ett data warehouse är ett elektroniskt system som samlar in data från ett brett spektrum av källor inom ett företag och använder data för att stödja ledningsbeslut.
företag går alltmer mot molnbaserade datalager istället för traditionella lokala system. Molnbaserade datalager skiljer sig från traditionella lager på följande sätt:
- det finns inget behov av att köpa fysisk hårdvara.
- det är snabbare och billigare att konfigurera och skala molndatalager.
- molnbaserade datalagerarkitekturer kan vanligtvis utföra komplexa analytiska frågor mycket snabbare eftersom de använder massively parallel processing (MPP).
resten av den här artikeln täcker traditionell datalagerarkitektur och introducerar några arkitektoniska ideer och koncept som används av de mest populära molnbaserade datalagertjänsterna.
för mer information, se vår sida om data warehouse concepts i den här guiden.
traditionell Datalagerarkitektur
följande begrepp belyser några av de etablerade ideerna och designprinciperna som används för att bygga traditionella datalager.
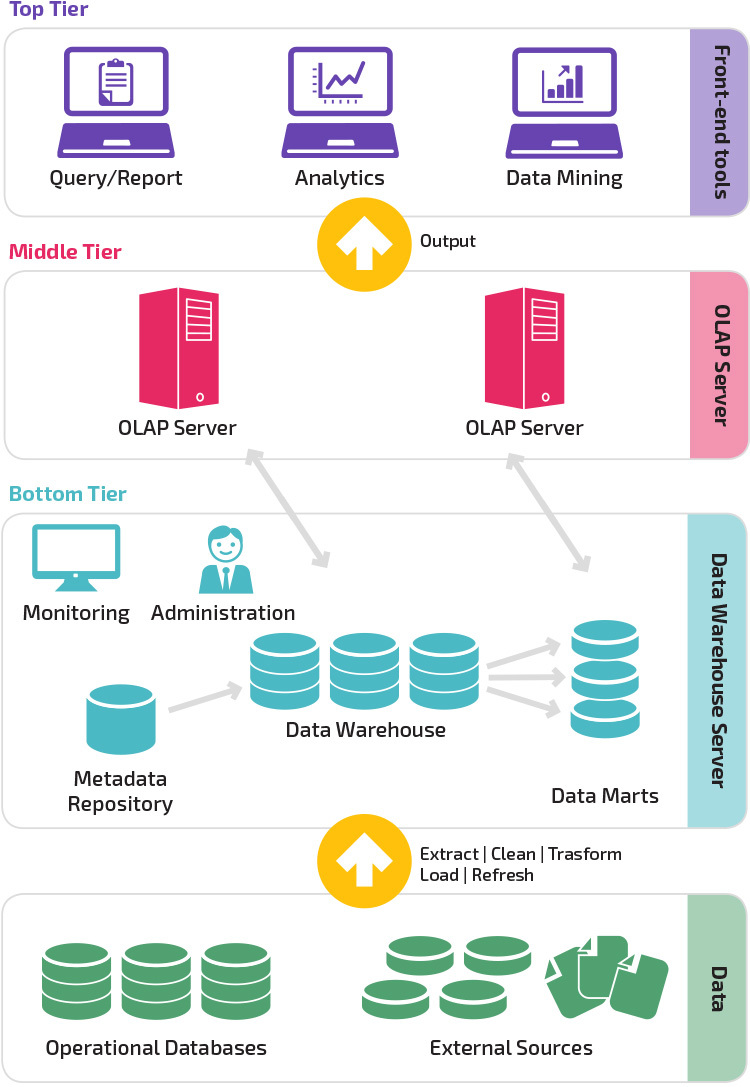
Trestegsarkitektur
traditionell datalagerarkitektur använder en trestegsstruktur som består av följande nivåer.
- nedre nivå: den här nivån innehåller databasservern som används för att extrahera data från många olika källor, till exempel från transaktionsdatabaser som används för front-end-applikationer.
- mellannivå: Den mellersta nivån rymmer en OLAP-server, som omvandlar data till en struktur som är bättre lämpad för analys och komplex fråga. OLAP-servern kan fungera på två sätt: antingen som ett utökat relationsdatabashanteringssystem som kartlägger operationerna på flerdimensionella data till standardrelationella operationer (relationell OLAP) eller använder en flerdimensionell OLAP-modell som direkt implementerar flerdimensionella data och operationer.
