en djupgående titt på dessa farliga exploateringar av mikroprocessor sårbarheter och varför det kan finnas fler av dem där ute

vi är vana vid att tänka på datorprocessorer som ordnade maskiner som går från en enkel instruktion till nästa med fullständig regelbundenhet. Men sanningen är att de i årtionden nu har gjort sina uppgifter i ordning och bara gissat vad som ska komma nästa. De är väldigt bra på det, förstås. Så bra faktiskt att denna förmåga, kallad spekulativ utförande, har underbyggt mycket av förbättringen av datorkraften under de senaste 25 åren eller så. Men den 3 januari 2018 lärde världen att detta trick, som hade gjort så mycket för modern databehandling, nu var en av dess största sårbarheter.
under 2017 utarbetade forskare vid Cyberus Technology, Google Project Zero, Graz University of Technology, Rambus, University of Adelaide och University of Pennsylvania, liksom oberoende forskare som kryptograf Paul Kocher, separat attacker som utnyttjade spekulativt utförande. Vår egen grupp hade upptäckt den ursprungliga sårbarheten bakom en av dessa attacker tillbaka i 2016, men vi satte inte alla bitar ihop.
dessa typer av attacker, kallade Meltdown Och Spectre, var inga vanliga buggar. När det upptäcktes kunde Meltdown hacka alla Intel x86-mikroprocessorer och IBM-kraftprocessorer, liksom vissa ARM-baserade processorer. Spectre och dess många variationer lade till avancerade mikroenheter (AMD) processorer till den listan. Med andra ord var nästan hela datorvärlden sårbar.
och eftersom spekulativ exekvering i stor utsträckning är bakad i processorhårdvara, har det inte varit något enkelt jobb att fixa dessa sårbarheter. Att göra det utan att orsaka datorhastigheter att slipa i låg växel har gjort det ännu svårare. Faktiskt, ett år på, jobbet är långt ifrån över. Säkerhetsuppdateringar behövdes inte bara från processortillverkarna utan från de längre ner i försörjningskedjan, som Apple, Dell, Linux och Microsoft. De första datorerna som drivs av chips som är avsiktligt utformade för att vara resistenta mot även några av dessa sårbarheter kom först nyligen.
Spectre och Meltdown är resultatet av skillnaden mellan vilken programvara som ska göra och processorns mikroarkitektur—detaljerna om hur det faktiskt gör dessa saker. Dessa två klasser av hack har avslöjat ett sätt för information att läcka ut genom den skillnaden. Och det finns all anledning att tro att fler sätt kommer att avslöjas. Vi hjälpte till att hitta två, Branchscope och SpectreRSB , förra året.
om vi ska hålla takten i datorförbättringar utan att offra säkerheten måste vi förstå hur dessa hårdvaruproblem händer. Och det börjar med att förstå Spectre och Meltdown.
i moderna datorsystem sammanställs program som är skrivna på mänskligt begripliga språk som C++ i monteringsinstruktioner-grundläggande operationer som datorprocessorn kan utföra. För att påskynda utförandet använder moderna processorer ett tillvägagångssätt som kallas pipelining. Som en monteringslinje är rörledningen en serie steg, som var och en är ett steg som behövs för att slutföra en instruktion. Några typiska steg för en Intel x86-processor inkluderar de som tar in instruktionen från minnet och avkodar den för att förstå vad instruktionen betyder. Pipelining ger i princip parallellitet ner till nivån för instruktionsexekvering: när en instruktion görs med ett steg är nästa instruktion fri att använda den.
sedan 1990-talet har mikroprocessorer förlitat sig på två knep för att påskynda rörledningsprocessen: Out-of-order-utförande och spekulation. Om två instruktioner är oberoende av varandra—det vill säga utmatningen från en påverkar inte inmatningen från en annan—kan de ordnas om och deras resultat kommer fortfarande att vara korrekt. Det är till hjälp, eftersom det gör det möjligt för processorn att fortsätta arbeta om en instruktion stannar i rörledningen. Om en instruktion till exempel kräver data som finns i DRAM-huvudminnet snarare än i cacheminnet i själva CPU-enheten, kan det ta några hundra klockcykler för att få den informationen. Istället för att vänta kan processorn flytta en annan instruktion genom rörledningen.
det andra tricket är spekulation. För att förstå det, börja med det faktum att vissa instruktioner nödvändigtvis leder till en förändring i vilka instruktioner som kommer nästa. Tänk på ett program som innehåller Ett” if ” – uttalande: det kontrollerar ett tillstånd, och om villkoret är sant hoppar processorn till en annan plats i programmet. Detta är ett exempel på en villkorlig greninstruktion, men det finns andra instruktioner som också leder till förändringar i instruktionsflödet.
