimere hver af halesandsynlighederne 
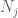
vi skal i det mindste vælge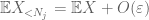


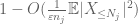

nu ser vi på bidraget fra 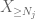
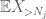
men der er et sidste kort at spille, hvilket er nul øjebliksmetoden hale estimat (4). Som tidligere nævnt er denne grænse elendig generelt-men er meget god, når den for det meste er nul, hvilket netop er situationen med 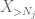


at Sætte det hele sammen, ser vi, at

opsummering af dette i j, vi ser, at vi vil blive gjort, så snart vi finder ud af, hvordan vi vælger
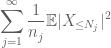
og
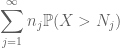
er begge endelige. (Som sædvanligt har vi en afvejning: at gøre
baseret på diskussionen tidligere er det naturligt at prøve at indstille 

og
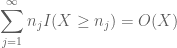
(hvor den underforståede konstant her afhænger af sekvensen 
bemærkning 1. Ovenstående bevis viser faktisk, at den stærke lov om stort antal gælder, selvom man kun antager parvis uafhængighed af 
bemærkning 2. Det er vigtigt, at de tilfældige variabler 

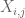
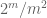
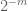




bemærkning 3. Fra interpolationsteoriens perspektiv kan man se ovenstående argument som et interpolationsargument, der etablerer et 


bemærkning 4. Ved at se sekvensen