- toppnivå: toppnivån är klientlagret. Denna nivå innehåller de verktyg som används för dataanalys på hög nivå, frågande rapportering och datautvinning.
Kimball vs. Inmon
två pionjärer inom datalagring med namnet Bill Inmon och Ralph Kimball hade olika tillvägagångssätt för datalagerdesign.
Ralph Kimballs tillvägagångssätt betonade vikten av data marts, som är förråd av data som tillhör vissa branscher. Data warehouse är helt enkelt en kombination av olika data marts som underlättar rapportering och analys. Kimball data warehouse design använder en” bottom-up ” – strategi.
Bill Inmon betraktade datalagret som det centraliserade arkivet för alla företagsdata. I detta tillvägagångssätt skapar en organisation först en normaliserad datalagermodell. Dimensionella data marts skapas sedan baserat på lagermodellen. Detta är känt som en top-down-strategi för datalagring.
Datalagermodeller
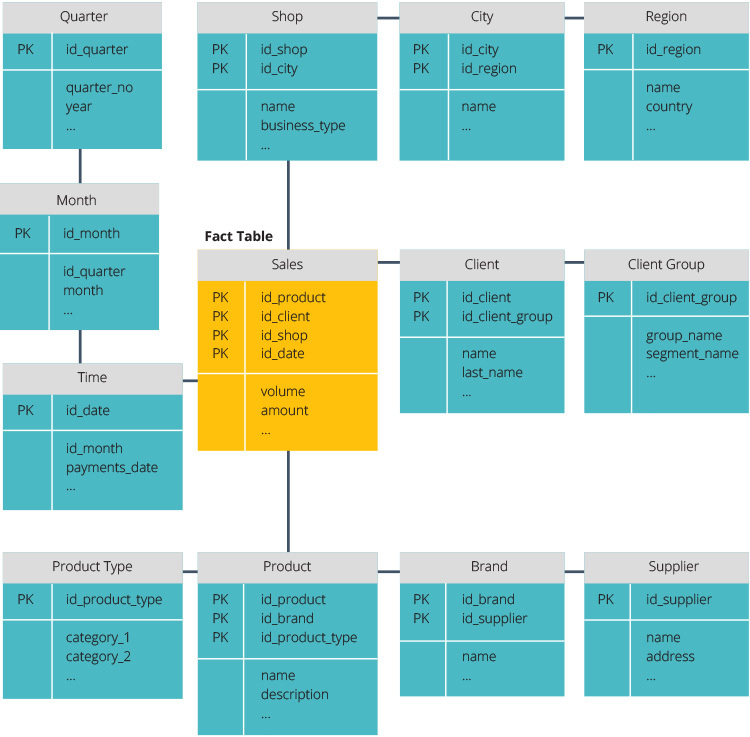
i en traditionell arkitektur finns tre vanliga datalagermodeller: virtuellt lager, data mart och enterprise data warehouse:
- ett virtuellt datalager är en uppsättning separata databaser, som kan frågas tillsammans, så att en användare effektivt kan komma åt alla data som om de lagrades i ett datalager.
- en data mart-modell används för affärslinjespecifik rapportering och analys. I denna datalagermodell aggregeras data från en rad källsystem som är relevanta för ett specifikt affärsområde, till exempel försäljning eller ekonomi.
- en enterprise data warehouse-modell föreskriver att data warehouse innehåller aggregerade data som spänner över hela organisationen. Denna modell ser datalagret som hjärtat i företagets informationssystem, med integrerad data från alla affärsenheter.
stjärnschema vs. snöflinga Schema
stjärnschemat och snöflinga schema är två sätt att strukturera ett datalager.
stjärnschemat har ett centraliserat datalager, lagrat i en faktatabell. Schemat delar upp faktatabellen i en serie denormaliserade dimensionstabeller. Faktatabellen innehåller aggregerade data som ska användas för rapporteringsändamål medan dimensionstabellen beskriver lagrade data.
