Een diepgaande kijk op deze gevaarlijke misbruik van microprocessor kwetsbaarheden en waarom is er misschien meer van hen die er

we zijn gewend computerprocessors te zien als ordelijke machines die met volledige regelmaat van de ene eenvoudige instructie naar de volgende gaan. Maar de waarheid is, dat ze al tientallen jaren hun taken buiten de orde doen en gewoon gissen naar wat er nu moet komen. Ze zijn er natuurlijk erg goed in. Zo goed in feite, dat dit vermogen, genaamd speculatieve uitvoering, een groot deel van de verbetering van de rekenkracht in de afgelopen 25 jaar of zo heeft ondersteund. Maar op 3 januari 2018 leerde de wereld dat deze truc, die zoveel voor moderne computers had gedaan, nu een van de grootste kwetsbaarheden was.In 2017 werkten onderzoekers van Cyberus Technology, Google Project Zero, Graz University of Technology, Rambus, University of Adelaide en University of Pennsylvania, evenals onafhankelijke onderzoekers zoals cryptograaf Paul Kocher, afzonderlijk aanvallen uit die profiteerden van speculatieve uitvoering. Onze eigen groep had de oorspronkelijke kwetsbaarheid ontdekt achter een van deze aanvallen in 2016, maar we hebben niet alle stukjes bij elkaar.
dit soort aanvallen, genaamd Meltdown en Spectre, waren geen gewone bugs. Op het moment dat het werd ontdekt, Meltdown kon hacken alle Intel x86 microprocessors en IBM Power processors, evenals een aantal ARM-gebaseerde processors. Spectre en zijn vele variaties toegevoegd Advanced Micro Devices (AMD) processors aan die lijst. Met andere woorden, bijna de hele computerwereld was kwetsbaar.
en omdat speculatieve uitvoering grotendeels in de processorhardware zit, was het oplossen van deze kwetsbaarheden geen gemakkelijke taak. Door dit te doen zonder dat computing snelheden te slijpen in lage versnelling heeft het nog moeilijker gemaakt. In feite, een jaar later, is het werk nog lang niet voorbij. Security patches waren niet alleen nodig van de processor makers, maar van degenen verderop in de supply chain, zoals Apple, Dell, Linux en Microsoft. De eerste computers aangedreven door chips die opzettelijk zijn ontworpen om bestand te zijn tegen zelfs een aantal van deze kwetsbaarheden zijn pas onlangs aangekomen.
Spectre en Meltdown zijn het resultaat van het verschil tussen wat software verondersteld wordt te doen en de microarchitectuur van de processor—de details van hoe het deze dingen feitelijk doet. Deze twee klassen van hacks hebben ontdekt een manier voor informatie te lekken door middel van dat verschil. En er is alle reden om te geloven dat er meer manieren zullen worden ontdekt. We hielpen twee, Branchscope en SpectreRSB , vorig jaar.
als we het tempo van computerverbeteringen door willen laten gaan zonder de beveiliging op te offeren, zullen we moeten begrijpen hoe deze hardware kwetsbaarheden gebeuren. Dat begint met het begrijpen van Spectre en Meltdown.
in moderne computersystemen worden softwareprogramma ‘ s die in begrijpelijke talen zijn geschreven, zoals C++, gecompileerd in assemblagetaalinstructies-fundamentele bewerkingen die de computerprocessor kan uitvoeren. Om de uitvoering te versnellen, gebruiken moderne processors een aanpak genaamd pipelining. Net als een lopende band is de pijpleiding een reeks fasen, die elk een stap zijn die nodig is om een instructie te voltooien. Sommige typische stadia voor een Intel x86 processor zijn degenen die de instructie vanuit het geheugen brengen en decoderen om te begrijpen wat de instructie betekent. Pipelining brengt in principe parallellisme naar het niveau van instructie uitvoering: wanneer een instructie wordt gedaan met behulp van een fase, de volgende instructie is vrij om het te gebruiken.Sinds de jaren negentig hebben microprocessoren twee trucs gebruikt om het pijpleidingsproces te versnellen: buiten gebruik gestelde uitvoering en speculatie. Als twee instructies onafhankelijk van elkaar zijn—dat wil zeggen, de uitvoer van de ene heeft geen invloed op de invoer van de andere—kunnen ze opnieuw worden gerangschikt en hun resultaat zal nog steeds correct zijn. Dat is handig, omdat het de processor in staat stelt om te blijven werken als een instructie vastloopt in de pijplijn. Bijvoorbeeld, als een instructie gegevens vereist die in het DRAM-hoofdgeheugen zijn in plaats van in het cachegeheugen in de CPU zelf, kan het een paar honderd klokcycli vergen om die gegevens te krijgen. In plaats van te wachten, kan de processor een andere instructie door de pijplijn verplaatsen.
