zij X een reële willekeurige variabele, en zij 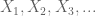
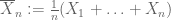
zwakke wet van grote aantallen. Stel dat het eerste moment
van X eindig is. Dan convergeert
in waarschijnlijkheid naar
, dus
voor elke
.
sterke wet van grote aantallen. Stel dat het eerste moment
.
(als men de aanname van het eerste moment versterkt tot die van eindigheid van het tweede moment 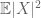
de zwakke wet is gemakkelijk te bewijzen, maar de sterke wet (die natuurlijk de zwakke wet impliceert, door de stelling van Egoroff) is subtieler, en in feite is het bewijs van deze wet (uitgaande van de juistheid van het eerste moment) meestal alleen in geavanceerde graduate teksten. Dus ik dacht dat ik hier een bewijs zou presenteren van beide wetten, die voortkomt uit de standaard technieken van het moment methode en afkappen. De nadruk in deze expositie zal liggen op motivatie en methoden in plaats van beknoptheid en kracht van de resultaten; er bestaan bewijzen van de sterke wet in de literatuur die zijn gecomprimeerd tot de grootte van een pagina of minder, maar dit is niet mijn doel hier.
– de momentmethode –
de momentmethode probeert de staartkansen van een willekeurige variabele (d.w.z. de kans dat deze ver van het gemiddelde fluctueert) te controleren door middel van momenten, en in het bijzonder het Nulde, eerste of tweede moment. De reden dat deze methode zo effectief is, is omdat de eerste paar momenten vaak vrij nauwkeurig kunnen worden berekend. Het eerste moment methode wordt meestal maakt gebruik van Markov ‘ s ongelijkheid
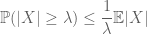
(gevolgd door het nemen van de verwachtingen van de puntsgewijs ongelijkheid 

(merk op dat (2) is het net (1) toegepast op de random variabele 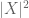

in het Algemeen, voor het berekenen van het eerste moment dat men meestal hanteert lineariteit van de verwachting

overwegende dat voor het berekenen van het tweede moment dat men moet ook begrijpen covariances (die bijzonder eenvoudig als men veronderstelt paarsgewijze onafhankelijkheid), dankzij identiteiten zoals
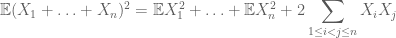
of de genormaliseerde variant
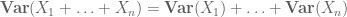

hogere momenten kunnen in principe nauwkeuriger informatie geven, maar vereisen vaak sterkere veronderstellingen over de bestudeerde objecten, zoals gezamenlijke onafhankelijkheid.
hier is een basistoepassing van de eerste-momentmethode:
Borel-Cantelli lemma. Laat
een opeenvolging van gebeurtenissen zijn, zodat
eindig is. Dan zijn vrijwel zeker slechts eindig veel van de gebeurtenissen
waar.
Proof. Laat 


Letting 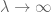

terugkerend naar de wet van de grote getallen, geeft de eerste-moment-methode de volgende staartbinding:
Lemma 1. (Eerste moment staart gebonden) als
eindig is, dan
.
Proof. Door de driehoek ongelijkheid, 

Lemma 1 is op zichzelf niet sterk genoeg om de wet van grote getallen in zwakke of sterke vorm te bewijzen – met name vertoont het geen verbetering naarmate n groot wordt – maar het zal nuttig zijn om een van de fouttermen in deze bewijzen te hanteren.
we kunnen sterkere grenzen krijgen dan Lemma 1 – in het bijzonder, grenzen die verbeteren met n – ten koste van sterkere veronderstellingen op X.
Lemma 2. (Tweede moment staart gebonden) als
.
Proof. Een standaard berekening, het benutten van (3) en de paarsgewijze onafhankelijkheid van de 



