olkoon X reaaliarvoinen satunnaismuuttuja, ja olkoon 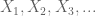
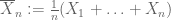
heikko suurten joukkojen laki. Oletetaan, että X: n ensimmäinen momentti
on äärellinen. Silloin
konvergoituu todennäköisyydellä
, jolloin
jokaiselle
.
vahva suurten joukkojen laki. Oletetaan, että X: n ensimmäinen momentti
.
(jos vahvistetaan ensimmäisen momentin oletus toisen momentin äärellisyydestä 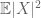
heikko laki on helppo todistaa, mutta egoroffin lauseen mukaan vahva laki (joka tietysti merkitsee heikkoa lakia) on hienovaraisempi, ja itse asiassa tämän lain todistus (olettaen vain ensimmäisen hetken finiteness) esiintyy yleensä vain edistyneissä graduate-teksteissä. Joten ajattelin esittää todisteen tässä molemmat lait, joka etenee standardin tekniikoita hetki menetelmä ja katkaisu. Painopiste tässä exposition on motivaatiota ja menetelmiä pikemmin kuin lyhyys ja vahvuus tuloksia; kirjallisuudessa on olemassa todisteita vahvasta laista, jotka on puristettu alle sivun kokoisiksi, mutta tämä ei ole tavoitteeni tässä asiassa.
– momenttimenetelmä –
momenttimenetelmä pyrkii kontrolloimaan satunnaismuuttujan häntätodennäköisyyksiä (eli todennäköisyyttä, että se vaihtelee kaukana keskiarvostaan) momenttien ja erityisesti zerothin, ensimmäisen tai toisen momentin avulla. Syy, että tämä menetelmä on niin tehokas, koska ensimmäiset hetket voidaan usein laskea melko tarkasti. The first moment method usually employs Markovin epäyhtälö
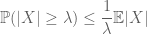
(joka seuraa ottamalla odotukset pointwise epäyhtälö 

(huomaa ,että (2) on vain (1) sovellettu satunnaismuuttuja 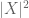

yleisesti ottaen ensimmäisen hetken laskemiseen käytetään yleensä odotuksen lineaarisuutta

kun taas laskea toinen hetki on myös ymmärrettävä kovarianssit (jotka ovat erityisen yksinkertaisia, jos yksi olettaa pairwise riippumattomuus), kiitos identiteettien kuten
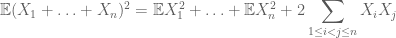
tai normalisoitu muunnos
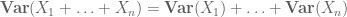

korkeammat momentit voivat periaatteessa antaa tarkempaa tietoa, mutta edellyttävät usein vahvempia oletuksia tutkittavista kappaleista, kuten yhteistä riippumattomuutta.
tässä on ensimmäisen hetken menetelmän perussovellus:
Borel-Cantellin lemma. Olkoon
sellainen tapahtumien sarja, että
on äärellinen. Silloin lähes varmasti vain finitely monet tapahtumista
pitävät paikkansa.
Proof. Olkoon 


Letting 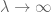

palataan suurten lukujen lakiin, ensimmäisen momentin menetelmällä saadaan seuraava pyrstö sidottuna:
heidät 1. Jos
on äärellinen, niin
.
Proof. Kolmioepäyhtälöllä 

Lemma 1 ei ole itsessään tarpeeksi vahva todistaakseen suurten lukujen lain joko heikossa tai vahvassa muodossa – etenkään se ei osoita parannusta n: n kasvaessa suureksi – mutta on hyödyllistä käsitellä yksi noiden todisteiden virhetermeistä.
voimme saada vahvempia rajoja kuin Lemma 1 – erityisesti rajoja, jotka paranevat n: llä-X: n vahvempien oletusten kustannuksella.
Lemma 2. Jos
.
Proof. Standardilaskenta, joka hyödyntää (3) ja 



päinvastaiseen suuntaan on olemassa zeroth moment method, joka tunnetaan yleisemmin nimellä union bound

tai vastaavasti (selittää terminologia ”zeroth momentti”)

ei-negatiivisille satunnaismuuttujille 
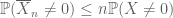
samoin kuin toinen momentti sidottuna (aine 2) on hyödyllinen vain silloin, kun on hyvä kontrolli X: n toiselle momentille (tai varianssille), on nollamomentin häntäarvio (3) hyödyllinen vain silloin, kun meillä on hyvä kontrolli nollamomentille 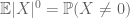
– Typistys –
toisen momentin häntäsidonnaisuus (Lemma 2) antaa jo suurten lukujen heikon lain, jos X: llä on äärellinen toinen momentti (tai vastaavasti äärellinen varianssi). Yleisesti ottaen, jos X: stä tiedetään vain, että sillä on äärellinen ensimmäinen momentti, emme voi päätellä, että X: llä on äärellinen toinen momentti. Voimme kuitenkin suorittaa katkaisun
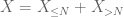
X millä tahansa halutulla raja-arvolla N, jossa 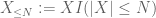