de tweede truc is speculatie. Om het te begrijpen, beginnen met het feit dat sommige instructies noodzakelijkerwijs leiden tot een verandering in welke instructies komen volgende. Overweeg een programma met een ” if ” statement: Het controleert op een voorwaarde, en als de voorwaarde Waar is, springt de processor naar een andere locatie in het programma. Dit is een voorbeeld van een conditional-branch instructie, maar er zijn andere instructies die ook leiden tot veranderingen in de stroom van instructies.
overweeg nu wat er gebeurt als een dergelijke branch instructie een pijplijn binnenkomt. Het is een situatie die leidt tot een raadsel. Wanneer de instructie aan het begin van de pijpleiding aankomt, weten we de uitkomst niet totdat het vrij diep in de pijpleiding is gevorderd. En zonder dit resultaat te weten, kunnen we de volgende instructie niet halen. Een eenvoudige maar naïeve oplossing is om te voorkomen dat nieuwe instructies de pijplijn binnenkomen totdat de branch instructie een punt bereikt waarop we weten waar de volgende instructie vandaan komt. Veel klokcycli worden verspild in dit proces, omdat pijpleidingen meestal 15 tot 25 fasen hebben. Erger nog, branch instructies komen heel vaak, goed voor meer dan 20 procent van alle instructies in veel programma ‘ s.
om de hoge prestatiekosten van het blokkeren van de pijplijn te vermijden, Gebruiken moderne processors een architectonische eenheid genaamd een branch predictor om te raden waar de volgende instructie, na een branch, vandaan zal komen. Het doel van deze voorspeller is om te speculeren over een paar belangrijke punten. Ten eerste, zal een voorwaardelijke branch worden genomen, waardoor het programma naar een andere sectie van het programma gaat, of zal het doorgaan op het bestaande pad? En ten tweede, als de branch wordt genomen, waar zal het programma naar toe gaan—wat zal de volgende instructie zijn? Gewapend met deze voorspellingen kan de processorpijplijn volgehouden worden.
omdat de uitvoering van de instructie gebaseerd is op een voorspelling, wordt deze “speculatief” uitgevoerd: als de voorspelling correct is, verbetert de prestatie aanzienlijk. Maar als de voorspelling onjuist blijkt, moet de processor in staat zijn om de effecten van speculatief uitgevoerde instructies relatief snel ongedaan te maken.
het ontwerp van de sectorvoorspeller wordt al vele jaren grondig onderzocht in de computerarchitectuurgemeenschap. Moderne voorspellers gebruiken de geschiedenis van uitvoering binnen een programma als basis voor hun resultaten. Deze regeling behaalt nauwkeurigheid van meer dan 95 procent op veel verschillende soorten programma ‘ s, wat leidt tot dramatische prestatieverbeteringen, in vergelijking met een microprocessor die niet speculeert. Misspeculatie is echter mogelijk. Helaas is het de misspeculatie die de Spectre aanvalt.
een andere vorm van speculatie die tot problemen heeft geleid is speculatie binnen een enkele instructie in de pijplijn. Dat is een nogal vaag concept, dus laten we het uitpakken. Stel dat een instructie toestemming vereist om uit te voeren. Bijvoorbeeld, een instructie kan de computer om een stuk van de gegevens te schrijven naar het gedeelte van het geheugen gereserveerd voor de kern van het besturingssysteem. Je zou niet willen dat dat gebeurt, tenzij het is goedgekeurd door het besturingssysteem zelf, of je zou het risico lopen de computer te laten crashen. Voorafgaand aan de ontdekking van Meltdown en Spectre, de conventionele wijsheid was dat het goed is om te beginnen met het uitvoeren van de instructie speculatief zelfs voordat de processor het punt van het controleren of de instructie heeft toestemming om zijn werk te doen heeft bereikt.
