legyen X valós értékű véletlen változó, és legyen 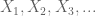
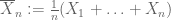
a nagy számok gyenge törvénye. Tegyük fel, hogy az első pillanat
x véges. Akkor
konvergál a valószínűsége, hogy
, így
minden
.
a nagy számok erős törvénye. Tegyük fel, hogy az első pillanat
.
(ha valaki megerősíti az első pillanat feltételezését a második pillanat végességére 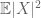
a gyenge törvényt könnyű bizonyítani, de az erős törvény (ami természetesen magában foglalja a gyenge törvényt, Egoroff tétele szerint) finomabb, és valójában ennek a törvénynek a bizonyítása (feltételezve az első pillanat végességét) általában csak a fejlett diplomás szövegekben jelenik meg. Ezért úgy gondoltam, hogy itt bemutatom mindkét törvény bizonyítékát, amely a moment módszer és a csonkolás szokásos technikáival folytatódik. A hangsúly ebben a kiállítás lesz a motiváció és módszerek helyett rövidsége és ereje eredmények; az irodalomban léteznek olyan erős törvények bizonyítékai, amelyeket egy oldal vagy annál kisebb méretre tömörítettek, de itt nem ez a célom.
— a moment módszer —
a moment módszer egy véletlen változó farok valószínűségének (azaz annak a valószínűségének, hogy az átlagától messze ingadozik) szabályozására törekszik pillanatok, különösen a nulladik, első vagy második pillanat segítségével. Ennek a módszernek az az oka, hogy az első néhány pillanat gyakran meglehetősen pontosan kiszámítható. Az első pillanat módszer általában Markov egyenlőtlenségét alkalmazza
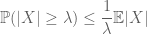
(ami a pontonkénti egyenlőtlenség elvárásainak figyelembevételével következik 

(vegye figyelembe, hogy a (2) csak (1) alkalmazható a 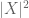

Általánosságban elmondható, hogy az első pillanat kiszámításához általában a várakozás linearitását alkalmazzák

míg a második pillanat kiszámításához meg kell érteni a kovarianciákat is (amelyek különösen egyszerűek, ha páros függetlenséget feltételezünk), az olyan identitásoknak köszönhetően, mint például
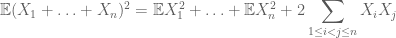
vagy a normalizált változat
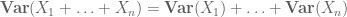

a magasabb pillanatok elvileg pontosabb információkat adhatnak, de gyakran erősebb feltételezéseket igényelnek a vizsgált tárgyakról, például a közös függetlenségről.
itt van az első pillanat módszer alapvető alkalmazása:
Borel-Cantelli lemma. Legyen
olyan eseménysorozat, hogy
véges. Akkor szinte biztosan, csak véges sok esemény
igaz.
bizonyíték. Legyen 


bérbeadás 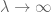
visszatérve a nagy számok törvényéhez, az első pillanat módszer a következő farokkötést adja:
Lemma 1. Ha
véges, akkor
.
bizonyíték. A háromszög egyenlőtlenség szerint 

a Lemma 1 önmagában nem elég erős ahhoz, hogy a nagy számok törvényét gyenge vagy erős formában bizonyítsa – különösen nem mutat javulást, mivel n nagy lesz–, de hasznos lesz kezelni az egyik hibakifejezést ezekben a bizonyításokban.
erősebb határokat kaphatunk, mint a Lemma 1 – különösen azokat a határokat, amelyek az n – vel javulnak-az X-re vonatkozó erősebb feltételezések rovására.
Lemma 2. Ha
.
bizonyíték. A (3) és a 




ellenkező irányban van a nulladik pillanat módszer, ismertebb nevén az Unió kötött

vagy ezzel egyenértékű (a “nulla pillanat ” terminológia magyarázata”)