Denormaliserade mönster är mindre komplexa eftersom data är grupperade. Faktatabellen använder endast en länk för att ansluta till varje dimensionstabell. Star schemas enklare design gör det mycket lättare att skriva komplexa frågor.
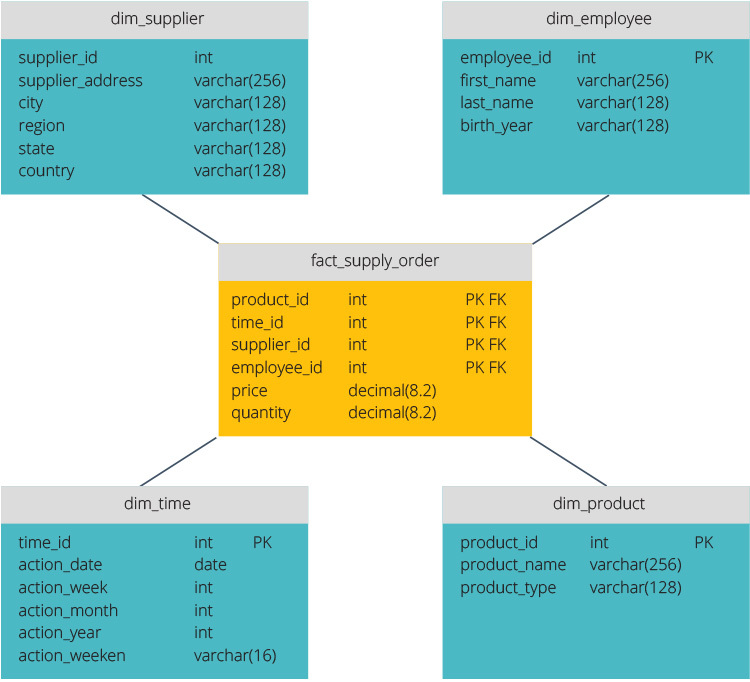
snöflinga schemat är annorlunda eftersom det normaliserar data. Normalisering innebär att effektivt organisera data så att alla databeroenden definieras och varje tabell innehåller minimala uppsägningar. Enstaka dimensionstabeller förgrenar sig således i separata dimensionstabeller.
snowflake-schemat använder mindre diskutrymme och bättre bevarar dataintegriteten. Den största nackdelen är komplexiteten i frågor som krävs för att komma åt data—varje fråga måste gräva djupt för att komma till relevanta data eftersom det finns flera kopplingar.
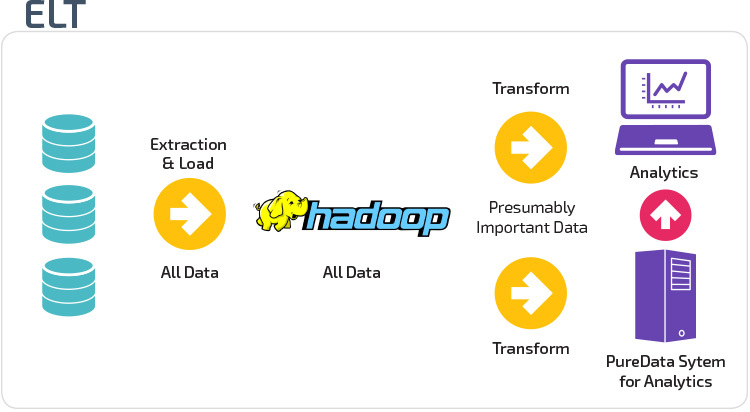
ETL vs. ELT
ETL och ELT är två olika metoder för att ladda data i ett lager.
extrahera, transformera, ladda (ETL) extraherar först data från en pool av datakällor, som vanligtvis är transaktionsdatabaser. Uppgifterna hålls i en tillfällig iscensättningsdatabas. Transformationsoperationer utförs sedan för att strukturera och konvertera data till en lämplig form för måldatalagersystemet. De strukturerade uppgifterna laddas sedan in i lagret, redo för analys.