uiteindelijk, als de toestemming niet tevreden is—in ons voorbeeld heeft het besturingssysteem deze poging om te knoeien met het geheugen niet gesanctioneerd—worden de resultaten weggegooid en geeft het programma een fout aan. In het algemeen, de processor kan speculeren rond een deel van een instructie die zou kunnen leiden tot het wachten, op voorwaarde dat de aandoening Uiteindelijk is opgelost en alle resultaten van slechte gissingen zijn, effectief, ongedaan gemaakt. Het is dit soort intra-instructie speculatie dat is achter alle varianten van de kernsmelting bug, met inbegrip van de misschien gevaarlijker versie, Voorafschaduw.
het inzicht dat speculatieaanvallen mogelijk maakt is dit: tijdens misspeculatie vindt er geen verandering plaats die een programma direct kan waarnemen. Met andere woorden, er is geen programma dat je zou kunnen schrijven dat zou gewoon alle gegevens die zijn gegenereerd tijdens speculatieve uitvoering weer te geven. Echter, het feit dat speculatie plaatsvindt laat sporen door te beïnvloeden hoe lang het duurt instructies uit te voeren. Helaas is het nu duidelijk dat we deze tijdssignalen kunnen detecteren en er geheime gegevens uit kunnen halen.
Wat is deze timing informatie, en hoe krijgt een hacker het te pakken? Om dat te begrijpen, moet je het concept van zijkanalen begrijpen. Een zijkanaal is een onbedoelde route die informatie lekt van de ene entiteit naar de andere (meestal zijn beide software programma ‘ s), meestal via een gedeelde bron zoals een harde schijf of geheugen.
als voorbeeld van een zijkanaalaanval wordt een apparaat beschouwd dat geprogrammeerd is om te luisteren naar het geluid dat van een printer afkomstig is en dat vervolgens gebruikt om af te leiden wat er wordt afgedrukt. Het geluid, in dit geval, is een zijkanaal.
in microprocessors kan elke gedeelde hardwarebron in principe worden gebruikt als een zijkanaal dat informatie lekt van een slachtoffer-programma naar een aanvaller-programma. In een veelgebruikte side-channel aanval is de gedeelde bron de cache van de CPU. De cache is een relatief klein, snel toegangsgeheugen op de processorchip die wordt gebruikt om de gegevens op te slaan die het vaakst nodig zijn door een programma. Wanneer een programma toegang heeft tot het geheugen, controleert de processor eerst de cache; als de gegevens er zijn (een cache hit), wordt het snel hersteld. Als de gegevens niet in de cache (een miss), de processor moet wachten tot het wordt opgehaald uit het hoofdgeheugen, die enkele honderden klokcycli kan nemen. Maar zodra de gegevens komen uit het hoofdgeheugen, het is toegevoegd aan de cache, die kan vereisen gooien uit een aantal andere gegevens om ruimte te maken. De cache is verdeeld in segmenten genaamd cache sets, en elke locatie in het hoofdgeheugen heeft een overeenkomstige set in de cache. Deze organisatie maakt het gemakkelijk om te controleren of er iets in de cache zit zonder het hele ding te hoeven doorzoeken.
cache-gebaseerde aanvallen waren al uitgebreid onderzocht voordat Spectre en Meltdown op het toneel verschenen. Hoewel de aanvaller niet direct kan lezen gegevens van het slachtoffer—zelfs als die gegevens zit in een gedeelde bron zoals de cache—de aanvaller kan informatie over het geheugen adressen toegankelijk door het slachtoffer te krijgen. Deze adressen kunnen afhangen van gevoelige gegevens, waardoor een slimme aanvaller om deze geheime gegevens te herstellen.