Tänk nu på vad som händer när en sådan filialinstruktion går in i en rörledning. Det är en situation som leder till en gåta. När instruktionen kommer i början av rörledningen vet vi inte resultatet förrän det har gått ganska djupt in i rörledningen. Och utan att veta detta resultat kan vi inte Hämta nästa instruktion. En enkel men naiv lösning är att förhindra att nya instruktioner kommer in i rörledningen tills greninstruktionen når en punkt där vi vet var nästa instruktion kommer ifrån. Många klockcykler slösas bort i denna process, eftersom rörledningar vanligtvis har 15 till 25 steg. Ännu värre, greninstruktioner kommer upp ganska ofta och står för uppemot 20 procent av alla instruktioner i många program.
för att undvika den höga prestandakostnaden för att stoppa rörledningen använder moderna processorer en arkitektonisk enhet som kallas en grenprediktor för att gissa var nästa instruktion, efter en gren, kommer ifrån. Syftet med denna prediktor är att spekulera om ett par viktiga punkter. Först kommer en villkorlig gren att tas, vilket får programmet att svänga till en annan del av programmet, eller kommer det att fortsätta på den befintliga vägen? Och för det andra, om filialen tas, vart ska programmet gå—vad blir nästa instruktion? Beväpnad med dessa förutsägelser kan processorns rörledning hållas full.
eftersom instruktionsexekveringen baseras på en förutsägelse utförs den ”spekulativt”: om förutsägelsen är korrekt förbättras prestandan avsevärt. Men om förutsägelsen visar sig vara felaktig måste processorn kunna ångra effekterna av spekulativt utförda instruktioner relativt snabbt.
utformningen av branch predictor har varit robust forskat i datorarkitektur samhället under många år. Moderna prediktorer använder exekveringshistoriken inom ett program som grund för deras resultat. Detta system uppnår noggrannhet över 95 procent på många olika typer av program, vilket leder till dramatiska prestandaförbättringar jämfört med en mikroprocessor som inte spekulerar. Misspeculation är dock möjlig. Och tyvärr är det felspekulation som Specter-attackerna utnyttjar.
en annan form av spekulation som har lett till problem är spekulation inom en enda instruktion i rörledningen. Det är ett ganska abströst koncept, så låt oss packa upp det. Antag att en instruktion kräver tillstånd att utföra. Till exempel kan en instruktion styra datorn för att skriva en bit data till den del av minnet som är reserverat för kärnan i operativsystemet. Du skulle inte vilja att det skulle hända, om det inte sanktionerades av operativsystemet själv, eller du riskerar att krascha datorn. Före upptäckten av Meltdown Och Spectre var den konventionella visdomen att det är okej att börja utföra instruktionen spekulativt redan innan processorn har nått punkten att kontrollera om instruktionen har tillstånd att göra sitt arbete eller inte.
i slutändan, om tillståndet inte är uppfyllt—i vårt exempel har operativsystemet inte sanktionerat detta försök att fikla med sitt minne—resultaten kastas ut och programmet indikerar ett fel. I allmänhet kan processorn spekulera kring någon del av en instruktion som kan få den att vänta, förutsatt att tillståndet så småningom löses och eventuella resultat från dåliga gissningar är effektivt ångrade. Det är den här typen av intra-instruktionsspekulation som ligger bakom alla varianter av Meltdown-felet, inklusive dess förmodligen farligare version, förskuggning.
insikten som möjliggör spekulationsattacker är detta: under felspekulation sker ingen förändring som ett program direkt kan observera. Med andra ord finns det inget program du kan skriva som helt enkelt skulle visa data som genereras under spekulativ körning. Men det faktum att spekulationer uppstår lämnar spår genom att påverka hur lång tid det tar instruktioner att utföra. Och tyvärr är det nu klart att vi kan upptäcka dessa tidssignaler och extrahera hemliga data från dem.