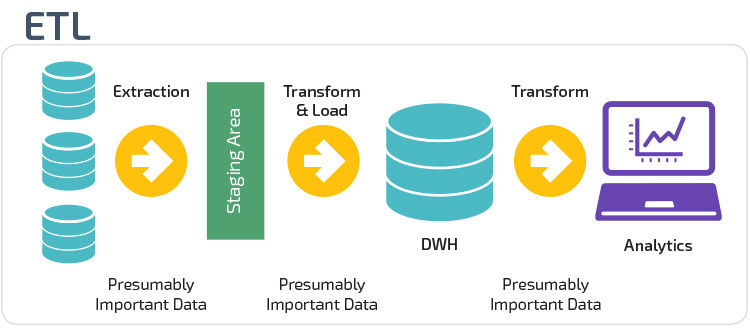
med Extract Load Transform (ELT) laddas data omedelbart efter att ha extraherats från källdatapoolerna. Det finns ingen iscensättningsdatabas, vilket innebär att data omedelbart laddas in i det enda, centraliserade förvaret. Data transformeras inuti data warehouse-systemet för användning med business intelligence-verktyg och analyser.
organisatorisk mognad
strukturen i en organisations datalager beror också på dess nuvarande situation och behov.
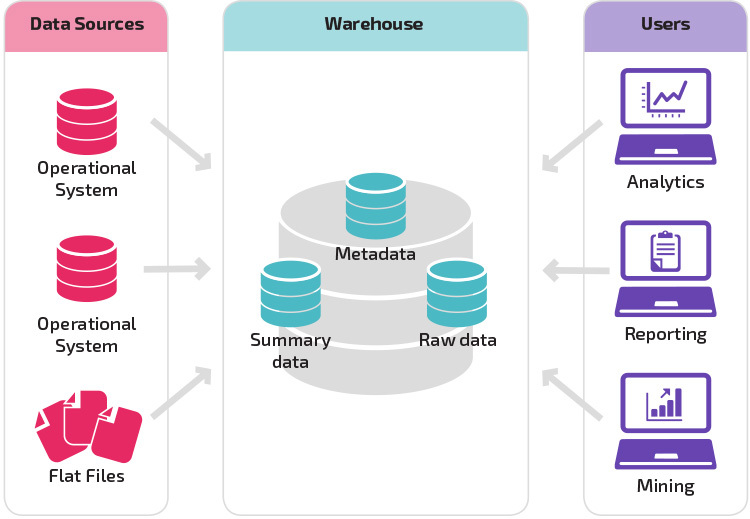
den grundläggande strukturen låter slutanvändare av lagret direkt få tillgång till sammanfattningsdata härledda från källsystem och utföra analys, rapportering och gruvdrift på dessa data. Denna struktur är användbar när datakällor härrör från samma typer av databassystem.
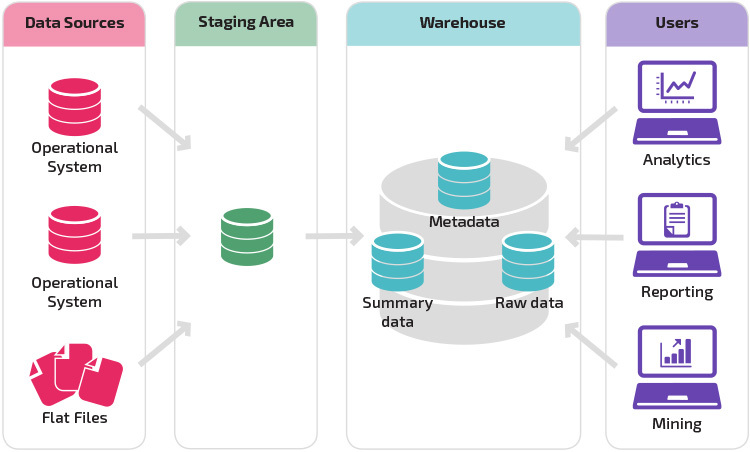
ett lager med ett iscensättningsområde är nästa logiska steg i en organisation med olika datakällor med många olika typer och format av data. Iscensättningsområdet konverterar data till ett sammanfattat strukturerat format som är lättare att fråga med analys-och rapporteringsverktyg.