Hoe doet de aanvaller dit? Er zijn verschillende manieren. Een variant, genaamd Flush en Reload, begint met de aanvaller verwijderen van gedeelde gegevens uit de cache met behulp van de “flush” instructie. De aanvaller wacht dan op het slachtoffer om toegang te krijgen tot die gegevens. Omdat het niet meer in de cache, alle gegevens van het slachtoffer verzoeken moeten worden gebracht uit het hoofdgeheugen. Later, de aanvaller toegang tot de gedeelde gegevens terwijl de timing hoe lang dit duurt. Een cache hit-wat betekent dat de gegevens is terug in de cache—geeft aan dat het slachtoffer toegang tot de gegevens. Een cache miss geeft aan dat de gegevens niet zijn benaderd. Zo, gewoon door te meten hoe lang het duurde om toegang te krijgen tot gegevens, de aanvaller kan bepalen welke cache sets werden geopend door het slachtoffer. Het duurt een beetje van algoritmische magie, maar deze kennis van welke cache sets werden benaderd en die niet waren kan leiden tot de ontdekking van encryptiesleutels en andere geheimen.
Meltdown, Spectre en hun varianten volgen allemaal hetzelfde patroon. Ten eerste, ze activeren speculatie om code gewenst door de aanvaller uit te voeren. Deze code leest geheime gegevens zonder toestemming. Dan, de aanvallen communiceren het geheim met behulp van Flush en Reload of een vergelijkbaar zijkanaal. Dat laatste deel is goed begrepen en vergelijkbaar in alle van de aanval variaties. Dus, de aanvallen verschillen alleen in de eerste component, dat is hoe te activeren en speculatie te exploiteren.
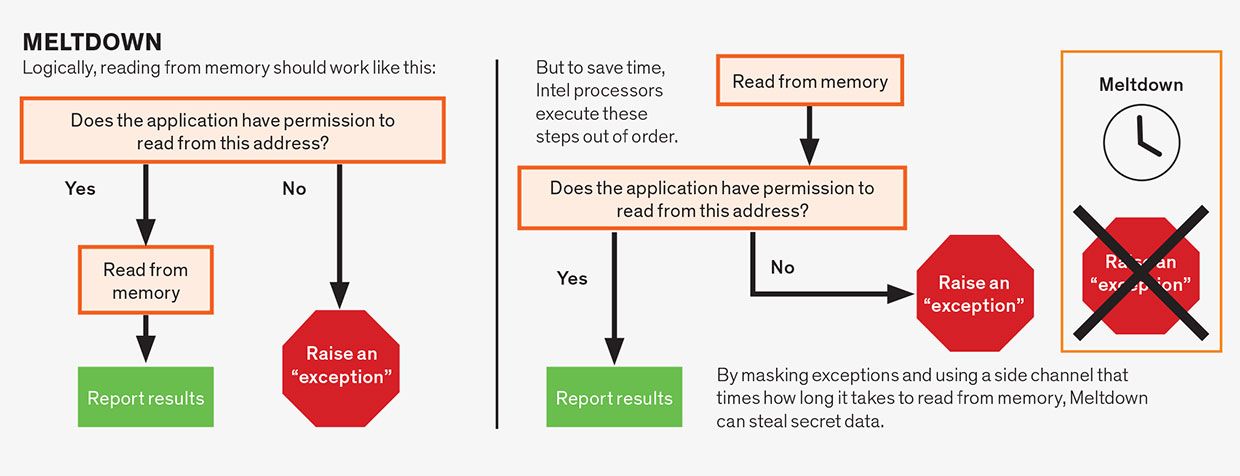
Meltdown Attacks
Meltdown attacks maken gebruik van speculatie binnen een enkele instructie. Hoewel assembler-taal instructies meestal eenvoudig zijn, bestaat een enkele instructie vaak uit meerdere operaties die van elkaar afhankelijk kunnen zijn. Bijvoorbeeld, geheugen-lezen operaties zijn vaak afhankelijk van de instructie die voldoet aan de machtigingen geassocieerd met het geheugen adres wordt gelezen. Een toepassing heeft meestal toestemming om alleen te lezen uit het geheugen dat is toegewezen aan het, niet uit het geheugen toegewezen aan, laten we zeggen, het besturingssysteem of een ander programma van de gebruiker. Logischerwijs moeten we de permissies controleren voordat het lezen doorgaat, Wat is wat sommige microprocessors doen, met name die van AMD. Echter, op voorwaarde dat het eindresultaat correct is, CPU-ontwerpers ervan uitgegaan dat ze vrij waren om speculatief uit te voeren deze operaties buiten de orde. Daarom lezen Intel microprocessors de geheugenlocatie voor het controleren van permissies, maar” commit ” de instructie—waardoor de resultaten zichtbaar worden voor het programma—wanneer aan de permissies wordt voldaan. Maar omdat de geheime gegevens speculatief zijn opgehaald, kan het worden ontdekt met behulp van een zijkanaal, waardoor Intel-processors kwetsbaar zijn voor deze aanval.