In de tegenovergestelde richting, er is de nulde moment methode, beter bekend als de unie gebonden

oftewel (voor uitleg van de terminologie “nulde moment”)

voor elke niet-negatieve random variabelen 
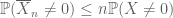
net zoals het tweede moment gebonden (Lemma 2) alleen nuttig is als men een goede controle heeft op het tweede moment (of variantie) van X, is de nulth moment tail estimate(3) alleen nuttig als we een goede controle hebben op het nulth moment 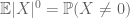
– afkappen –
het tweede moment staart gebonden (Lemma 2) geeft al de zwakke wet van grote getallen in het geval X heeft eindig tweede moment (of gelijkwaardig, eindige variantie). In het algemeen, als alles wat men weet over X is dat het eindig eerste moment heeft, dan kunnen we niet concluderen dat X eindig tweede moment heeft. We kunnen echter een afkapping uitvoeren
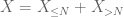
van X op elke gewenste drempel N, waarbij 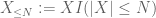

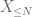
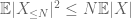
en dus hebben we ook eindige variantie
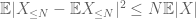
de tweede term 
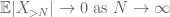
door de driehoek ongelijkheid, concluderen we dat de eerste term
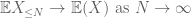
dit zijn alle instrumenten die we nodig hebben om de zwakke wet van grote getallen te bewijzen:
bewijs van zwakke wet. Let 

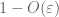
van (7), (8), kunnen we een drempel N vinden (afhankelijk van 
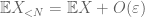

vanaf het eerste moment staart gebonden (Lemma 1), weten we dat 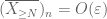
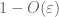
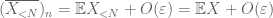
— de sterke wet –
de sterke wet kan worden bewezen door de bovenstaande methoden een beetje verder te duwen en nog een paar trucs te gebruiken.
de eerste truc is om vast te stellen dat om de sterke wet te bewijzen, het volstaat om dit te doen voor niet-negatieve willekeurige variabelen 

zodra X niet-negatief is, zien we dat de empirische gemiddelden

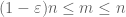
vanwege deze quasimonotoniciteit kunnen we de verzameling n sparsifyen waarvoor we de sterke wet moeten bewijzen. Meer precies, het volstaat om
sterke wet van grote getallen, gereduceerde versie te tonen. Laat
een niet-negatieve willekeurige variabele zijn met
, en laat
een reeks gehele getallen zijn die lacunair is in de zin dat
voor sommige
en alle voldoende groot j. dan
convergeert vrijwel zeker naar
inderdaad, als we de gereduceerde versie konden bewijzen, dan bij het toepassen van die versie op de lacunaire reeks 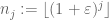


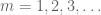
nu we de sequentie hebben afgezwakt, wordt het economisch om het Borel-Cantelli lemma toe te passen. Inderdaad, door de vele toepassingen van dat lemma zien we dat het voldoende is om aan te tonen dat

voor niet-negatieve X van eindig eerste moment, een lacunary sequentie 
op dit punt gaan we terug en passen we de methoden toe die al werkten om de zwakke wet te geven. Namelijk, om elk van de staartwaarschijnlijkheden 
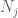
we moeten ten minste 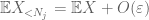


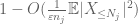

nu bekijken we de bijdrage van 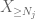
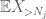
maar er is nog een laatste kaart om te spelen, namelijk de nulth moment method tail estimate (4). Zoals eerder vermeld, is deze binding in het algemeen belabberd – maar is zeer goed wanneer X meestal nul is, wat precies de situatie is met 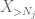


bij elkaar opgeteld zien we dat

hierover in j, zien we dat we zo snel als we erachter te komen hoe om te kiezen van
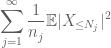
en
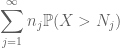
zijn beide eindig is. (Zoals gewoonlijk hebben we een afweging: het groter maken van
gebaseerd op de discussie eerder, is het normaal om te proberen 

en
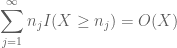
(waar de impliciete constante hangt wel af van de volgorde 
Opmerking 1. Het bovenstaande bewijs toont in feite aan dat de sterke wet van grote aantallen geldt, zelfs als men slechts paarsgewijze onafhankelijkheid van de 

Opmerking 2. Het is essentieel dat de willekeurige variabelen 

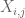
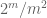
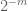



opmerking 3. Vanuit het perspectief van de interpolatietheorie kan men het bovenstaande argument als een interpolatieargument beschouwen, waarbij een 


Opmerking 4. Door de opeenvolging