Sia X una variabile casuale a valore reale e sia 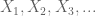
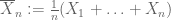
Legge debole dei grandi numeri. Supponiamo che il primo momento
di X sia finito. Quindi
converge in probabilità a
, quindi
per tutti
.
Forte legge di grandi numeri. Supponiamo che il primo momento
.
(Se si rafforza l’ipotesi del primo momento a quella della finitezza del secondo momento 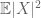
La legge debole è facile da dimostrare, ma la legge forte (che ovviamente implica la legge debole, dal teorema di Egoroff) è più sottile, e in effetti la prova di questa legge (assumendo solo la finitezza del primo momento) di solito appare solo nei testi laureati avanzati. Quindi ho pensato di presentare una prova qui di entrambe le leggi, che procede con le tecniche standard del metodo del momento e del troncamento. L’enfasi in questa esposizione sarà sulla motivazione e sui metodi piuttosto che sulla brevità e sulla forza dei risultati; esistono prove della legge forte in letteratura che sono state compresse fino alle dimensioni di una pagina o meno, ma questo non è il mio obiettivo qui.
— Il metodo del momento —
Il metodo del momento cerca di controllare le probabilità di coda di una variabile casuale (cioè la probabilità che fluttui lontano dalla sua media) per mezzo di momenti, e in particolare lo zeroth, il primo o il secondo momento. La ragione per cui questo metodo è così efficace è perché i primi momenti possono spesso essere calcolati in modo piuttosto preciso. Il primo momento metodo di solito impiega la disuguaglianza di Markov
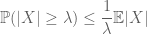
(che segue, prendendo le aspettative di puntuale disuguaglianza 

(si noti che la (2) è giusto (1) applicato alla variabile casuale 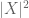

in generale, per calcolare primo momento, di solito si impiega linearità di attesa

mentre per calcolare il secondo momento in cui uno deve anche comprendere covarianze (che sono particolarmente semplice se si parte dal presupposto coppie di indipendenza), grazie alla identità come
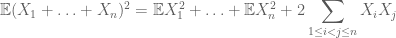
o normalizzata variante
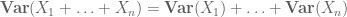

I momenti superiori possono in linea di principio fornire informazioni più precise, ma spesso richiedono ipotesi più forti sugli oggetti studiati, come l’indipendenza congiunta.
Ecco un’applicazione di base del metodo first moment:
Lemma di Borel-Cantelli. Sia
una sequenza di eventi tale che
è finita. Quindi quasi sicuramente, solo finitamente molti degli eventi
sono veri.
Prova. Sia

\in questo modo, il sistema di visualizzazione è in grado di eseguire il processo di visualizzazione.
Lasciando 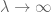

Tornando alla legge dei grandi numeri, il metodo first moment fornisce il seguente tail bound:
Lemma 1. (Primo momento tail bound) Se
è finito, allora
\in questo caso, è possibile utilizzare la funzione di visualizzazione.
Prova. Dalla disuguaglianza del triangolo, 

Il Lemma 1 non è abbastanza forte da solo per dimostrare la legge dei grandi numeri in forma debole o forte – in particolare, non mostra alcun miglioramento man mano che n diventa grande – ma sarà utile gestire uno dei termini di errore in quelle prove.
Possiamo ottenere limiti più forti del Lemma 1 – in particolare, limiti che migliorano con n – a scapito di ipotesi più forti su X.
Lemma 2. (Second moment tail bound) Se
\in questo modo, il sistema di visualizzazione è in grado di eseguire il processo di visualizzazione.
Prova. Standard di calcolo, sfruttando la (3) e le coppie indipendenza del 