Vad är denna tidsinformation, och hur får en hacker tag i den? För att förstå det måste du förstå begreppet sidokanaler. En sidokanal är en oavsiktlig väg som läcker information från en enhet till en annan (vanligtvis är båda program), vanligtvis genom en delad resurs som en hårddisk eller ett minne.
som ett exempel på en sidokanalattack, överväga en enhet som är programmerad att lyssna på ljudet från en skrivare och sedan använder det ljudet för att härleda vad som skrivs ut. Ljudet är i detta fall en sidokanal.
i mikroprocessorer kan varje delad hårdvaruresurs i princip användas som en sidokanal som läcker information från ett offerprogram till ett angriparprogram. I en vanligt använd sidokanalattack är den delade resursen CPU: s cache. Cachen är ett relativt litet snabbåtkomstminne på processorchipet som används för att lagra de data som oftast behövs av ett program. När ETT program kommer åt minnet kontrollerar processorn först cachen; om data finns där (en cache-träff) återställs den snabbt. Om data inte finns i cachen (en miss) måste processorn vänta tills den hämtas från huvudminnet, vilket kan ta flera hundra klockcykler. Men när data kommer från huvudminnet läggs det till i cachen, vilket kan kräva att man slänger ut några andra data för att göra plats. Cachen är uppdelad i segment som kallas cacheuppsättningar, och varje plats i huvudminnet har en motsvarande uppsättning i cachen. Denna organisation gör det enkelt att kontrollera om något finns i cachen utan att behöva söka i hela saken.
Cache-baserade attacker hade undersökts omfattande redan innan Spectre och Meltdown dök upp på scenen. Även om angriparen inte direkt kan läsa offrets data-även när dessa data sitter i en delad resurs som cachen—kan angriparen få information om minnesadresserna som offret har åtkomst till. Dessa adresser kan bero på känsliga data, vilket gör att en smart angripare kan återställa denna hemliga data.
Hur gör angriparen detta? Det finns flera möjliga sätt. En variant, kallad Flush and Reload, börjar med att angriparen tar bort delade data från cachen med hjälp av ”flush” – instruktionen. Angriparen väntar sedan på att offret ska få tillgång till den informationen. Eftersom det inte längre finns i cachen måste Alla data som offret begär tas in från huvudminnet. Senare kommer angriparen åt de delade data medan tidpunkten för hur lång tid det tar. En cache-träff-vilket betyder att data är tillbaka i cachen—indikerar att offret har åtkomst till data. En cache-miss indikerar att data inte har nåtts. Så, helt enkelt genom att mäta hur lång tid det tog att komma åt data, kan angriparen bestämma vilka cacheuppsättningar som offret åtkom. Det tar lite algoritmisk magi, men denna kunskap om vilka cacheuppsättningar som nås och vilka inte kan leda till upptäckten av krypteringsnycklar och andra hemligheter.
Meltdown, Spectre och deras varianter följer alla samma mönster. Först utlöser de spekulationer för att utföra kod som önskas av angriparen. Denna kod läser hemliga data utan tillstånd. Sedan kommunicerar attackerna hemligheten med Flush and Reload eller en liknande sidokanal. Den sista delen är väl förstådd och liknande i alla attackvariationer. Således skiljer sig attackerna endast i den första komponenten, vilket är hur man utlöser och utnyttjar spekulation.