bármely nem negatív véletlen változóra 
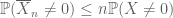
csakúgy, mint a második pillanatban kötött (Lemma 2) csak akkor hasznos, ha az egyik jól kontroll a második pillanatban (vagy variancia) X, a nulladik pillanatban farok becslés (3) csak akkor hasznos, ha van jó kontroll a nulladik pillanatban 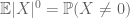
— csonkolás —
a második pillanatban farok kötött (Lemma 2) már megadja a nagy számok gyenge törvényét abban az esetben, ha X véges második pillanattal rendelkezik (vagy ekvivalensen véges variancia). Általában, ha csak annyit tudunk X-ről, hogy véges az első pillanata, akkor nem vonhatjuk le azt a következtetést, hogy X-nek véges a második pillanata. Azonban el tudunk végezni egy csonkolást
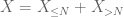
bármely kívánt n küszöbértéknél, ahol 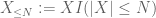

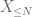
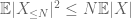
ezért is van véges variancia
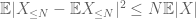
a második kifejezésnek 
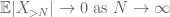
a háromszög egyenlőtlenség alapján arra a következtetésre jutunk, hogy az első kifejezés
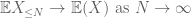
ezekre az eszközökre van szükségünk a nagy számok gyenge törvényének bizonyításához:
a gyenge törvény bizonyítása. Legyen 

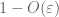
tól (7), (8), találunk egy n küszöbértéket (a 
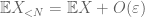

a farok megkötésének első pillanatától (Lemma 1) tudjuk, hogy 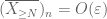
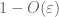
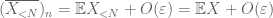
— az erős törvény –
az erős törvény bizonyítható a fenti módszerek egy kicsit tovább tolásával, néhány további trükkövel.
az első trükk az, hogy megfigyeljük, hogy az erős törvény bizonyításához elegendő ezt megtenni a 

ha X nem negatív, látjuk, hogy az empirikus átlagok

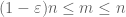
ennek a kvazimonotonitásnak köszönhetően meg tudjuk szórni az n halmazát, amelyre be kell bizonyítanunk az erős törvényt. Pontosabban, elegendő a
nagy számok erős törvénye, csökkentett változat megjelenítése. Legyen
nem negatív véletlen változó
, és legyen
egész számok sorozata, amely hézagos abban az értelemben, hogy
néhány
és minden kellően nagy j. akkor
konvergál szinte biztosan
valóban, ha bizonyítani tudnánk a csökkentett verziót, akkor ezt a verziót a lacunary szekvenciára alkalmazva 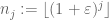

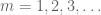

most, hogy sparsifikáltuk a szekvenciát, gazdaságossá válik a Borel-Cantelli lemma alkalmazása. Valójában a lemma számos alkalmazásával látjuk, hogy elegendő ezt megmutatni

a véges első Momentum nem-negatív X-jére bármely lacunáris szekvencia 
ezen a ponton visszamegyünk, és alkalmazzuk azokat a módszereket, amelyek már működtek a gyenge törvény megadására. Nevezetesen az egyes farok valószínűségek becsléséhez 
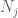
legalább a 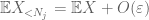


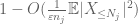

most nézzük meg a 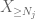
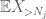
de van egy utolsó kártya játszani, amely a nulladik pillanatban módszer farok becslés (4). Mint korábban említettük, ez a kötés általában pocsék – de nagyon jó, ha X többnyire nulla, pontosan ez a helyzet 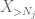


mindezt összerakva látjuk, hogy

Összefoglalva ezt a j, azt látjuk, hogy mi lesz tenni, amint kitaláljuk, hogyan kell kiválasztani
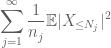
és
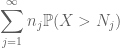
mindkettő véges. (Mint általában, van egy kompromisszumunk: a
a korábbi vita alapján természetes, hogy megpróbálja beállítani a 

és
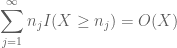
(ahol az implikált állandó itt a 
1.Megjegyzés. A fenti bizonyíték valójában azt mutatja, hogy a nagy számok erős törvénye akkor is fennáll, ha csak a 
Megjegyzés 2. Alapvető fontosságú,hogy a 

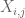
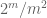
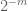



Megjegyzés 3. Az interpolációelmélet szempontjából a fenti érvet interpolációs érvként tekinthetjük meg, amely 


4.Megjegyzés. A 