Soit X une variable aléatoire à valeur réelle, et soit 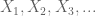
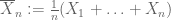
Loi faible des grands nombres. Supposons que le premier moment
de X soit fini. Alors
converge en probabilité vers
, donc
pour chaque
.
Loi forte des grands nombres. Supposons que le premier moment
.
( Si l’on renforce l’hypothèse du premier moment à celle de la finitude du second moment 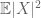
La loi faible est facile à prouver, mais la loi forte (ce qui implique bien sûr la loi faible, par le théorème d’Egoroff) est plus subtile, et en fait la preuve de cette loi (en supposant juste la finitude du premier moment) n’apparaît généralement que dans les textes avancés. J’ai donc pensé présenter ici une preuve des deux lois, qui procède par les techniques standard de la méthode du moment et de la troncature. L’accent sera mis dans cette exposition sur la motivation et les méthodes plutôt que sur la brièveté et la force des résultats; il existe des preuves de la loi forte dans la littérature qui ont été compressées jusqu’à la taille d’une page ou moins, mais ce n’est pas mon objectif ici.
La méthode des moments cherche à contrôler les probabilités de queue d’une variable aléatoire (c’est-à-dire la probabilité qu’elle fluctue loin de sa moyenne) au moyen de moments, et en particulier le zéro, le premier ou le deuxième moment. La raison pour laquelle cette méthode est si efficace est que les premiers moments peuvent souvent être calculés assez précisément. La méthode du premier moment utilise généralement l’inégalité de Markov
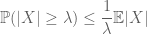
( qui suit en prenant des attentes de l’inégalité ponctuelle 

( notez que (2) est juste (1) appliqué à la variable aléatoire ).
De manière générale, pour calculer le premier moment, on utilise généralement la linéarité de l’attente

alors que pour calculer le deuxième moment, il faut également comprendre les covariances (qui sont particulièrement simples si l’on suppose une indépendance par paire), grâce à des identités telles que
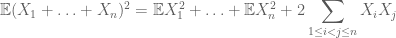
ou la variante normalisée
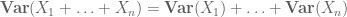

Des moments plus élevés peuvent en principe donner des informations plus précises, mais nécessitent souvent des hypothèses plus fortes sur les objets étudiés, telles que l’indépendance conjointe.
Voici une application de base de la méthode du premier moment:
Lemme de Borel-Cantelli. Soit
une séquence d’événements telle que
est finie. Alors presque sûrement, seuls de nombreux événements
sont vrais.
Épreuve. Soit 


Letting 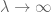

Pour revenir à la loi des grands nombres, la méthode du premier moment donne la limite de queue suivante:
Lemme 1. (Limite de la queue du premier moment) Si
est fini, alors
.
Épreuve. Par l’inégalité du triangle, est
Le lemme 1 n’est pas assez fort en soi pour prouver la loi des grands nombres sous forme faible ou forte – en particulier, il ne montre aucune amélioration lorsque n devient grand – mais il sera utile de gérer l’un des termes d’erreur dans ces preuves.
Nous pouvons obtenir des bornes plus fortes que le Lemme 1 – en particulier, des bornes qui s’améliorent avec n – au détriment d’hypothèses plus fortes sur X.
Lemme 2. Si
.
Épreuve. Un calcul standard, exploitant (3) et l’indépendance par paire du 



Dans la direction opposée, il existe la méthode du moment zéro, plus communément appelée limite d’union

ou de manière équivalente (pour expliquer la terminologie « moment zéro »)

pour toutes les variables aléatoires non négatives 
{\ Je ne peux pas le faire, mais je ne peux pas le faire. (4)
De même que la limite du deuxième moment (Lemme 2) n’est utile que lorsque l’on a un bon contrôle sur le deuxième moment (ou variance) de X, l’estimation de la queue de moment zéro (3) n’est utile que lorsque nous avons un bon contrôle sur le moment zéro 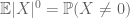
La queue de second moment liée (Lemme 2) donne déjà la loi faible des grands nombres dans le cas où X a un second moment fini (ou de manière équivalente, une variance finie). En général, si tout ce que l’on sait sur X est qu’il a un premier moment fini, alors nous ne pouvons pas conclure que X a un deuxième moment fini. Cependant, nous pouvons effectuer une troncature
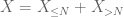
de X à tout seuil souhaité N, où 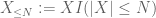

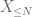
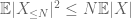
et donc aussi nous avons une variance finie
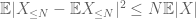
Le deuxième terme 
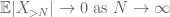
Par l’inégalité du triangle, nous concluons que le premier terme
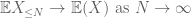
Ce sont tous les outils dont nous avons besoin pour prouver la loi faible des grands nombres:
Preuve de la loi faible. Soit 

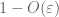
À partir de (7), (8), on peut trouver un seuil N(dépendant de 
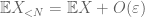

Dès le premier moment lié à la queue (Lemme 1), nous savons que 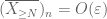
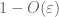
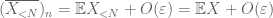
— La loi forte –
La loi forte peut être prouvée en poussant un peu plus loin les méthodes ci-dessus et en utilisant quelques astuces supplémentaires.
La première astuce consiste à observer que pour prouver la loi forte, il suffit de le faire pour des variables aléatoires non négatives 

Une fois que X est non négatif, nous voyons que les moyennes empiriques

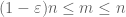
En raison de cette quasimonotonicité, nous pouvons sparsifier l’ensemble de n pour lequel nous devons prouver la loi forte. Plus précisément, il suffit de montrer
Loi forte des grands nombres, version réduite. Soit
une variable aléatoire non négative avec
, et soit
une séquence d’entiers lacunaires en ce sens que
pour certains
et tous suffisamment grands j. Alors
converge presque sûrement vers
En effet, si nous pouvions prouver la version réduite, alors en appliquant cette version à la séquence lacunaire 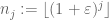


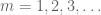
Maintenant que nous avons sparsifié la séquence, il devient économique d’appliquer le lemme de Borel-Cantelli. En effet, par de nombreuses applications de ce lemme on voit qu’il suffit de montrer que

pour X non négatif de premier moment fini, toute séquence lacunaire 
À ce stade, nous revenons en arrière et appliquons les méthodes qui ont déjà fonctionné pour donner la loi faible. À savoir, pour estimer chacune des probabilités de queue 
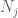
Nous devrions au moins choisir 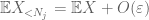


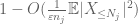

Maintenant, nous examinons la contribution de 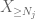
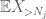
Mais il y a une dernière carte à jouer, qui est l’estimation de la queue de la méthode du moment zéro (4). Comme mentionné précédemment, cette borne est moche en général – mais est très bonne lorsque X est principalement nul, ce qui est précisément la situation avec 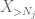


En mettant tout cela ensemble, nous voyons que

En résumant cela en j, nous voyons que nous aurons terminé dès que nous aurons compris comment choisir
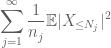
et
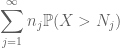
sont tous deux finis. (Comme d’habitude, nous avons un compromis: rendre le
Sur la base de la discussion précédente, il est naturel d’essayer de définir 

et
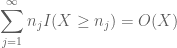
( où la constante implicite dépend ici de la séquence 
Remarque 1. La preuve ci-dessus montre en fait que la loi forte des grands nombres tient même si l’on ne suppose que l’indépendance par paires du 

Remarque 2. Il est essentiel que les variables aléatoires 

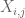
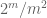
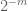



Remarque 3. Du point de vue de la théorie de l’interpolation, on peut considérer l’argument ci-dessus comme un argument d’interpolation, établissant une estimation 


Remarque 4. En considérant la séquence