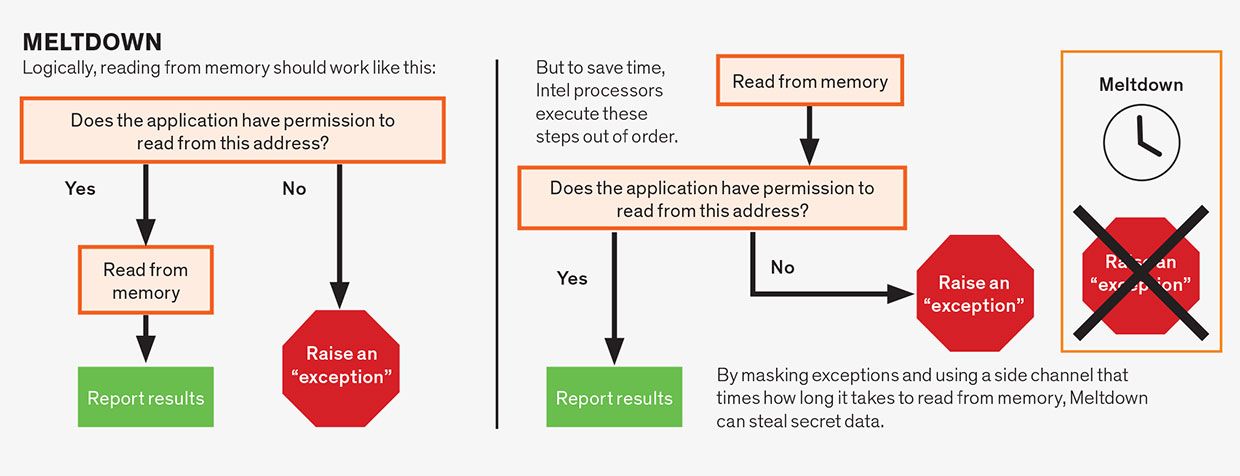
härdsmälta attacker
härdsmälta attacker utnyttja spekulationer inom en enda instruktion. Även om instruktioner för monteringsspråk vanligtvis är enkla, består en enda instruktion ofta av flera operationer som kan bero på varandra. Till exempel är minnesläsningsoperationer ofta beroende av instruktionen som uppfyller behörigheterna som är associerade med minnesadressen som läses. En applikation har vanligtvis behörighet att bara läsa från minnet som har tilldelats det, inte från minnet som tilldelats till exempelvis operativsystemet eller någon annan användares program. Logiskt sett bör vi kontrollera behörigheterna innan vi låter läsningen fortsätta, vilket är vad vissa mikroprocessorer gör, särskilt de från AMD. Men förutsatt att slutresultatet är korrekt antog CPU-designers att de var fria att spekulativt utföra dessa operationer i ordning. Därför läser Intel-mikroprocessorer minnesplatsen innan de kontrollerar behörigheter, men bara” begår ” instruktionen—vilket gör resultaten synliga för programmet—när behörigheterna är uppfyllda. Men eftersom de hemliga uppgifterna har hämtats spekulativt kan de upptäckas med hjälp av en sidokanal, vilket gör Intel-processorer sårbara för denna attack.
Foreshadow-attacken är en variant av Meltdown-sårbarheten. Denna attack påverkar Intel-mikroprocessorer på grund av en svaghet som Intel kallar L1-Terminalfel (L1TF). Medan den ursprungliga Meltdown-attacken förlitade sig på en försening i kontrollbehörigheterna, förlitar sig Foreshadow på spekulationer som inträffar under ett steg i rörledningen som kallas adressöversättning.
programvara ser datorns minne och lagringstillgångar som en enda sammanhängande sträcka av virtuellt minne alla sina egna. Men fysiskt delas dessa tillgångar upp och delas mellan olika program och processer. Adressöversättning förvandlar en virtuell minnesadress till en fysisk minnesadress.
specialiserade kretsar på mikroprocessorn hjälper till med den virtuella till fysiska minnesadressöversättningen, men det kan vara långsamt, vilket kräver flera minnesuppslag. För att påskynda saker tillåter Intel-mikroprocessorer spekulation under översättningsprocessen, vilket gör det möjligt för ett program att spekulativt läsa innehållet i en del av cachen som heter L1 oavsett vem som äger den data. Angriparen kan göra detta och sedan avslöja data med hjälp av sidokanalsmetoden som vi redan beskrivit.
på vissa sätt är förskuggning farligare än smältning, på andra sätt är det mindre. Till skillnad från Meltdown kan Foreshadow bara läsa innehållet i L1-cachen på grund av detaljerna i Intels implementering av processorarkitekturen. Foreshadow kan dock läsa något innehåll i L1—inte bara data som kan adresseras av programmet.