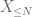
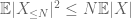
ja siten myös meillä on rajallinen varianssi
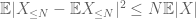
toisella termillä 
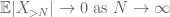
kolmioepäyhtälön perusteella voidaan päätellä, että ensimmäisellä termillä
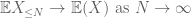
nämä ovat kaikki ne työkalut, joita tarvitsemme todistaaksemme suurten lukujen heikon lain:
todiste heikosta laista. Olkoon 

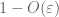
From (7), (8), voidaan löytää kynnys N (riippuen 
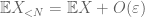

ensimmäisestä hetkestä häntään sidottuna (Lemma 1)tiedetään, että 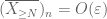
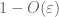
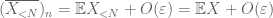
— vahva laki –
vahva laki voidaan todistaa viemällä edellä mainittuja menetelmiä hieman pidemmälle ja käyttämällä muutamaa kikkaa lisää.
ensimmäinen kikka on todeta, että vahvan lain todistamiseksi riittää, että näin tehdään ei-negatiivisille satunnaismuuttujille 

kun X on ei-negatiivinen, näemme, että empiiriset keskiarvot

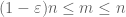
tämän kvasimonotonisuuden vuoksi voimme harventaa joukkoa n, jolle meidän on todistettava vahva laki. Tarkemmin se riittää osoittamaan
vahvan suurten lukujen lain, pelkistetyn version. Olkoon
ei-negatiivinen satunnaismuuttuja, jolla on
, ja olkoon
kokonaislukujen jono, joka on lacunaarinen siinä mielessä, että
joillekin
ja kaikki riittävän suuret j. silloin
konvergoituu lähes varmasti
toden totta, jos voisimme todistaa supistetun version, niin sovellettaessa tätä versiota lacunary sequence 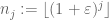


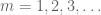
nyt kun sekvenssiä on harvennettu, Borel-Cantellin lemman soveltaminen käy taloudelliseksi. Itse asiassa monet sovellukset, että heidät näemme, että se riittää osoittamaan, että

äärellisen ensimmäisen momentin ei-negatiiviselle X: lle mikä tahansa lacunary sequence 
tässä vaiheessa mennään takaisin ja sovelletaan jo toimineita menetelmiä heikon lain antamiseksi. Estimoidaksemme jokaisen pyrstötodennäköisyyden 
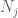
pitäisi ainakin valita 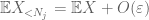


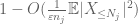

nyt tarkastellaan 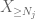
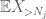
mutta pelissä on vielä yksi kortti, joka on zeroth moment method tail estimate (4). Kuten aiemmin mainittiin, tämä sidottu on yleisesti surkea – mutta on erittäin hyvä, kun X on enimmäkseen nolla, mikä on juuri tilanne 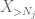


kun tämä kaikki kootaan, nähdään, että

summaamalla tämän J: ssä näemme, että homma hoituu heti, kun selvitämme, miten
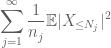
ja
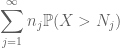
ovat molemmat äärellisiä. (Kuten tavallista, meillä on tradeoff: tehdä
aikaisemman keskustelun perusteella on luontevaa kokeilla asetelmaa 

ja
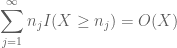
(missä implisiittinen vakio tässä riippuu jaksosta 
Huomautus 1. Edellä esitetty todiste itse asiassa osoittaa, että vahva suurten lukujen laki pätee, vaikka otettaisiin vain 
Huomautus 2. On tärkeää,että satunnaismuuttujat 

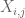
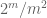
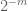



Huomautus 3. Interpolointiteorian näkökulmasta edellä mainittua argumenttia voidaan pitää interpolointiargumenttina, jolloin saadaan 


Huomautus 4. Tarkastelemalla lukujonoa 