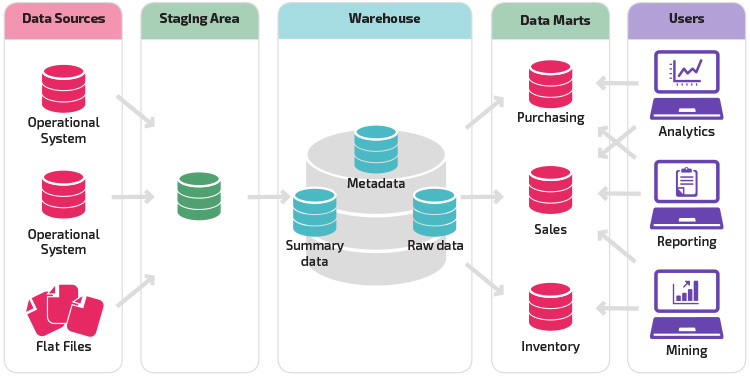
en variation på iscensättningsstrukturen är tillägget av data marts till datalagret. Data marts lagrar sammanfattade data för en viss bransch, vilket gör att data är lättillgängliga för specifika analysformer. Om du till exempel lägger till datamarter kan en finansanalytiker lättare utföra detaljerade frågor om försäljningsdata för att göra förutsägelser om kundbeteende. Data marts underlättar analysen genom att skräddarsy data specifikt för att möta slutanvändarens behov.
nya Datalagerarkitekturer
under de senaste åren flyttar datalager till molnet. De nya molnbaserade datalagren följer inte den traditionella arkitekturen; varje datalagerutbud har en unik arkitektur.
det här avsnittet sammanfattar arkitekturerna som används av två av de mest populära molnbaserade lagren: Amazon Redshift och Google BigQuery.
Amazon Redshift
Amazon Redshift är en molnbaserad representation av ett traditionellt datalager.
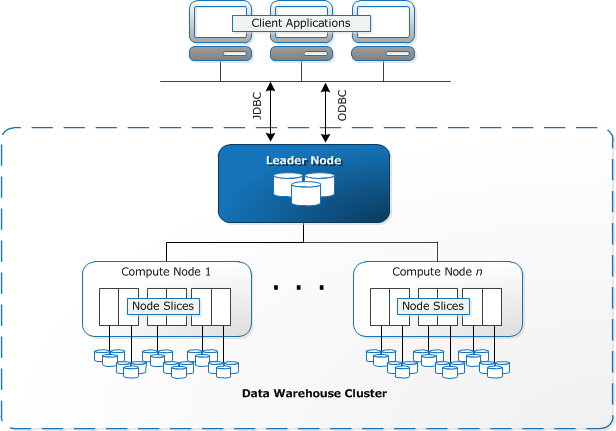
Redshift kräver att datorresurser ska tillhandahållas och ställas in i form av kluster, som innehåller en samling av en eller flera noder. Varje nod har sin egen CPU, lagring och RAM. En leader-nod sammanställer frågor och överför dem till compute nodes, som kör frågorna.
på varje nod lagras data i bitar, kallade skivor. Redshift använder en kolumnlagring, vilket innebär att varje datablock innehåller värden från en enda kolumn över ett antal rader, istället för en enda rad med värden från flera kolumner.
källa: AWS dokumentation
Redshift använder en MPP arkitektur, bryta upp stora datamängder i bitar som tilldelas skivor inom varje nod. Frågor fungerar snabbare eftersom beräkningsnoderna behandlar frågor i varje skiva samtidigt. Leader-noden aggregerar resultaten och returnerar dem till klientapplikationen.
klientapplikationer, som BI-och analysverktyg, kan direkt anslutas till Redshift med hjälp av PostgreSQL JDBC-och ODBC-drivrutiner med öppen källkod. Analytiker kan därmed utföra sina uppgifter direkt på Redshift-data.
Redshift kan bara ladda strukturerade data. Det är möjligt att ladda data till Redshift med förintegrerade system inklusive Amazon S3 och DynamoDB, genom att trycka data från någon lokal värd med SSH-anslutning eller genom att integrera andra datakällor med Redshift API.
Google BigQuery
Bigquerys arkitektur är serverlös, vilket innebär att Google dynamiskt hanterar fördelningen av maskinresurser. Alla resurshanteringsbeslut är därför dolda för användaren.