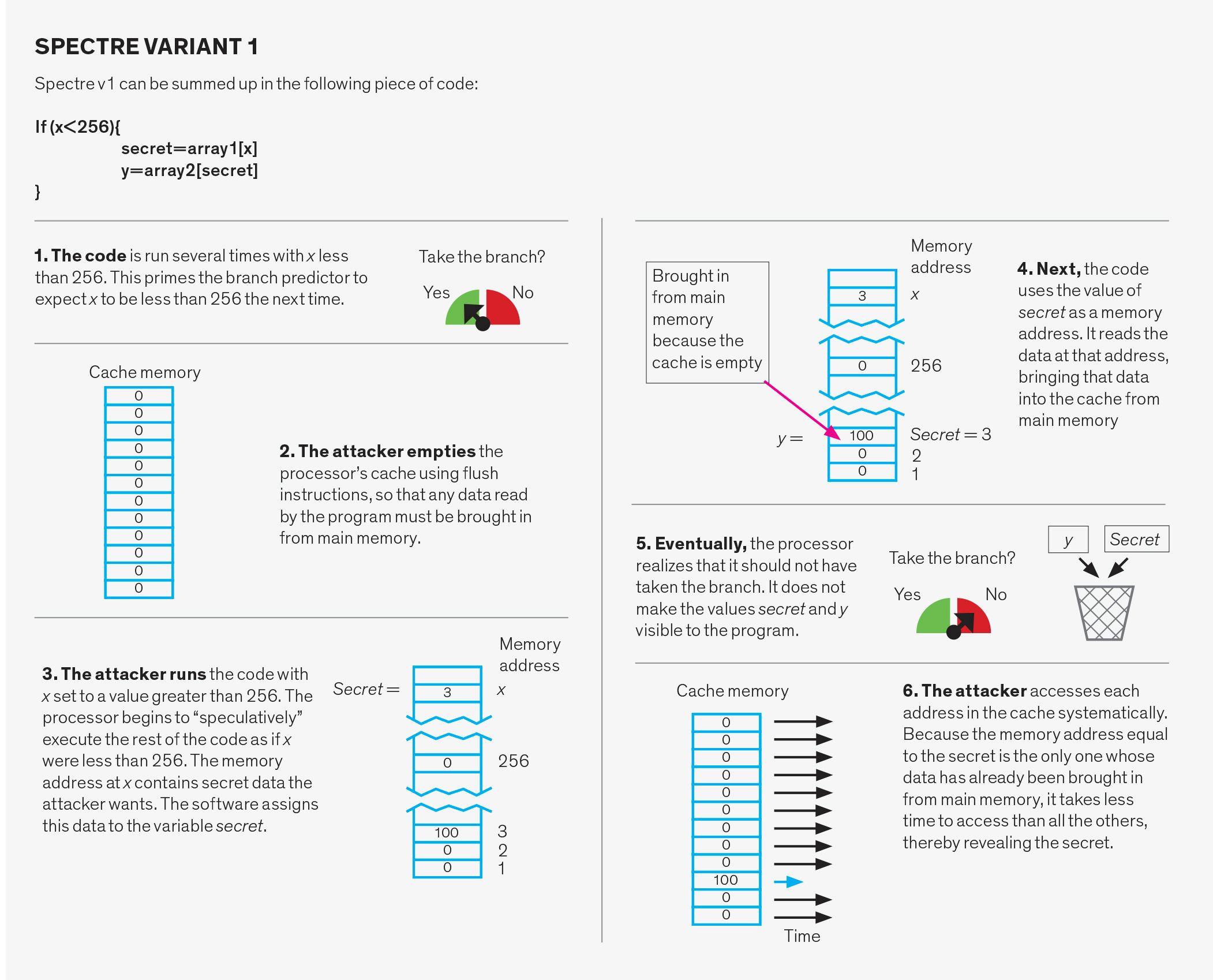
Spectre attacker
Spectre attacker manipulera gren-förutsägelse systemet. Detta system har tre delar: grenriktningsprognosen, grenmålsprognosen och returstackbufferten.