de Voorafschaduw aanval is een variatie van de kernsmelting kwetsbaarheid. Deze aanval beà nvloedt Intel microprocessors vanwege een zwakte die Intel L1 Terminal Fault (L1TF) noemt. Terwijl de oorspronkelijke Kernsmelting aanval vertrouwde op een vertraging in het controleren van machtigingen, Voorafschaduw is gebaseerd op speculatie die optreedt tijdens een fase van de pijplijn genaamd adres vertaling.
Software beschouwt het geheugen en de opslagmiddelen van de computer als één aaneengesloten stuk virtueel geheugen. Maar fysiek worden deze activa verdeeld en gedeeld tussen verschillende programma ‘ s en processen. Address translation maakt van een virtueel geheugenadres een fysiek geheugenadres.
gespecialiseerde circuits op de microprocessor helpen met de virtuele-naar-fysieke geheugen-adres vertaling, maar het kan traag zijn, waardoor meerdere geheugen lookups nodig zijn. Om dingen te versnellen, Intel microprocessors toestaan speculatie tijdens het vertaalproces, waardoor een programma speculatief lezen van de inhoud van een deel van de cache genaamd L1, ongeacht wie eigenaar is van die gegevens. De aanvaller kan dit doen, en dan onthullen de gegevens met behulp van de side-channel aanpak die we al beschreven.
in sommige opzichten is voorafschaduwing gevaarlijker dan kernsmelting, in andere opzichten minder. In tegenstelling tot Meltdown, kan Foreshadow alleen de inhoud van de L1-cache lezen, vanwege de specifieke kenmerken van Intel ‘ s implementatie van de processorarchitectuur. Echter, Voorafschaduw kan elke inhoud in L1 te lezen – niet alleen gegevens adresseerbaar door het programma.
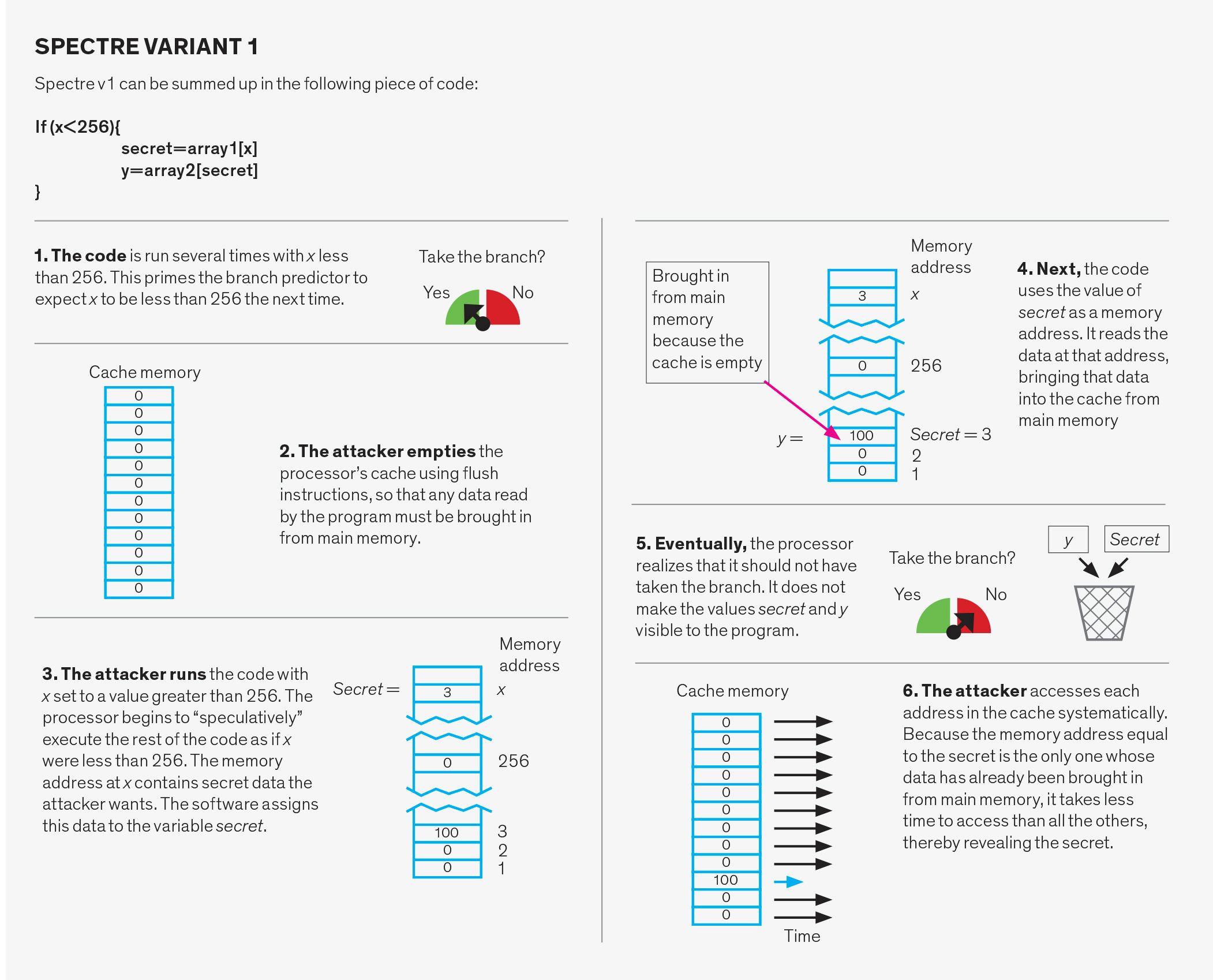
Spectre-aanvallen
Spectre-aanvallen manipuleren het branch-voorspellingssysteem. Dit systeem bestaat uit drie delen: de branch-direction predictor, de branch-target predictor en de return stack buffer.