Nella direzione opposta, c’è il numero zero momento di metodo, più comunemente conosciuto come l’unione vincolato

o, equivalentemente, (per spiegare la terminologia “momento zero”)

per tutti i non-negativo variabili casuali 
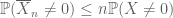
Proprio come il secondo momento legato (Lemma 2) è utile solo quando si ha un buon controllo sul secondo momento (o varianza) di X, la stima della coda del momento zeroth (3) è utile solo quando abbiamo un buon controllo sul momento zeroth 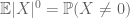
— Troncamento —
Il secondo momento tail bound (Lemma 2) dà già la legge debole dei grandi numeri nel caso in cui X abbia un secondo momento finito (o equivalentemente, varianza finita). In generale, se tutto ciò che si sa su X è che ha un primo momento finito, allora non possiamo concludere che X abbia un secondo momento finito. Tuttavia, possiamo eseguire un troncamento
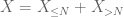
di X a qualsiasi soglia desiderata N, dove 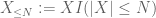

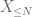
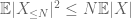
e quindi anche noi abbiamo varianza finita
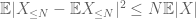
Il secondo termine 
\per maggiori informazioni, consulta la nostra informativa. (7)
Dalla disuguaglianza triangolare, concludiamo che il primo termine
\in questo caso, è possibile utilizzare la funzione di visualizzazione. (8)
Questi sono tutti gli strumenti di cui abbiamo bisogno per dimostrare la legge debole dei grandi numeri:
Prova della legge debole. Sia 

Da (7), (8), possiamo trovare una soglia N (a seconda di 
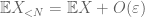
\in questo modo è possibile creare un sistema di visualizzazione.
Dal primo momento tail bound (Lemma 1), sappiamo che 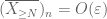
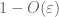
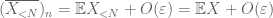
— La legge forte –
La legge forte può essere dimostrata spingendo un po ‘ oltre i metodi di cui sopra e usando alcuni trucchi.
Il primo trucco è osservare che per dimostrare la legge forte, è sufficiente farlo per variabili casuali non negative 

Una volta che X non è negativo, vediamo che le medie empiriche
\se si utilizza un file di testo, è possibile utilizzare un file di testo. (9)
A causa di questa quasimonotonicità, possiamo disperdere l’insieme di n per il quale abbiamo bisogno di dimostrare la legge forte. Più precisamente, è sufficiente mostrare
Legge forte di grandi numeri, versione ridotta. Let
essere non negativo variabile casuale con
, e lasciare che
essere una sequenza di numeri interi che è lacunary nel senso che
alcuni
e tutti sufficientemente grande j. Quindi
converge quasi certamente
Infatti, se potessimo provare la versione ridotta, allora applicando quella versione alla sequenza lacunaria 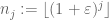


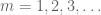
Ora che abbiamo sparsificato la sequenza, diventa economico applicare il lemma di Borel-Cantelli. Infatti, da molte applicazioni del lemma vediamo che basta a mostrare che

per non negativo X finite primo momento, qualsiasi lacunary sequenza 
A questo punto torniamo indietro e applichiamo i metodi che già funzionavano per dare la legge debole. Vale a dire, per stimare ciascuna delle probabilità di coda 
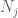
Dovremmo almeno scegliere 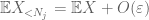


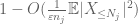

Ora guardiamo il contributo di 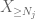
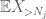
Ma c’è un’ultima carta da giocare, che è il metodo zeroth moment tail estimate (4). Come accennato in precedenza, questo limite è pessimo in generale, ma è molto buono quando X è per lo più zero, che è precisamente la situazione con 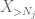


Mettendo tutto questo insieme, vediamo che

Sommando questo a j, vediamo che sarà fatto non appena avremo capire come scegliere
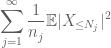
e
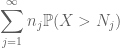
sono entrambi finiti. (Come al solito, abbiamo un compromesso: rendere il
In base alla discussione precedente, è naturale provare a impostare 

e
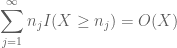
(dove l’implicita costante qui dipende dalla sequenza 
Osservazione 1. La prova di cui sopra, infatti, mostra che la forte legge dei grandi numeri vale anche se si assume solo l’indipendenza a coppie del 

Nota 2. È essenziale che le variabili casuali 

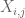
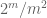
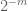



Nota 3. Dal punto di vista della teoria dell’interpolazione, si può vedere l’argomento sopra come un argomento di interpolazione, stabilendo una stima 


Nota 4. Visualizzando la sequenza