grenriktningsprediktorn förutsäger om en villkorlig gren, som en som används för att implementera ett ”if” – uttalande i ett programmeringsspråk, kommer att tas eller inte tas. För att göra detta spårar det tidigare beteendet hos liknande grenar. Det kan till exempel innebära att om en gren tas två gånger i rad, kommer framtida förutsägelser att säga att den ska tas.
grenmålsprognosen förutsäger målminneadressen för vad som kallas indirekta grenar. I en villkorlig gren stavas adressen till nästa instruktion, men för en indirekt gren måste den adressen beräknas först. Systemet som förutsäger dessa resultat är en cache-struktur som kallas grenmålbufferten. I huvudsak håller den reda på det sista beräknade målet för de indirekta grenarna och använder dessa för att förutsäga var nästa indirekta gren ska leda till.
returstackbufferten används för att förutsäga målet för en ”retur” – instruktion. När en subrutin ”kallas” under ett program, gör returinstruktionen att programmet återupptar arbetet vid den punkt från vilken subrutinen kallades. Att försöka förutsäga rätt punkt att återvända till baserat endast på tidigare returadresser fungerar inte, eftersom samma funktion kan anropas från många olika platser i koden. Istället använder systemet returstackbufferten, ett minne på processorn, som håller returadresserna för funktioner som de kallas. Den använder sedan dessa adresser när en retur påträffas i subrutinens kod.
var och en av dessa tre strukturer kan utnyttjas på två olika sätt. För det första kan prediktorn medvetet misstas. I det här fallet utför angriparen till synes oskyldig kod som är utformad för att befuddle systemet. Senare utför angriparen medvetet en gren som kommer att misspekulera, vilket gör att programmet hoppar till en kod som valts av angriparen, kallad en gadget. Gadgeten sätter sedan om att stjäla data.
ett andra sätt av Spectre attack kallas direktinjektion. Det visar sig att under vissa förhållanden delas de tre prediktorerna mellan olika program. Vad detta betyder är att det attackerande programmet kan fylla prediktorstrukturerna med noggrant utvalda dåliga data när det körs. När en ovetande offer utför sitt program antingen samtidigt som angriparen eller efteråt, offret kommer att avveckla med hjälp av prediktor tillstånd som fylldes i av angriparen och omedvetet iväg en gadget. Denna andra attack är särskilt oroande eftersom det gör att ett offerprogram kan attackeras från ett annat program. Ett sådant hot är särskilt skadligt för molntjänstleverantörer eftersom de då inte kan garantera att deras klientdata skyddas.
de Spectre Och Meltdown sårbarheter presenterade en gåta för datorindustrin eftersom sårbarheten har sitt ursprung i hårdvara. I vissa fall är det bästa vi kan göra för befintliga system—som utgör huvuddelen av installerade servrar och datorer—att försöka skriva om programvara för att försöka begränsa skadan. Men dessa lösningar är ad hoc, ofullständiga och resulterar ofta i en stor hit för datorns prestanda. Samtidigt har forskare och CPU-designers börjat tänka på hur man utformar framtida processorer som håller spekulationer utan att äventyra säkerheten.
ett försvar, kallat kernel page-table isolation (KPTI), är nu inbyggt i Linux och andra operativsystem. Kom ihåg att varje applikation ser datorns minne och lagringstillgångar som en enda sammanhängande sträcka av virtuellt minne helt och hållet. Men fysiskt delas dessa tillgångar upp och delas mellan olika program och processer. Sidtabellen är i huvudsak operativsystemets karta och berättar vilka delar av en virtuell minnesadress som motsvarar vilka fysiska minnesadresser. Kernel page-tabellen är ansvarig för att göra detta för kärnan i operativsystemet. KPTI och liknande system försvarar sig mot smältning genom att göra hemliga data i minnet, till exempel operativsystemet, otillgängliga när en användares program (och eventuellt en angripares program) körs. Det gör detta genom att ta bort de förbjudna delarna från sidtabellen. På så sätt kan inte ens spekulativt exekverad kod komma åt data. Denna lösning innebär dock extra arbete för operativsystemet för att kartlägga dessa sidor när det körs och avmappa dem efteråt.
