låt X vara en realvärderad slumpmässig variabel och låt 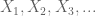
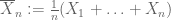
svag lag av stort antal. Antag att det första ögonblicket
av X är ändligt. Sedan konvergerar
med sannolikhet till
, alltså
för varje
.
stark lag av stort antal. Antag att det första ögonblicket
.
(om man förstärker det första momentets antagande till det andra momentets slutlighet 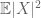
den svaga lagen är lätt att bevisa, men den starka lagen (som naturligtvis innebär den svaga lagen, genom Egoroffs sats) är mer subtil, och i själva verket visas beviset på denna lag (förutsatt att det första ögonblicket är slut) oftast bara i avancerade examenstexter. Så jag trodde att jag skulle presentera ett bevis här på båda lagarna, som fortsätter med standardteknikerna för momentmetoden och trunkering. Tyngdpunkten i denna utställning kommer att ligga på motivation och metoder snarare än korthet och styrka av resultat; det finns bevis på den starka lagen i litteraturen som har komprimerats ner till storleken på en sida eller mindre, men detta är inte mitt mål här.
— momentmetoden —
momentmetoden syftar till att kontrollera svansannolikheterna för en slumpmässig variabel (dvs. sannolikheten att den fluktuerar långt från medelvärdet) med hjälp av ögonblick, och i synnerhet nollpunkten, första eller andra ögonblicket. Anledningen till att denna metod är så effektiv är att de första ögonblicken ofta kan beräknas ganska exakt. Metoden för första ögonblicket använder vanligtvis Markovs ojämlikhet
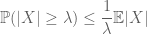
(vilket följer genom att ta förväntningar på den punktvisa ojämlikheten 

(Observera att (2) bara (1) tillämpas på den slumpmässiga variabeln ).
generellt sett använder man vanligtvis linjäritet i förväntan för att beräkna det första ögonblicket

för att beräkna det andra ögonblicket måste man också förstå kovarianser (som är särskilt enkla om man antar parvis oberoende) tack vare identiteter som
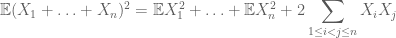
eller den normaliserade varianten
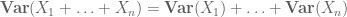

högre moment kan i princip ge mer exakt information, men kräver ofta starkare antaganden om de objekt som studeras, såsom gemensamt oberoende.
här är en grundläggande tillämpning av första ögonblicket metoden:
Borel-Cantelli lemma. Låt
vara en sekvens av händelser så att
är ändlig. Då är nästan säkert bara ändligt många av händelserna
sanna.
bevis. Låt 


låta 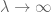

återgå till lagen om stora tal, det första ögonblicket metoden ger följande svans bunden:
Lemma 1. (Första stundens svans bunden) Om
är ändlig, då
.
bevis. Av triangeln ojämlikhet, 

Lemma 1 är inte tillräckligt stark för att bevisa lagen om stora tal i antingen svag eller stark form – i synnerhet visar det ingen förbättring eftersom n blir stor – men det kommer att vara användbart att hantera ett av felvillkoren i dessa bevis.
vi kan få starkare gränser än Lemma 1 – i synnerhet gränser som förbättras med n – på bekostnad av starkare antaganden om X.
Lemma 2. (Second moment tail bound) om
.
bevis. En standardberäkning, som utnyttjar (3) och parvis oberoende av 



i motsatt riktning finns zeroth moment-metoden, mer allmänt känd som union bound

eller likvärdigt (för att förklara terminologin ”zeroth moment”)

för alla icke-negativa slumpmässiga variabler 
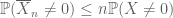
precis som det andra momentet bundet (Lemma 2) bara är användbart när man har god kontroll på det andra momentet (eller variansen) av X, är zeroth moment tail estimate(3) bara användbart när vi har god kontroll på zeroth moment 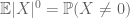
det andra ögonblicket svansbundet (Lemma 2) ger redan den svaga lagen om stora tal i fallet när X har ändligt andra ögonblick (eller ekvivalent, ändlig varians). I allmänhet, om allt man vet om X är att det har ändligt första ögonblick, kan vi inte dra slutsatsen att X har ändligt andra ögonblick. Vi kan dock utföra en trunkering
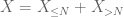
n, där 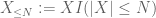

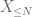
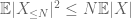
och därför har vi också ändlig varians
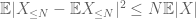
den andra termen 
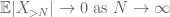
med triangeln ojämlikhet drar vi slutsatsen att den första termen
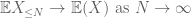
dessa är alla verktyg vi behöver för att bevisa den svaga lagen i stora tal:
bevis på svag lag. Låta 

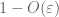
från (7), (8) kan vi hitta ett tröskelvärde N (beroende på 
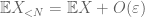

från det första ögonblicket svansbundet (Lemma 1) vet vi att 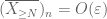
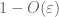
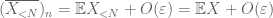
— den starka lagen –
den starka lagen kan bevisas genom att trycka på ovanstående metoder lite längre och använda några fler knep.
det första tricket är att observera att för att bevisa den starka lagen är det tillräckligt att göra det för icke-negativa slumpmässiga variabler 

när X är icke-negativ ser vi att de empiriska medelvärdena

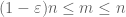
på grund av denna kvasimonotonicitet kan vi sparsifiera uppsättningen n för vilken vi behöver bevisa den starka lagen. Mer exakt räcker det att visa
stark lag med stort antal, reducerad version. Låt
vara en icke-negativ slumpvariabel med
och låt
vara en sekvens av heltal som är lakunär i den meningen att
för vissa
och alla tillräckligt stora j. sedan
konvergerar nästan säkert till
faktum är att om vi kunde bevisa den reducerade versionen, då på att tillämpa den versionen till lacunary sekvensen 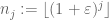


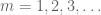
nu när vi har sparsifierat sekvensen blir det ekonomiskt att tillämpa Borel-Cantelli lemma. Faktum är att genom många tillämpningar av den lemma ser vi att det räcker att visa att

för icke-negativ X av ändligt första ögonblick, någon lakunär sekvens 
vid denna tidpunkt går vi tillbaka och tillämpar de metoder som redan arbetat för att ge den svaga lagen. För att uppskatta var och en av svansannolikheterna 
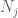
vi bör åtminstone välja 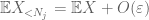


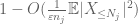

nu tittar vi på bidraget från 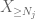
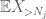
men det finns ett sista kort att spela, vilket är zeroth moment method tail estimate (4). Som tidigare nämnts är denna gräns elak i allmänhet-men är mycket bra när X är mestadels noll, vilket är just situationen med 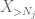


att sätta ihop allt detta ser vi att

Sammanfattningsvis detta i j ser vi att vi kommer att göras så snart vi räknar ut hur man väljer
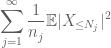
och
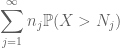
båda är ändliga. (Som vanligt har vi en avvägning: att göra
baserat på diskussionen tidigare är det naturligt att försöka ställa in 

och
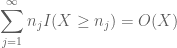
(där den underförstådda konstanten här beror på sekvensen 
anmärkning 1. Ovanstående bevis visar faktiskt att den starka lagen om stort antal gäller även om man bara antar parvis oberoende av 

Anmärkning 2. Det är viktigt att de slumpmässiga variablerna 

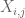
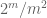
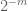



Anmärkning 3. Ur interpoleringsteorins perspektiv kan man se ovanstående argument som ett interpoleringsargument och upprätta en 


anmärkning 4. Genom att se sekvensen