BigQuery låter kunder ladda data från Google Cloud Storage och andra läsbara datakällor. Alternativet är att strömma data, vilket gör det möjligt för utvecklare att lägga till data i datalagret i realtid, rad för rad, när det blir tillgängligt.
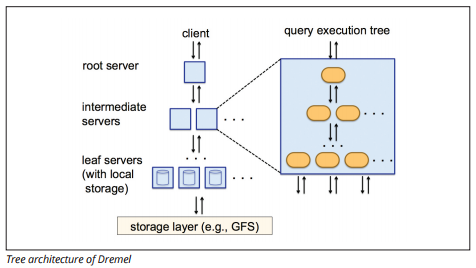
BigQuery använder en exekveringsmotor för frågor som heter Dremel, som kan skanna miljarder rader data på bara några sekunder. Dremel använder massivt parallell Fråga för att skanna data i det underliggande Colossus-filhanteringssystemet. Colossus distribuerar filer i bitar av 64 megabyte bland många datorresurser som heter noder, som är grupperade i kluster.
Dremel använder en kolumnär datastruktur, liknande Redshift. En trädarkitektur skickar frågor bland tusentals maskiner på några sekunder.
Bildkälla
enkla SQL-kommandon används för att utföra frågor på data.
Panoply
Panoply tillhandahåller end-to-end data management-as-a-service. Dess unika självoptimerande arkitektur använder maskininlärning och naturlig språkbehandling (NLP) för att modellera och effektivisera dataresan från källa till analys, vilket minskar tiden från data till värde så nära som möjligt till ingen.
Panoplys smarta datainfrastruktur innehåller följande funktioner:
- analys av frågor och data – identifiera den bästa konfigurationen för varje användningsfall, justera den över tiden, och bygga index, sortkeys, disketter, datatyper, Dammsugning, och partitionering.
- identifiera frågor som inte följer bästa praxis – till exempel de som innehåller kapslade slingor eller implicit gjutning – och skriver om dem till en motsvarande fråga som kräver en bråkdel av körtiden eller resurserna.
- optimera serverkonfigurationer över tid baserat på frågemönster och genom att lära sig vilken serverinstallation som fungerar bäst. Plattformen växlar servertyper sömlöst och mäter den resulterande prestandan.
utöver Molndatalager
molnbaserade datalager är ett stort steg framåt från traditionella arkitekturer. Användarna står dock fortfarande inför flera utmaningar när de ställer in dem:
- att ladda data till molndatalager är inte trivialt, och för storskaliga datapipelines kräver det att man konfigurerar, testar och underhåller en ETL-process. Denna del av processen görs vanligtvis med verktyg från tredje part.
- uppdateringar, upserts och raderingar kan vara knepiga och måste göras noggrant för att förhindra försämring av frågans prestanda.
- halvstrukturerad data är svår att hantera-måste normaliseras till ett relationsdatabasformat, vilket kräver automatisering för stora dataströmmar.
- kapslade strukturer stöds vanligtvis inte i molndatalager. Du måste platta kapslade tabeller i ett format som datalagret kan förstå.
- optimera ditt kluster—det finns olika alternativ för att ställa in ett Redshift-kluster för att köra dina arbetsbelastningar. Olika arbetsbelastningar, datamängder eller till och med olika typer av frågor kan kräva en annan inställning. För att vara optimal måste du ständigt se över och justera din inställning.
- Query optimization-användarfrågor kanske inte följer bästa praxis och tar därför mycket längre tid att köra. Du kan hitta er att arbeta med användare eller automatiserade klientapplikationer för att optimera frågor så att datalagret kan fungera som förväntat.
- säkerhetskopiering och återställning—medan datalagerleverantörerna erbjuder många alternativ för säkerhetskopiering av dina data, är de inte triviala att ställa in och kräver övervakning och noggrann uppmärksamhet.
Panoply är ett Smart datalager som lägger till ett lager av automatisering som tar hand om alla komplexa uppgifter ovan, vilket sparar värdefull tid och hjälper dig att komma från data till insikt på några minuter.
Läs mer om Panoplys smarta datalagerverktyg.
Läs mer om datalager
- Data Warehouse Concepts: Traditional vs. Moln
- databas vs. datalager
- Data Mart vs. datalager
- Amazon Redshift arkitektur