en annan klass av försvar ger programmerare en uppsättning verktyg för att begränsa farlig spekulation. Till exempel skriver Googles Retpoline patch om den typ av grenar som är sårbara för Spectre Variant 2, så att det tvingar spekulationer att rikta sig mot en godartad, Tom gadget. Programmerare kan också lägga till en monteringsspråksinstruktion som begränsar Spectre v1, genom att begränsa spekulativa minnesläsningar som följer villkorliga grenar. Bekvämt är denna instruktion redan närvarande i processorarkitekturen och används för att genomdriva rätt ordning mellan minnesoperationer med ursprung i olika processorkärnor.
som processordesigners måste Intel och AMD gå djupare än en vanlig programvarupatch. Deras korrigeringar uppdaterar processorns mikrokod. Mikrokod är ett lager av instruktioner som passar mellan monteringsspråket för vanlig programvara och processorns faktiska kretsar. Mikrokod ger flexibilitet till uppsättningen instruktioner som en processor kan utföra. Det gör det också enklare att designa en CPU eftersom när du använder mikrokod översätts komplexa instruktioner till flera enklare instruktioner som är enklare att utföra i en pipeline.
i grund och botten justerade Intel och AMD sin mikrokod för att ändra beteendet hos vissa monteringsinstruktioner på sätt som begränsar spekulationen. Till exempel har Intel-ingenjörer lagt till alternativ som stör några av attackerna genom att låta operativsystemet tömma grenpredictorstrukturerna under vissa omständigheter.
en annan klass av lösningar försöker störa angriparens förmåga att överföra data ut med hjälp av sidokanaler. Till exempel delar MITS DAWG-teknik säkert upp processorns cache så att olika program inte delar någon av dess resurser. Mest ambitiöst finns det förslag till nya processorarkitekturer som skulle införa strukturer på CPU som är dedikerade till spekulation och separeras från processorns cache och annan hårdvara. På så sätt är alla operationer som utförs spekulativt men som inte så småningom begås aldrig synliga. Om spekulationsresultatet bekräftas skickas spekulativa data till processorns huvudstrukturer.
Spekulationssårbarheter har legat vilande i processorer i över 20 år, och de förblev, så vitt någon vet, outnyttjade. Deras upptäckt har väsentligt skakat industrin och belyst hur cybersäkerhet inte bara är ett problem för mjukvarusystem utan också för hårdvara. Sedan den första upptäckten har cirka ett dussin varianter av Spectre och Meltdown avslöjats, och det är troligt att det finns fler. Spectre och Meltdown är trots allt biverkningar av kärndesignprinciper som vi har förlitat oss på för att förbättra datorns prestanda, vilket gör det svårt att eliminera sådana sårbarheter i nuvarande systemdesigner. Det är troligt att nya CPU-mönster kommer att utvecklas för att behålla spekulationer, samtidigt som man förhindrar den typ av sidokanalsläckage som möjliggör dessa attacker. Ändå måste framtida datorsystemdesigners, inklusive de som utformar processorchips, vara medvetna om säkerhetsimplikationerna av sina beslut och inte längre optimera endast för prestanda, storlek och kraft.
om författaren
Nael Abu-Ghazaleh är ordförande för dataingenjörsprogrammet vid University of California, Riverside. Dmitry Evtyushkin är biträdande professor i datavetenskap vid College of William and Mary, i Williamsburg, Va. Dmitry Ponomarev är en datavetenskapsprofessor vid State University of New York i Binghamton.
för att sondra vidare
Paul Kocher och de andra forskarna som kollektivt avslöjade Spectre först förklarade det här . Moritz Lipp förklarade härdsmälta i detta föredrag på Usenix Security ’ 18. Foreshadow var detaljerad vid samma konferens.
en grupp forskare inklusive en av författarna har kommit fram till en systematisk utvärdering av Spectre Och Meltdown attacker som avslöjar ytterligare potentiella attacker . IBM-ingenjörer gjorde något liknande, och Google-ingenjörer kom nyligen till slutsatsen att sidokanalsattacker och spekulativa exekveringsattacker är här för att stanna .