de branch-direction predictor voorspelt of een voorwaardelijke branch, zoals die wordt gebruikt om een “if” – statement in een programmeertaal te implementeren, al dan niet zal worden ingenomen. Om dit te doen, volgt het het eerdere gedrag van soortgelijke branches. Het kan bijvoorbeeld betekenen dat als een tak twee keer achter elkaar wordt genomen, toekomstige voorspellingen zullen zeggen dat het moet worden genomen.
de branch-target predictor voorspelt het doelgeheugenadres van wat indirecte branches worden genoemd. In een voorwaardelijke branch wordt het adres van de volgende instructie gespeld, maar voor een indirecte branch moet dat adres eerst worden berekend. Het systeem dat deze resultaten voorspelt is een cache structuur genaamd de branch-target buffer. Het houdt in wezen het laatst berekende doel van de indirecte takken bij en gebruikt deze om te voorspellen waar de volgende indirecte tak tot moet leiden.
de return stack buffer wordt gebruikt om het doel van een “return” instructie te voorspellen. Wanneer een subroutine wordt “aangeroepen” tijdens een programma, zorgt de return instructie ervoor dat het programma weer werkt op het punt waarvandaan de subroutine werd aangeroepen. Proberen om het juiste punt te voorspellen om naar terug te keren alleen op basis van eerdere retouradressen zal niet werken, omdat dezelfde functie kan worden aangeroepen vanaf veel verschillende locaties in de code. In plaats daarvan gebruikt het systeem de return stack buffer, een stukje geheugen op de processor, dat de return adressen van functies houdt zoals ze worden genoemd. Het gebruikt dan deze adressen wanneer een return wordt aangetroffen in de code van de subroutine.
elk van deze drie structuren kan op twee verschillende manieren worden benut. Ten eerste kan de voorspeller opzettelijk mishandeld worden. In dit geval, de aanvaller voert schijnbaar onschuldige code ontworpen om het systeem te verwarren. Later voert de aanvaller opzettelijk een branch uit die zal misspeculeren, waardoor het programma springt naar een stuk code gekozen door de aanvaller, genaamd een gadget. De gadget zet dan over het stelen van gegevens.
een tweede manier van Spectre aanval wordt directe injectie genoemd. Het blijkt dat onder sommige omstandigheden de drie voorspellers worden gedeeld tussen verschillende programma ‘ s. Wat dit betekent is dat het aanvallende programma de voorspellende structuren kan vullen met zorgvuldig gekozen slechte data tijdens het uitvoeren. Wanneer een onbewust slachtoffer voert hun programma, hetzij op hetzelfde moment als de aanvaller of daarna, het slachtoffer zal eindigen met behulp van de voorspeller staat die werd ingevuld door de aanvaller en onbewust verrekening van een gadget. Deze tweede aanval is bijzonder zorgwekkend omdat het een slachtoffer programma kan worden aangevallen vanuit een ander programma. Een dergelijke bedreiging is vooral schadelijk voor cloudserviceproviders omdat zij dan niet kunnen garanderen dat hun klantgegevens worden beschermd.
de kwetsbaarheden in Spectre en Kernsmelting vormden een raadsel voor de computerindustrie omdat de kwetsbaarheid ontstaat in hardware. In sommige gevallen is het beste wat we kunnen doen voor bestaande systemen—die het grootste deel van de geïnstalleerde servers en PC ‘ s vormen—om te proberen software te herschrijven om de schade te beperken. Maar deze oplossingen zijn ad hoc, onvolledig, en vaak resulteren in een grote hit voor de prestaties van de computer. Tegelijkertijd, onderzoekers en CPU-ontwerpers zijn begonnen na te denken over het ontwerpen van toekomstige CPU ‘ s die speculatie te houden zonder afbreuk te doen aan de veiligheid.
een verdediging, genaamd kernel page-table isolation (kpti), is nu ingebouwd in Linux en andere besturingssystemen. Bedenk dat elke applicatie het geheugen en de opslagmiddelen van de computer ziet als een aaneengesloten stuk virtueel geheugen al zijn eigen. Maar fysiek worden deze activa verdeeld en gedeeld tussen verschillende programma ‘ s en processen. De paginatabel is in wezen de kaart van het besturingssysteem, die aangeeft welke delen van een virtueel geheugenadres overeenkomen met welke fysieke geheugenadressen. De kernel pagina tabel is verantwoordelijk voor het doen van dit voor de kernel van het besturingssysteem. KPTI en soortgelijke systemen verdedigen tegen Kernsmelting door geheime gegevens in het geheugen, zoals het besturingssysteem, ontoegankelijk te maken wanneer het programma van een gebruiker (en mogelijk het programma van een aanvaller) wordt uitgevoerd. Het doet dit door de verboden delen uit de paginatabel te verwijderen. Op die manier kan zelfs speculatief uitgevoerde code geen toegang krijgen tot de gegevens. Echter, deze oplossing betekent extra werk voor het besturingssysteem om deze pagina ‘ s in kaart te brengen wanneer het uitvoert en ze daarna unmap.
een andere klasse van verdediging geeft programmeurs een set van tools om gevaarlijke speculatie te beperken. Bijvoorbeeld, Google Retpoline patch herschrijft het soort takken die kwetsbaar zijn voor Spectre Variant 2, zodat het dwingt speculatie om een goedaardige, lege gadget te richten. Programmeurs kunnen ook een assembly-language instructie toevoegen die Spectre v1 beperkt, door speculatieve geheugenleads te beperken die voorwaardelijke branches volgen. Gemakshalve is deze instructie al aanwezig in de processorarchitectuur en wordt gebruikt om de juiste volgorde af te dwingen tussen geheugenbewerkingen die op verschillende processorkernen ontstaan.Als processor ontwerpers moesten Intel en AMD dieper gaan dan een gewone software patch. Hun fixes werken de microcode van de processor bij. Microcode is een laag van instructies die past tussen de assembler taal van de reguliere software en de processor ‘ s werkelijke Circuits. Microcode voegt flexibiliteit toe aan de set instructies die een processor kan uitvoeren. Het maakt het ook eenvoudiger om een CPU te ontwerpen, omdat bij het gebruik van microcode, complexe instructies worden vertaald naar meerdere eenvoudigere instructies die gemakkelijker uit te voeren zijn in een pijplijn.Intel en AMD hebben hun microcode aangepast om het gedrag van sommige assembler-taal instructies te veranderen op een manier die speculatie beperkt. Bijvoorbeeld, Intel ingenieurs toegevoegd opties die interfereren met een aantal van de aanvallen door het besturingssysteem toe te staan om de tak-predictor structuren te legen in bepaalde omstandigheden.
een andere klasse oplossingen probeert het vermogen van de aanvaller om de gegevens te verzenden via zijkanalen te verstoren. MIT ’s DAWG-technologie verdeelt bijvoorbeeld de processorcache veilig, zodat verschillende programma’ s geen van de bronnen delen. Het meest ambitieus, zijn er voorstellen voor nieuwe processor architecturen die structuren op de CPU die zijn gewijd aan speculatie en los van de processor cache en andere hardware zou introduceren. Op deze manier zijn alle operaties die speculatief worden uitgevoerd maar uiteindelijk niet worden gecommit nooit zichtbaar. Als het speculatieresultaat wordt bevestigd, worden de speculatieve gegevens naar de belangrijkste structuren van de verwerker gestuurd.
speculatieve kwetsbaarheden sluimerden al meer dan 20 jaar in processors, en ze bleven, voor zover bekend, onbenut. Hun ontdekking heeft aanzienlijk geschud Industrie en benadrukt hoe cybersecurity is niet alleen een probleem voor software systemen, maar ook voor hardware. Sinds de eerste ontdekking, ongeveer een dozijn varianten van Spectre en Meltdown zijn geopenbaard, en het is waarschijnlijk dat er meer. Spectre en Meltdown zijn immers bijwerkingen van kernontwerpprincipes waarop we hebben vertrouwd om de prestaties van de computer te verbeteren, waardoor het moeilijk is om dergelijke kwetsbaarheden in de huidige systeemontwerpen te elimineren. Het is waarschijnlijk dat nieuwe CPU-ontwerpen zullen evolueren om speculatie te behouden, terwijl het voorkomen van het type zijkanaallekkage dat deze aanvallen mogelijk maakt. Niettemin moeten toekomstige ontwerpers van computersystemen, inclusief degenen die processorchips ontwerpen, zich bewust zijn van de veiligheidsimplicaties van hun beslissingen, en niet langer alleen optimaliseren voor prestaties, grootte en kracht.
over de auteur
Nael Abu-Ghazaleh is voorzitter van het computer engineering programma aan de Universiteit van Californië, Riverside. Dmitry Evtyushkin is een assistent-professor in de informatica aan het College van William en Mary, in Williamsburg, Va. Dmitry Ponomarev is professor Informatica aan de State University Of New York in Binghamton.
om verder te onderzoeken
Paul Kocher en de andere onderzoekers die samen Spectre onthulden, legden het hier voor het eerst uit . Moritz Lipp legde Kernsmelting uit in deze talk op Usenix Security ’18. Voorafschaduw werd gedetailleerd op dezelfde conferentie.
een groep onderzoekers, waaronder een van de auteurs, is met een systematische evaluatie gekomen van Spectre-en Kernsmelting-aanvallen die extra potentiële aanvallen blootleggen . IBM ingenieurs deden iets dergelijks, en Google ingenieurs onlangs kwam tot de conclusie dat side-channel en speculatieve uitvoering aanvallen zijn hier om te blijven .